1 目的
本文提供相关视频和笔记,以便初学者快速入门Transformer注意力机制。
2 重要模块
2.1 基础公式
Transformer的常见基础公式为
A t t e n t i o n ( X ) = A t t e n t i o n ( Q = W q X , K = W k X , V = W v V ) = s o f t m a x ( Q K T d k ) V , \mathsf{Attention}(X) = \mathsf{Attention}(Q=W_qX, K=W_kX, V=W_vV) = \mathsf{softmax}(\frac{QK^T}{\sqrt{d_k}})V, Attention(X)=Attention(Q=WqX,K=WkX,V=WvV)=softmax(dkQKT)V,
其中, ( W q , W k , W v ) (W_q, W_k, W_v) (Wq,Wk,Wv)是权重矩阵,负责将 X X X映射为语义更深的特征向量 Q , K , V Q, K, V Q,K,V,而 d k d_k dk为特征向量长度。去掉softmax和缩放因子以及权重矩阵,有
A t t e n t i o n ( X ) = ( X X T ) X 。 \mathsf{Attention}(X) = (XX^T)X。 Attention(X)=(XXT)X。
画图表示,有
 即自己与自己对比得到注意力权重矩阵,然后根据注意力权重进行加权求和。
即自己与自己对比得到注意力权重矩阵,然后根据注意力权重进行加权求和。
在求注意力权重矩阵时,这里没有采用非线性激活函数,推测是为了减少计算量,可以通过实验探索是否在实际模型中加入非线性激活函数。
加入缩放因子 1 d k \frac{1}{\sqrt{d_k}} dk1是为了使训练变得稳定。考虑
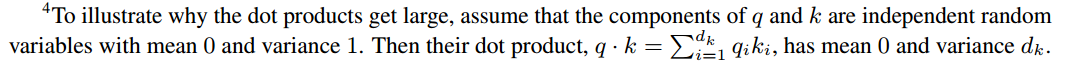
假如不加入缩放因子,学习是梯度会变得非常不稳定。
2.2 位置编码
对原本循环神经网络(Recurrent Neural Network,RNN)而言,存在健忘问题(即远距离信息被近距离信息阻挡),且无法并行计算。
相比之下,全连接神经网络可处理长距离输入,且能够并行计算,但输入没有位置信息。位置信息对处理序列具有重要作用,如:
句子A翻译成句子B。A中位置1与位置5的单词相同,即A(1)和A(5);B中位置0的单词B(0)对应A中的A(1)。看一遍A中所有单词,赋予A(1)较高权重,即B(0)的翻译由A(1)确定,而为了与A(5)区分开来,加入位置编码。
在自注意力机制中,可通过嵌入位置编码使相关度权重矩阵计算考虑到特征间的位置信息以及距离关系。
Transformer中位置编码的设计原理可参考答案:
如何理解Transformer论文中的positional encoding,和三角函数有什么关系? - 月球上的人的回答 - 知乎
https://www.zhihu.com/question/347678607/answer/1651324633
此处提供一种基本思路:
- 直接采用 i i i:假设 i i i值为1000,若嵌入特征的值域为 [ 0 , 0.01 ] [0, 0.01] [0,0.01],则此时嵌入特征值无异于 0 0 0,位置编码喧宾夺主;
- 将表示位置的特征向量的每一维度约束至范围 [ 0 , 1 ] [0, 1] [0,1];
- 采用 i / ( N − 1 ) i / (N - 1) i/(N−1):其中 N N N为序列长度,在长度为10与长度为100的序列中,位置1的位置编码表示不一样;
- 将 i i i转换为比特串:位置编码作为 d d d维向量,每一维度值为 0 0 0或 1 1 1,可行;

