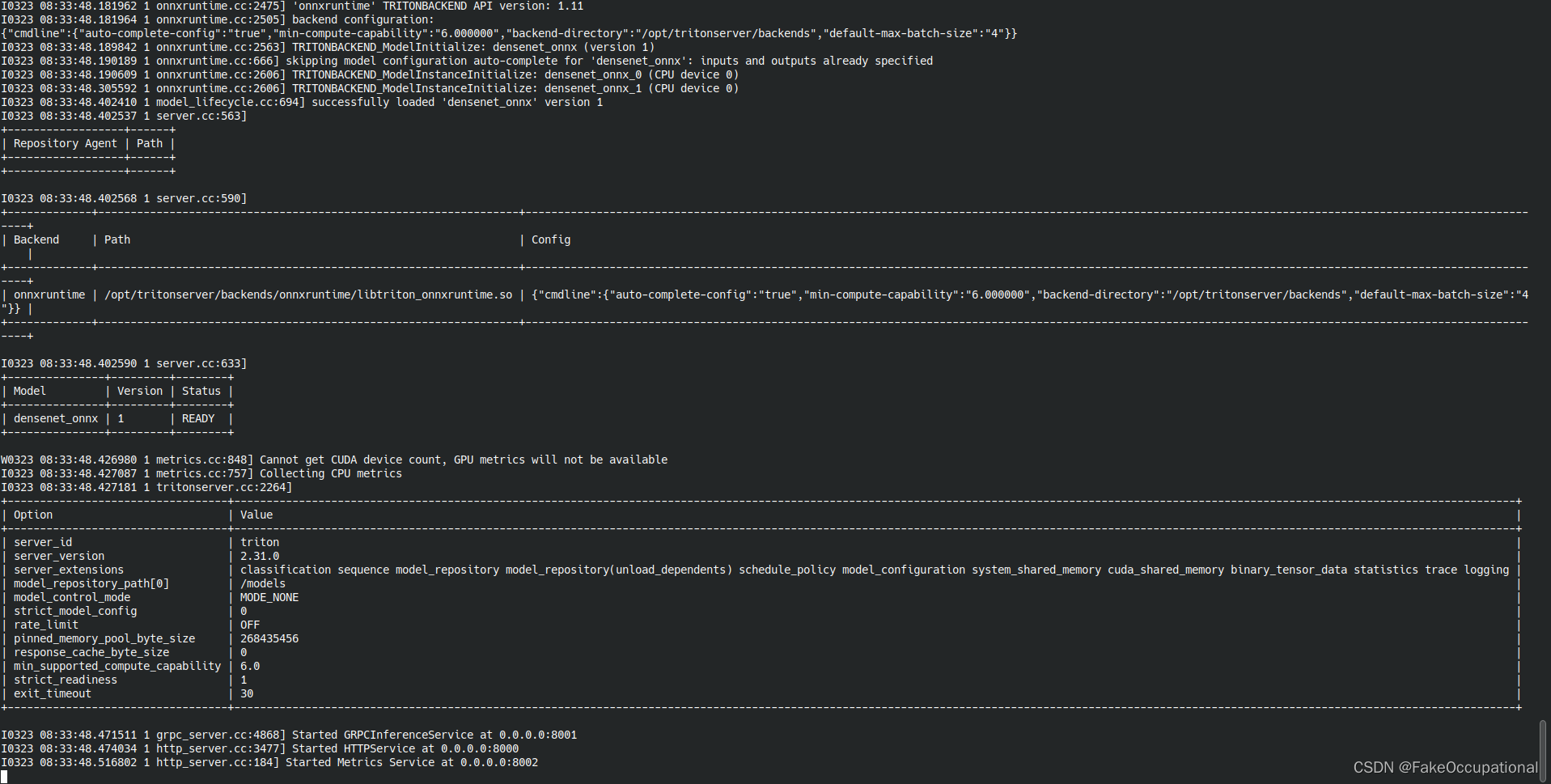
start up triton
服务端配置
-
./fetch_models.sh -
cd server/docs/examples -
docker run --gpus=1 --rm --net=host -v ${PWD}/model_repository:/models nvcr.io/nvidia/tritonserver:23.02-py3 tritonserver --model-repository=/models -
docker run --gpus=1 --rm --net=host -p8000:8000 -p8001:8001 -p8002:8002 -v ${PWD}/model_repository:/models nvcr.io/nvidia/tritonserver:23.02-py3 tritonserver --model-repository=/models
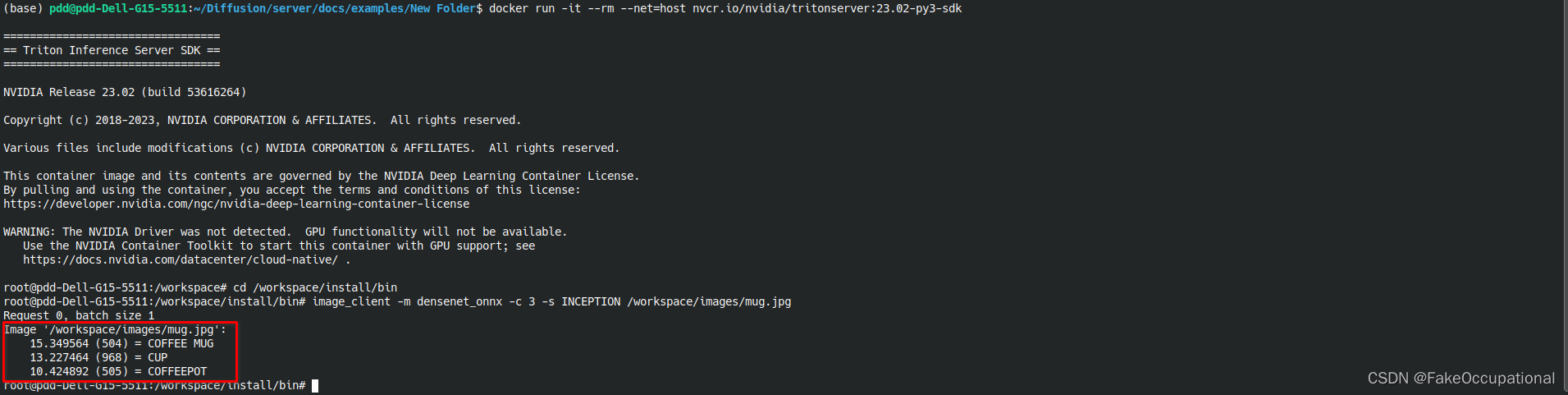
请求端配置
docker run -it --rm --net=host nvcr.io/nvidia/tritonserver:23.02-py3-sdkcd /workspace/install/binimage_client -m densenet_onnx -c 3 -s INCEPTION /workspace/images/mug.jpg
model_repository简单介绍
$ tree ${PWD}/model_repository
/home/pdd/Diffusion/server/docs/examples/model_repository
└── densenet_onnx
├── 1(version Directory)
│ └── model.onnx(存放模型或者源文件)
├── config.pbtxt(模型配置文件)
├── densenet_labels.txt(标签文件,对于分类模型可自动转换结果到标签)
└── model_repository
模型或者源文件
| 后缀 | |
|---|---|
| TensorRT | .plan |
| ONNX | .onnx |
| TorchScripts | .pt |
| TensorFlow | .graphdef ,.savedmodel |
| Python | .py |
| DALI | .dali |
| OpenVINO | .xml , .bin |
| Custom | .so |
模型配置
name: "fc_model_pt" # 模型名,也是目录名
platform: "pytorch_libtorch" # 模型对应的平台,本次使用的是torch,不同格式的对应的平台可以在官方文档找到
max_batch_size : 64 # 一次送入模型的最大bsz,防止oom
input [
{
name: "input__0" # 输入名字,对于torch来说名字于代码的名字不需要对应,但必须是<name>__<index>的形式,注意是2个下划线,写错就报错
data_type: TYPE_INT64 # 类型,torch.long对应的就是int64,不同语言的tensor类型与triton类型的对应关系可以在官方文档找到
dims: [ -1 ] # -1 代表是可变维度,虽然输入是二维的,但是默认第一个是bsz,所以只需要写后面的维度就行(无法理解的操作,如果是[-1,-1]调用模型就报错)
}
]
output [
{
name: "output__0" # 命名规范同输入
data_type: TYPE_FP32
dims: [ -1, -1, 4 ]
},
{
name: "output__1"
data_type: TYPE_FP32
dims: [ -1, -1, 8 ]
}
]
- [这个模型配置文件估计是整个triton最复杂的地方,上线模型的大部分工作估计都在写配置文件,](https://zhuanlan.zhihu.com/p/516017726)
(base) pdd@pdd-Dell-G15-5511:~/Diffusion/server/docs/examples$ tree ${PWD}/model_repository
/home/pdd/Diffusion/server/docs/examples/model_repository
├── densenet_onnx
│ ├── 1
│ │ └── model.onnx
│ ├── config.pbtxt
│ ├── densenet_labels.txt
│ └── model_repository
├── inception_graphdef
│ ├── 1
│ │ └── model.graphdef
│ ├── config.pbtxt
│ └── inception_labels.txt
├── simple
│ ├── 1
│ │ └── model.graphdef
