Redis面试经典问题
14)redis锁如何保证任何时刻有且只有一个线程持有这个锁?
基础
1)Redis中的基本数据类型、应用场景以及它们的底层
Redis中有五种基本的数据类型分别是string、list、set、zset、hash
应用场景:string我们常用的是缓存,list可以存放集合的数据,也可以用于队列;set可以用于数据去重;zset是有序的集合可以用于排行榜,hast可以存储对象数据。初次还可以用于计数器、秒杀利用Redis中的原子性(INCR、DECR),分布式系统的session管理等
底层:动态字符串,ziplist,quicklist,hash 跳表
String的底层是动态字符串,类似于Java中的ArrayList,可以预分配冗余空间以及扩容,注意String的最大长度是512.
list的底层是一个双向链表,头部尾部都可以存储数据。数据结构quickList,当列表元素较少是会分配一块连续的内存空间ziplist,数据较多是会变成quickList。多个ziplist组成一个quickList
Set底层是一个value为null的hash表
ZSet底层hast表和跳表。hash表关联元素value和权重score,跳表给value排序。
hash底层的数据结构是ziplist和hashtabel
2)高并发下缓存带来的问题,缓存穿透,缓存击穿、缓存雪崩
缓存穿透:数据既不在缓存也不在数据库。
解决:可以对空值进行缓存;采用布隆过滤器
缓存击穿:某个热点数据过期,雪崩的子集
解决:设置不过期,预先将热点数据加载到缓存中,并发监控,实施调整
加互斥锁
缓存雪崩:大量缓存同一时刻失效,服务器挂掉
解决:使用多级缓存nginx缓存,本地缓存,redis缓存
将缓存的失效时间分散开,防止集体失效
3)Redis为什么那么快
20道经典Redis面试题_CSDN砖家的博客-CSDN博客_redis面试题
1.单线程+基于内存+采用了非阻塞多路复用机制
减少线程切换的时间与锁的竞争
CPU与内存速度差了多个数量级,天上一天地下一天
IO多路复用(epoll):多个网络连接、复用一个线程
2.高效的数据结构(动态字符串,ziplist,quickLIst,hast,跳表)利器
4)Redis事务
Redis中的事务是一组MULTI、EXEC、WATCH等一组命令集合,也就是说将一组命令封装成一个队里,其他命令不可以插队。顺序性,一次性,排他性。
- 开始事务(MULTI)
- 命令入队
- 执行事务(EXEC)、撤销事务(DISCARD )
5)redis的过期策略
过期策略:定时删除(单一),惰性删除(单一)、定期删除(部分)
redis采用的是定期删除+惰性删除策略。
6)过期策略以及内存淘汰机制的区别
当 Redis 的内存超过最大允许的内存之后,Redis 会触发内存淘汰策略,这和过期策略是完全不同的两个概念,经常有人把二者搞混,这两者一个是在正常情况下清除过期键,一个是在非正常情况下为了保证 Redis 顺利运行的保护策略。


volatile-lru:当内存不足以容纳新写入数据时,从设置了过期时间的key中使用LRU(最近最少使用)算法进行淘汰;
allkeys-lru:当内存不足以容纳新写入数据时,从所有key中使用LRU(最近最少使用)算法进行淘汰。
volatile-lfu:4.0版本新增,当内存不足以容纳新写入数据时,在过期的key中,使用LFU算法进行删除key。
allkeys-lfu:4.0版本新增,当内存不足以容纳新写入数据时,从所有key中使用LFU算法进行淘汰;
volatile-random:当内存不足以容纳新写入数据时,从设置了过期时间的key中,随机淘汰数据;。
allkeys-random:当内存不足以容纳新写入数据时,从所有key中随机淘汰数据。
volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的key中,根据过期时间进行淘汰,越早过期的优先被淘汰;
noeviction:默认策略,当内存不足以容纳新写入数据时,新写入操作会报错。
集群相关
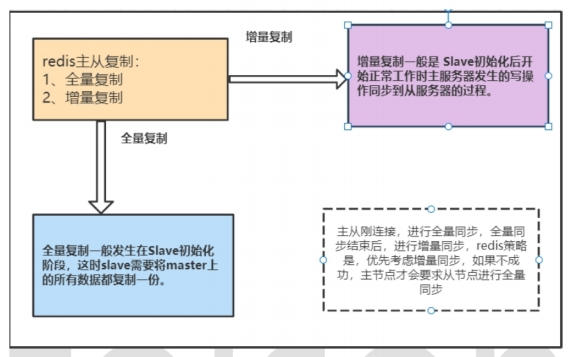
7)Redis主从复制的过程
1.一次全量赋值,多次增量赋值
2.一次slave主动,多次master主动
slave节点初次连接master节点,会发送psync命令并触发全量复制。
此时master节点fork一个后台进程,开始生成一份RDB快照,同时将那些从外面接收到的写命令缓存到缓冲区中。
RDB文件生成完毕后,将此文件发送给slave节点,slave先写入磁盘,再从磁盘加载到内存,
接着master会将新增加的缓冲区的写命令发送给slave,slave执行写命令并同步数据。
8)Redis主从、哨兵、集群各有什么不同
主从模式:需要手动进行故障转移,耗时长,可用性比较差,基本不推荐
哨兵模式:通过哨兵自动完成故障转移,但是存储数据比较冗余,利用率低不高,在线扩容
难,也不是太推荐
集群模式:继承哨兵模式的所有优点,支持在线扩容,数据分片。
通过数据分片,实现在线扩容,同时每个 master 节点支持可读可写,可以支持超高的并发,强烈推荐这种方案。 注意:不管使用哪种 redis 高可用方案,都不能保证数据不丢失。 因为三种方
案底层都是依赖的主从复制原理,而主从复制是采用的异步复制,而异步复制是肯定会丢数据的
9)redis主从节点是长连接还是短连接?
