一、介绍
本例子用Selenium +phantomjs爬取央视栏目(http://search.cctv.com/search.php?qtext=消费主张&type=video)的信息(标题,时间)
二、网站信息
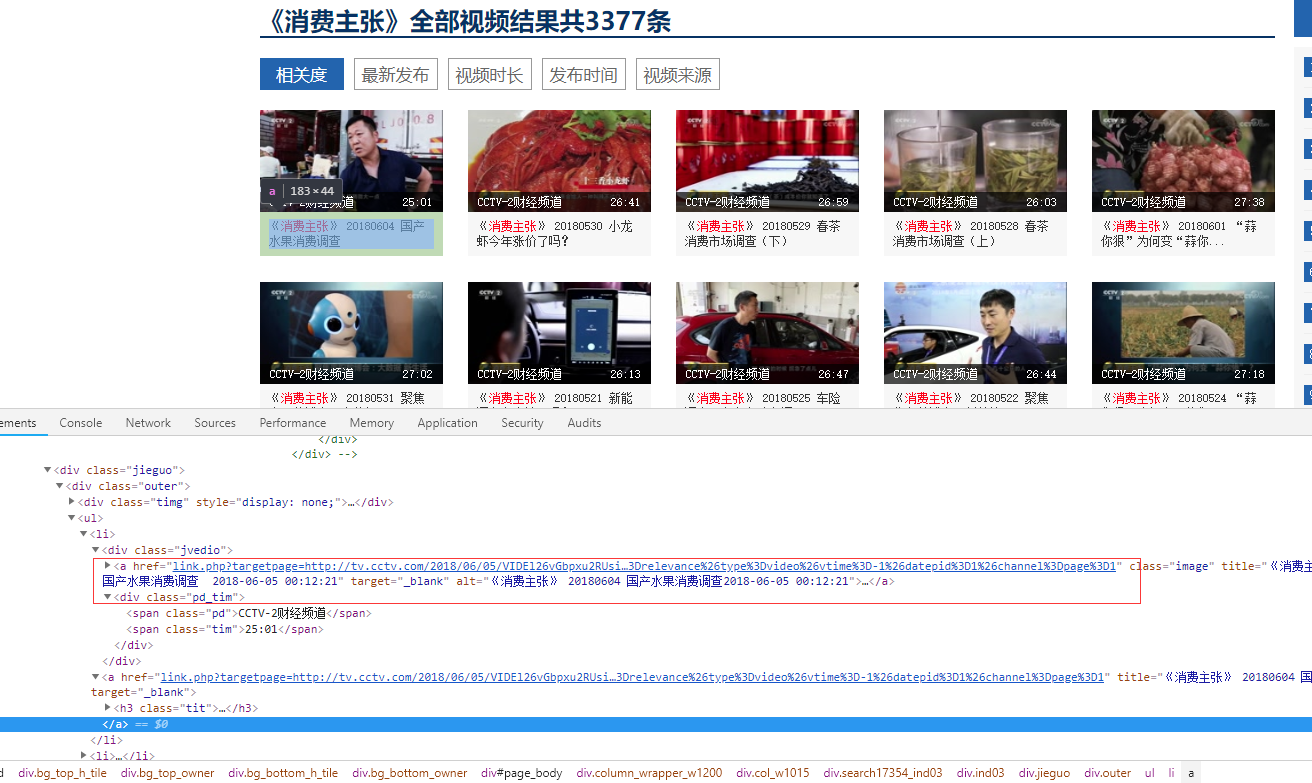
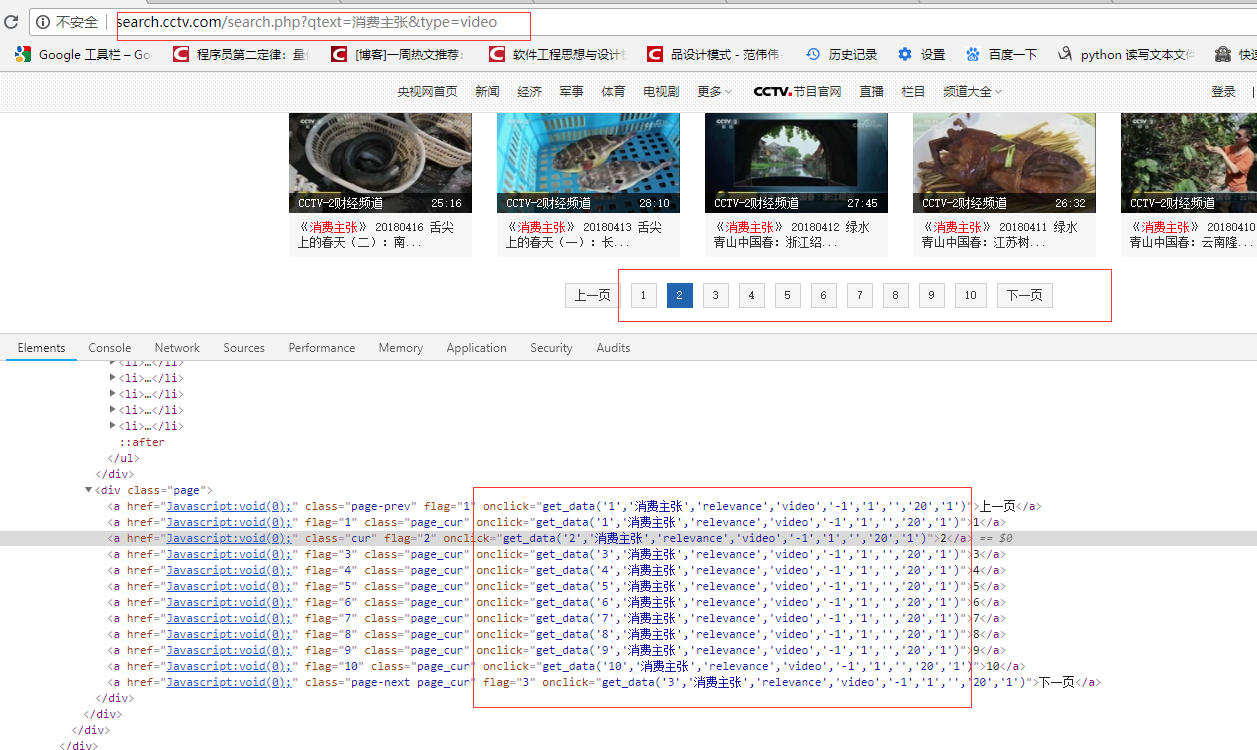
python 代码


# coding=utf-8 import os import re from selenium import webdriver from datetime import datetime,timedelta import time from pyquery import PyQuery as pq import re import mongoDB import datetime class consumer: def __init__(self): #通过配置文件获取IEDriverServer.exe路径 # IEDriverServer ='C:\Program Files\Internet Explorer\IEDriverServer.exe' # self.driver = webdriver.Ie(IEDriverServer) # self.driver.maximize_window() self.driver = webdriver.PhantomJS(service_args=['--load-images=false']) # self.driver = driver = webdriver.Chrome() self.driver.set_page_load_timeout(10) self.driver.maximize_window() self.db = mongoDB.mongoDbBase() def WriteLog(self, message,date): fileName = os.path.join(os.getcwd(), 'consumer/' + date + '.txt') with open(fileName, 'a') as f: f.write(message) # http://search.cctv.com/search.php?qtext=消费主张&type=video def CatchData(self,url='http://search.cctv.com/search.php?qtext=%E6%B6%88%E8%B4%B9%E4%B8%BB%E5%BC%A0&type=video'): error = '' try: self.driver.get(url) time.sleep(1) selenium_html = self.driver.execute_script("return document.documentElement.outerHTML") doc = pq(selenium_html) filename = datetime.datetime.now().strftime('%Y-%m-%d') message = '{0},{1}'.format( '标题', '时间') filename = datetime.datetime.now().strftime('%Y-%m-%d') self.WriteLog(message, filename) pages = doc("div[class='page']").find("a") # 2018-06-05 00:12:21 pattern = re.compile("\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}:\d{2}") for index in range(1,6): url = "get_data('{0}', '消费主张', 