一、Rcode
library(vcd) #描述分析画图所需要的vcd包
library(pROC) #画ROC曲线和计算AUC所用到的pROC包
setwd("C:\\data") #设置工作路径
dat0 <- read.csv("auto.csv") #读取车险数据,命名成dat0
summary(dat0) #dat0的描述统计量
n <- dim(dat0)[1] #样本量
### 发现dat0中存在大量的因变量Loss=0的样本点,不适宜直接建立线性回归模型
### 以是否出险为因变量建立逻辑回归模型
### 在dat0中定义新的变量LossClass,判断是否出险,0表示未出险,1表示出险
dat0$LossClass[dat0$Loss == 0] <- 0
dat0$LossClass[dat0$Loss > 0] <- 1
### 描述性分析 ###
## 因变量:出险样本和未出险样本所占百分比
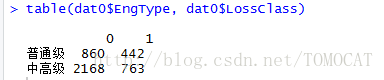
100*table(dat0$LossClass)/n
## 因素1-1:汽车车龄,车龄为1的占很大比例,而且车龄为1的出险率和车龄>1的出险率区别明显
table(dat0$vAge)
barplot(by(dat0$LossClass,dat0$vAge,mean), xlab="车龄", ylab="出险率")
# 不妨将车龄这个变量转换成离散型变量,取值为:1表示新车(车龄1年),0表示旧车(车龄1年以上)
dat0$vAgeNew[dat0$vAge == 1] <- 1
dat0$vAgeNew[dat0$vAge > 1] <- 0
dat0$vAgeNew <- factor(dat0$vAgeNew, levels=c(0,1), labels=c("旧车","新车"))
# 新生成的车龄变量分布
table(dat0$vAgeNew)
## 因素1-2:发动机引擎大小,在各个水平分布非常不均匀
table(dat0$EngSize)
# 考虑对发动机引擎离散化,依据是目前国内轿车级别的分类标准:1.0-1.6升为普通级车,1.6以上为中高级车
dat0$EngType[dat0$EngSize <= 1.6] <- 0
dat0$EngType[dat0$EngSize > 1.6] <- 1
dat0$EngType <- factor(dat0$EngType, levels=c(0,1), labels=c("普通级","中高级"))
# 新生成的车辆级别变量分布
table(dat0$EngType)
## 画1*2图,分别是车龄 vs. 出险,引擎 vs. 出险
par(mfrow=c(1,2))
countvAgeNew <- table(dat0$vAgeNew, dat0$LossClass)
spineplot(countvAgeNew, main="车龄", col=c("gold","grey"),yaxlabels=c("未出险","出险"))
countEngType <- table(dat0$EngType, dat0$LossClass)
spineplot(countEngType, main="车辆级别(按引擎大小分)", col=c("gold","grey"),yaxlabels=c("未出险","出险"))
## 因素1-3:有无防盗装置
countAntiTFD <- table(dat0$AntiTFD, dat0$LossClass)
## 因素1-4:有无固定停车位
countGarage <- table(dat0$Garage, dat0$LossClass)
## 因素1-5:是否进口车
countImport <- table(dat0$import, dat0$LossClass)
## 因素1-6:所有者性质(公司、政府、私人)
countOwner <- table(dat0$Owner, dat0$LossClass)
## 画2*2图,分别是因素1-3到1-6的四组对比箱线图
par(mfrow=c(2,2))
spineplot(countAntiTFD, main="有无防盗装置", col=c("gold","grey"),yaxlabels=c("未出险","出险"))
spineplot(countGarage,main="有无固定停车位", col=c("gold","grey"),yaxlabels=c("未出险","出险"))
spineplot(countImport,main="是否进口车", col=c("gold","grey"),yaxlabels=c("未出险","出险"))
spineplot(countOwner,main="所有者性质", col=c("gold","grey"),yaxlabels=c("未出险","出险"))
par(mfrow=c(1,2))
## 因素2-1:年龄
boxplot(Age ~ LossClass, data=dat0, main="年龄", col= c("gold","grey"),names=c("未出险","出险"))