│ └── config.pbtxt
├── simple_dyna_sequence
│ ├── 1
│ │ └── model.graphdef
│ └── config.pbtxt
├── simple_identity
│ ├── 1
│ │ └── model.savedmodel
│ │ └── saved_model.pb
│ └── config.pbtxt
├── simple_int8
│ ├── 1
│ │ └── model.graphdef
│ └── config.pbtxt
├── simple_sequence
│ ├── 1
│ │ └── model.graphdef
│ └── config.pbtxt
└── simple_string
├── 1
│ └── model.graphdef
└── config.pbtxt
18 directories, 18 files
Error实验时的错误与解决
Error:Unable to destroy DCGM group: Setting not configured
- 按照官方指示操作,出现了以下错误,解决方案,将模型集合中的其他模型资源先移出集合,防止triton对其解析造成的错误
$ docker run --gpus=1 --rm --net=host -v ${PWD}/model_repository:/models nvcr.io/nvidia/tritonserver:23.02-py3 tritonserver --model-repository=/models
Unable to find image 'nvcr.io/nvidia/tritonserver:23.02-py3' locally
23.02-py3: Pulling from nvidia/tritonserver b549f31133a9: Pull complete
=============================
== Triton Inference Server ==
=============================
I0323 04:51:12.372561 1 server.cc:590]
+-------------+-----------------------------------------------------------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Backend | Path | Config |
+-------------+-----------------------------------------------------------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------+
| onnxruntime | /opt/tritonserver/backends/onnxruntime/libtriton_onnxruntime.so | {"cmdline":{"auto-complete-config":"true","min-compute-capability":"6.000000","backend-directory":"/opt/tritonserver/backends","default-max-batch-size":"4"}} |
| tensorflow | /opt/tritonserver/backends/tensorflow2/libtriton_tensorflow2.so | {"cmdline":{"auto-complete-config":"true","min-compute-capability":"6.000000","backend-directory":"/opt/tritonserver/backends","default-max-batch-size":"4"}} |
+-------------+-----------------------------------------------------------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------+
I0323 04:51:12.372618 1 server.cc:633]
+----------------------+---------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Model | Version | Status |
+----------------------+---------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| densenet_onnx | 1 | READY |
| inception_graphdef | 1 | UNAVAILABLE: Internal: cudaGetDevice() failed. Status: CUDA driver version is insufficient for CUDA runtime version |