长连接
10)怎么判断redis某个节点是否正常工作
一般集群判断节点是否正常工作,常用的方法都是通过互相的ping-pong心跳检测机制,如果有一半以上的节点去ping一个节点的时候没pong回应,集群就会认为这个节点宕机,会断掉这个节点的连接。
redis主节点默认每隔10s发送一次心跳-一判断从节点是否在线。
redis从节点每隔1s发送一次心跳一给主节点发送自己的复制偏移量,从主节点获取到最新的数据变更命令,还做一件事情就是判断主节点是否在线。
11)过期key如何处理
主节点处理了一个key或者通过淘汰算法淘汰了一个key,这个时候主节点模拟一条del命令发送给从节点,从节点接收到命令删除key。
12)redis是同步复制还是异步复制
redis主节点每次接收到写命令之后,先写到内部的缓冲区,然后异步发送给从节点。
分布式锁
13)redis除了做缓存,还可以用来做什么?
答:时效性验证码,分布式锁、防重提交、分布式限流、简易版本的消息队列、延迟任务、session共享(
集成spring-session-data-redis)
14)redis锁如何保证任何时刻有且只有一个线程持有这个锁?
答:使用命令:setnx key value
key不存在时设置成功返回值ok,key存在设置失败,
也可以采用If(!redisUtil.get(key)set key value},不过这段代码需要采用Iua脚本实现来保证原子性。
15)如何保证分布式锁不产生死锁?
答:给锁设置一个合理的过期时间,业务执行过程中节点异常宕机,有个兜底终止跳出方案使用命令:setnx key value ex seconds设置key和对应的过期时间,到了指定的ex时间,锁自动释放。
16)如何防止释放别的线程锁?
使用UUID或者雪花算法
17)分布式锁选用redis与Zookeeper的区别
1、redis分布式锁(推荐)互联网项目并发量高,对性能要求高,比较推荐。
redis常见操作,例如基本类型string、hash、Iist、set等等操作可以采用jedis或lettuce。
对于跟分布式锁相关的操作集成redission。
2、分布式锁百分百可靠可以选用Zookeeper作为分布式锁。采用cap理论中的cp模型保证高可靠性。
一般的项目我们可以结合不同的场景,同时兼容两种分布锁的实现。
18)什么是 redis 热 key,以及解决方案
在 Redis 中,热 key 是指那些在极短的时间内访问频次非常高的 key
解决:
1、利用二级缓存
使用EhCache,是一个纯Java的进程内缓存框架
2、分布式缓存、读写分离
读写分离就是将同为 Write 的请求发送到 Master 模块内,而将 Read 的请求发送至 ReadOnly 模块。
Redis中热点Key是怎么产生的?如何解决?-Redis-PHP中文网
19)什么是 redis 大 key
通俗易懂的讲,大 Key就是某个key对应的value很大,占用的redis空间很大,本质上是大value问题。
Redis中什么是Big Key(大key)问题?如何解决Big Key问题?_每天都要进步一点点的博客-CSDN博客_redis 大key
解决:
在业务上对大Key进行拆分
设置过期时间,及时清理大key
重点要有大Key的分析工具
20)在1024这个日子,愿打工人早日找到心仪的工作
加油打工人