## 因素2-2:驾龄
boxplot(exp ~ LossClass, data=dat0, main="驾龄", col= c("gold","grey"),names=c("未出险","出险"))
## 因素2-3:性别
countGender <- table(dat0$Gender,dat0$LossClass)
spineplot(countGender, main="驾驶员性别", col=c("gold","grey"),yaxlabels=c("未出险","出险"))
## 因素2-4:婚姻状况
countMarital <- table(dat0$Marital, dat0$LossClass)
spineplot(countMarital, main="婚姻状况", col=c("gold","grey"),yaxlabels=c("未出险","出险"))
### 建模 ###
## 0-1回归模型glm.full(车龄和引擎作了离散化处理)
glm.full <- glm(LossClass ~ EngType + vAgeNew + AntiTFD + Garage + import + Owner + Age + exp + Gender + Marital, family=binomial(link="logit"),data=dat0)
## 空模型,不包含任何变量
glm.null <- glm(LossClass~1,family=binomial(link="logit"),data=dat0)
## 全模型的显著性检验
anova(glm.null,glm.full,test="LRT")
## 回归结果
summary(glm.full)
## AIC准则和BIC准则模型显著性检验和估计结果
glm.aic <- step(glm.full,trace=F)
anova(glm.null,glm.aic,test="LRT")
summary(glm.aic)
glm.bic <- step(glm.full,k=log(n),trace=F)
anova(glm.null,glm.bic,test="LRT")
summary(glm.bic)
## 画三个模型的ROC曲线并计算AUC值
pred.full <- glm.full$fitted.values #全模型预测值(出险概率)
roc.full <- roc(dat0$LossClass,pred.full) #全模型ROC曲线取值
pred.aic <- glm.aic$fitted.values #AIC模型预测值(出险概率)
roc.aic <- roc(dat0$LossClass,pred.aic) #AIC模型ROC曲线取值
pred.bic <- glm.bic$fitted.values #BIC模型预测值(出险概率)
roc.bic <- roc(dat0$LossClass,pred.bic) #BIC模型ROC曲线取值
## 画三个模型的ROC曲线
par(mfrow=c(1,1))
plot(roc.full,lty=1,main="三个模型的ROC曲线对比",lwd=3)
plot(roc.aic,add=T,col="red",lty=2,lwd=3)
plot(roc.bic,add=T,col="blue",lty=3,lwd=3)
legend(0.2,0.2,c("Full","AIC","BIC"),col=c("black","red","blue"),lty=1:3,lwd=3)
## 最终选择AIC模型,在ROC曲线上标注AUC值和最佳阈值
par(mfrow=c(1,1))
plot(roc.aic,print.auc=T,print.auc.x=0.4,print.auc.y=0.4,print.thres=T,
print.auc.cex=1.5,print.thres.cex=1.5,main="AIC模型的ROC曲线")
## 混淆矩阵
thres <- 0.318 #最佳阈值
table(dat0$LossClass,1*(pred.aic>thres)) #混淆矩阵
## 商业应用部分,按照AIC模型出险概率划分人群,计算实际出险率
temp <- cbind(dat0$LossClass,pred.aic) #实际出险 & 预测出险概率
temp <- temp[order(pred.aic,decreasing=T),] #按照模型预测概率从高到低排序
mylab <- c(rep(1:5,each=840),rep(5,33)) #平均分成5组,打标签
temp <- cbind(temp,mylab) #实际出险 & 预测出险概率 & 分组标签
res <- by(temp[,1],temp[,3],mean) #每组的实际出险率
r <- barplot(res,col=heat.colors(5,alpha=0.6),ylim=c(0,0.5),ylab="出险率",xlab="人群划分")