| simple | 1 | UNAVAILABLE: Internal: cudaGetDevice() failed. Status: CUDA driver version is insufficient for CUDA runtime version |
| simple_dyna_sequence | 1 | UNAVAILABLE: Internal: cudaGetDevice() failed. Status: CUDA driver version is insufficient for CUDA runtime version |
| simple_identity | 1 | UNAVAILABLE: Internal: unable to auto-complete model configuration for 'simple_identity', failed to load model: cudaGetDevice() failed. Status: CUDA driver version is insufficient for CUDA runtime version |
| simple_int8 | 1 | UNAVAILABLE: Internal: cudaGetDevice() failed. Status: CUDA driver version is insufficient for CUDA runtime version |
| simple_sequence | 1 | UNAVAILABLE: Internal: cudaGetDevice() failed. Status: CUDA driver version is insufficient for CUDA runtime version |
| simple_string | 1 | UNAVAILABLE: Internal: cudaGetDevice() failed. Status: CUDA driver version is insufficient for CUDA runtime version |
+----------------------+---------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
W0323 04:51:12.488232 1 metrics.cc:848] Cannot get CUDA device count, GPU metrics will not be available
I0323 04:51:12.493861 1 metrics.cc:757] Collecting CPU metrics
I0323 04:51:12.493988 1 tritonserver.cc:2264]
+----------------------------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Option | Value |
+----------------------------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| server_id | triton |
| server_version | 2.31.0 |
| server_extensions | classification sequence model_repository model_repository(unload_dependents) schedule_policy model_configuration system_shared_memory cuda_shared_memory binary_tensor_data statistics trace logging |
| model_repository_path[0] | /models |
| model_control_mode | MODE_NONE |
| strict_model_config | 0 |
| rate_limit | OFF |
| pinned_memory_pool_byte_size | 268435456 |
| response_cache_byte_size | 0 |
| min_supported_compute_capability | 6.0 |
| strict_readiness | 1 |
| exit_timeout | 30 |
+----------------------------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
I0323 04:51:12.493993 1 server.cc:264] Waiting for in-flight requests to complete.