- 方法4中位置编码只能处理整数,为处理小数形式的位置编码(比如0.0001厘米和1厘米),考虑其他方式;
- 方法4中位置编码向量每一维度可用周期函数表示,选用正弦函数和余弦函数,通过缩放因子 ω \omega ω控制周期长度。
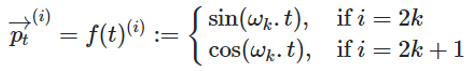
方法6种余弦函数和正弦函数两者并用原因:长度为 ( t + ϕ ) (t+\phi) (t+ϕ)的位置编码可以在长度为 t t t的位置编码基础上通过简单线性变换获得。
在图像分类任务中,若仅将位置编码嵌入最后一层特征层(大小为 7 × 7 × C 7 \times 7 \times C 7×7×C),则可考虑直接采用方法1或方法3。也可用相对位置编码取代绝对位置编码,参考论文
Prajit Ramachandran, et al. Stand-Alone Self-Attention in Vision Models. NIPS 2019.
3 视频资料
先看Attention机制是怎样处理RNN的健忘问题的,RNN模型与NLP应用(8/9):Attention (注意力机制)_哔哩哔哩_bilibili。
其实Self-Attention和Attention机制原理一样,只不过一个用于Encoder输入长度固定的场景,另一个用于Encoder输入为在线更新数据流的场景,RNN模型与NLP应用(9/9):Self-Attention (自注意力机制)_哔哩哔哩_bilibili。


看完上述2个视频,在此基础上考虑剥离RNN得到一个即插即用的注意力模块,Transformer模型(1/2): 剥离RNN,保留Attention_哔哩哔哩_bilibili。视频中多了一个 V V V向量,这里无关紧要,可以参考本文章节2.1,自己做笔记画图理解。再看完另一个视频,Transformer模型(2/2): 从Attention层到Transformer网络_哔哩哔哩_bilibili,即可从零开始设计Transformer。
留意,视频中Encoder只用到self-attention(输入只有 X X X,没有 X ′ X' X′);Decoder重点用attention,而用self-attention对第二个输入进行增强。

也可参考台大李宏毅21年机器学习课程 self-attention和transformer_哔哩哔哩_bilibili。
4 论文资料
2021年较火的一篇深度学习文章即
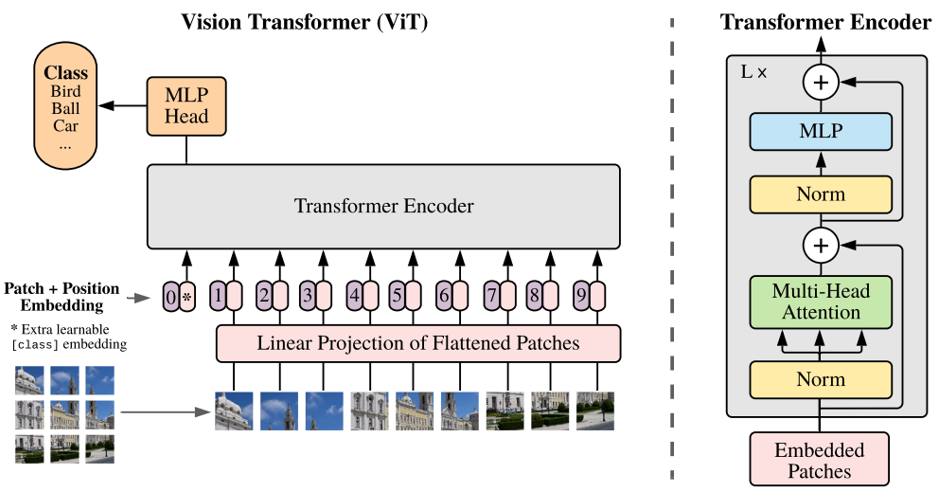
Alexey Dosovitskiy, et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. ICLR 2021.
将Transformer里的Encoder用到计算机视觉领域中。
其实,在此前有1篇思想类似的文章,即
Prajit Ramachandran, et al. Stand-Alone Self-Attention in Vision Models. NIPS 2019.
文章题目没有提及Transformer,而用到Self-Attention,个人感觉叫法比较直观(ViT文章采用Transformer和Attention写法容易让人引起误解)。具体可参考博文。

此处再推荐1篇博文:Transformer+self-attention超详解(亦个人心得)
附:ViT视频资料
这里推荐一个学习视频:VIT (Vision Transformer) 模型论文+代码从零详细解读,看不懂来打我。
个人感觉,ViT中的cls嵌入(即 0 ∥ ∗ 0 \| * 0∥∗符号)是没有必要的。此外,ViT跟Transformer的位置编码是不一样的(需要仔细读代码),跟Transformer不同,ViT用了一个可学习的position encoder来表示位置编码,没用到绝对编码数值或者相对编码数值。