text(r,res-0.03,paste(round(100*res,0),"%",sep=""),col="darkblue",cex=1.3)
abline(h=mean(temp[,1]),lwd=2,lty=2)
text(5,0.3,"平均出险率=28%",cex=1.3)
二、重点补充
1、table的双变量用法和spineplot
countvAgeNew <- table(dat0$vAgeNew, dat0$LossClass)
spineplot(countvAgeNew, main="车龄", col=c("gold","grey"),yaxlabels=c("未出险","出险"))
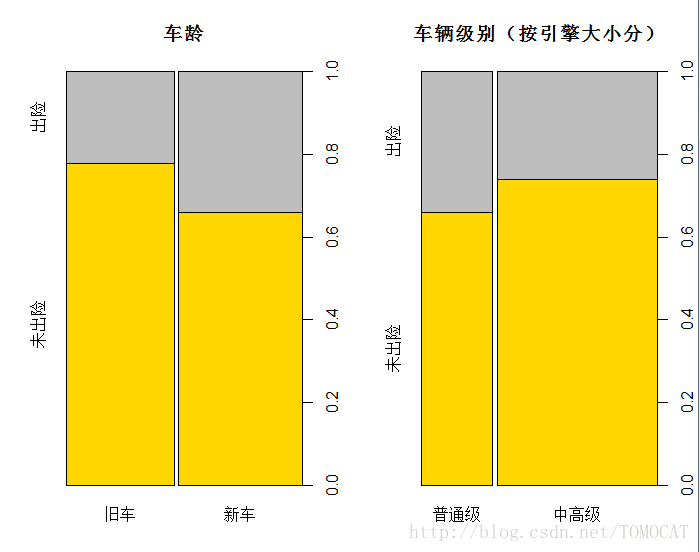
棘状图对堆砌条形图进行了重缩放,从而每个条形的高度为1,每一段的高度表示比例,用于比较比例。
尤其这里用了双变量的table,可用于两个变量交互的比例比较。注意spineplot的对象是table。
3、逻辑回归模型的显著性检验
## 0-1回归模型glm.full(车龄和引擎作了离散化处理) glm.full <- glm(LossClass ~ EngType + vAgeNew + AntiTFD + Garage + import + Owner + Age + exp + Gender + Marital, family=binomial(link="logit"),data=dat0) ## 空模型,不包含任何变量 glm.null <- glm(LossClass~1,family=binomial(link="logit"),data=dat0) ## 全模型的显著性检验 anova(glm.null,glm.full,test="LRT")4、AIC、BIC和全模型的比较(利用ROC曲线和模型的复杂程度)
## 画三个模型的ROC曲线并计算AUC值
pred.full <- glm.full$fitted.values #全模型预测值(出险概率)
roc.full <- roc(dat0$LossClass,pred.full) #全模型ROC曲线取值
pred.aic <- glm.aic$fitted.values #AIC模型预测值(出险概率)
roc.aic <- roc(dat0$LossClass,pred.aic) #AIC模型ROC曲线取值
pred.bic <- glm.bic$fitted.values #BIC模型预测值(出险概率)
roc.bic <- roc(dat0$LossClass,pred.bic) #BIC模型ROC曲线取值
## 画三个模型的ROC曲线
par(mfrow=c(1,1))
plot(roc.full,lty=1,main="三个模型的ROC曲线对比",lwd=3)
plot(roc.aic,add=T,col="red",lty=2,lwd=3)
plot(roc.bic,add=T,col="blue",lty=3,lwd=3)
legend(0.2,0.2,c("Full","AIC","BIC"),col=c("black","red","blue"),lty=1:3,lwd=3)
## 最终选择AIC模型,在ROC曲线上标注AUC值和最佳阈值
par(mfrow=c(1,1))
plot(roc.aic,print.auc=T,print.auc.x=0.4,print.auc.y=0.4,print.thres=T,
print.auc.cex=1.5,print.thres.cex=1.5,main="AIC模型的ROC曲线")
## 混淆矩阵
thres <- 0.318 #最佳阈值
table(dat0$LossClass,1*(pred.aic>thres)) #混淆矩阵(1)先弄清楚几个概念:
概念 1: TPR(True Positive Rate): TPR=TP/P, TPR 表示的是“抓住坏蛋的概率”,在本案例中表示的是:成功预测出出险的概率。
概念 2: FPR(False Positive Rate): FPR=FP/N, FPR 表示的是“冤枉好人”的概率,本案例中表示的是:错把未出险预测为出险的概率。
概念 3: ROC 曲线(Receiver Operating Characteristic Curve):其横坐标为Specificity,即 1-FPR,纵坐标为 Sensitivity,即 TPR。 ROC 曲线是一条向上凸起的曲线。
概念 4: AUC(Area Under Curve): ROC 曲线下方的面积,反映的是模型的预测能力。 AUC 取值越大,模型的预测能力越强。
(2)接下来,分别绘制全模型、 AIC 模型和 BIC 模型的 ROC 曲线并进行比较。如图 4-1 所示,全模型和 AIC 模型的 ROC 曲线非常接近,而 BIC 模型的 ROC曲线相对而言比较靠下。经计算,全模型的 AUC 为 0.6253, AIC 模型的 AUC为 0.6241,BIC 模型的 AUC 为 0.6177。综合考虑模型的预测精度和模型的复杂程度后,本案例选择 AIC 模型作为出险因素模型。
5、最佳阈值
6、重点是商业应用部分