I0323 04:51:12.494000 1 server.cc:280] Timeout 30: Found 0 model versions that have in-flight inferences
I0323 04:51:12.494026 1 server.cc:295] All models are stopped, unloading models
I0323 04:51:12.494031 1 server.cc:302] Timeout 30: Found 1 live models and 0 in-flight non-inference requests
I0323 04:51:12.496973 1 onnxruntime.cc:2640] TRITONBACKEND_ModelInstanceFinalize: delete instance state
I0323 04:51:12.509553 1 onnxruntime.cc:2640] TRITONBACKEND_ModelInstanceFinalize: delete instance state
I0323 04:51:12.515835 1 onnxruntime.cc:2586] TRITONBACKEND_ModelFinalize: delete model state
I0323 04:51:12.515881 1 model_lifecycle.cc:579] successfully unloaded 'densenet_onnx' version 1
I0323 04:51:13.494168 1 server.cc:302] Timeout 29: Found 0 live models and 0 in-flight non-inference requests
error: creating server: Internal - failed to load all models
W0323 04:51:15.494565 1 metrics.cc:240] Unable to destroy DCGM group: Setting not configured
相关学习资源
官方文档 https://docs.nvidia.com/deeplearning/triton-inference-server/user-guide/docs/index.html
其它
-
https://docs.nvidia.com/deeplearning/sdk/inference-release-notes/index.html
-
Get the ready-to-deploy container with monthly updates from the NGC container registry
-
Open source GitHub repository : https://github.com/NVIDIA/triton-inference-server
open source examples of triton
- https://github.com/NVIDIA/DeepLearningExamples
- https://github.com/NVIDIA/DeepLearningExamples/tree/master/PyTorch/Classification/ConvNets/triton
- https://github.com/NVIDIA/DeepLearningExamples/tree/master/PyTorch/Classification/ConvNets/triton/resnet50
- https://github.com/NVIDIA/DeepLearningExamples/tree/master/PyTorch/Classification/ConvNets/resnext101-32x4d
- https://github.com/NVIDIA/DeepLearningExamples/tree/master/PyTorch/LanguageModeling/BERT/triton
- https://github.com/NVIDIA/DeepLearningExamples/tree/master/PyTorch/SpeechRecognition/Jasper/triton
- https://github.com/NVIDIA/DeepLearningExamples/tree/master/PyTorch/SpeechSynthesis/Tacotron2
- https://github.com/NVIDIA/DeepLearningExamples/tree/master/PyTorch/SpeechSynthesis/Tacotron2/trtis_cpp
- https://github.com/NVIDIA/DeepLearningExamples/tree/master/PyTorch/Recommendation/DLRM/triton
Triton Features & Overview:
- Simplifying and Scaling Inference Serving with NVIDIA Triton 2.3
- Simplifying AI Inference in Production with NVIDIA Triton
- NVIDIA Triton Inference Server Boosts Deep Learning Inference
Model Analyzer
ASR
Video Inferencing
NLP
CG
- git Git Clone错误解决:GnuTLS recv error (-110): The TLS connection was non-properly terminated.
- 通过curl命令验证Triton服务是否正常运行
curl -v localhost:8000/v2/health/ready - 海卫:海王星有两个卫星. 大一点的卫星叫TRITON, 仅仅略大于地球的卫星.
- https://blog.csdn.net/ResumeProject/article/details/127162169
-
- https://github.com/NVIDIA/TensorRT
- https://github.com/huggingface/diffusers
- 现有几种搭建框架
Python:TF+Flask+Funicorn+Nginx
FrameWork:TF serving,TorchServe,ONNX Runtime
Intel:OpenVINO,mms,NVNN,QNNPACK(FB的)
NVIDIA:TensorRT Inference Server(Triton),DeepStream
————————————————
版权声明:本文为CSDN博主「ooMelloo」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/Aidam_Bo/article/details/112791627