'relevance', 'video', '-1', '1', '', '20', '1')".format(index) self.driver.execute_script(url) selenium_html = self.driver.execute_script("return document.documentElement.outerHTML") doc = pq(selenium_html) Elements = doc("div[class='jvedio']").find("a") for sub in Elements.items(): title = sub.attr('title').encode('utf8') ts = pattern.findall(title) strtime = '' if ts and len(ts) == 1: strtime = ts[0] if strtime: index = title.index(strtime) title = title[0:index] title = '\n{0},{1}'.format(title,strtime) self.WriteLog(title, filename) except Exception, e1: error = e1.message # def CatchData(self,url='http://search.cctv.com/search.php?qtext=%E6%B6%88%E8%B4%B9%E4%B8%BB%E5%BC%A0&type=video'): # error = '' # try: # self.driver.get(url) # time.sleep(1) # selenium_html = self.driver.execute_script("return document.documentElement.outerHTML") # doc = pq(selenium_html) # # filename = datetime.datetime.now().strftime('%Y-%m-%d') # # pages = doc("div[class='page']").find("a") # # for element in pages.items(): # url = element.attr('onclick').encode('utf8') # # get_data('1','消费主张','relevance','video','-1','1','','20','1') # # get_data('2', '消费主张', 'relevance', 'video', '-1', '1', '', '20', '1') # print url # self.driver.execute_script(url) # selenium_html = self.driver.execute_script("return document.documentElement.outerHTML") # doc = pq(selenium_html) # # Elements = doc("div[class='jvedio']").find("a") # for sub in Elements.items(): # title = sub.attr('title').encode('utf8') # print title # title = '\n{0}'.format(title) # self.WriteLog(title, filename) # except Exception, e1: # error = e1.message obj = consumer() obj.CatchData() # obj.CatchContent('') # obj.export('')