- 一个样本容量为N的样本,有放回的抽取N次,每次抽取1个,最终形成了N个样本。这选择好了的N个样本用来训练一个决策树,作为决策树根节点处的样本。这用了(a.)bagging的思想。
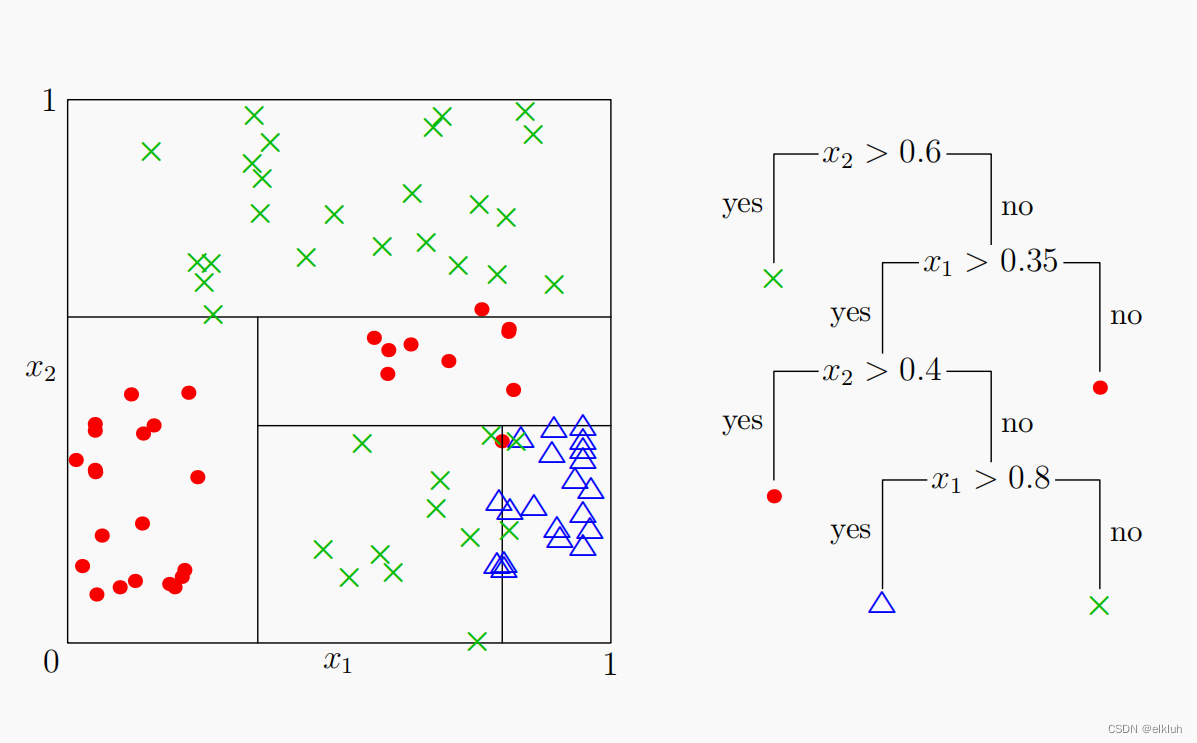
- 当每个样本有M个属性时,在决策树(c.)的每个节点需要分裂时,随机从这M个属性中选取出m个属性 (b.),满足条件m << M。然后从这m个属性中采用某种策略(比如说信息增益)来选择1个属性作为该节点的分裂属性。
- 决策树形成过程中每个节点都要按照步骤2来分裂(很容易理解,如果下一次该节点选出来的那一个属性是刚刚其父节点分裂时用过的属性,则该节点已经达到了叶子节点,无须继续分裂了)。一直到不能够再分裂为止。注意整个决策树形成过程中没有进行剪枝。
- 按照步骤1~3建立大量的决策树,这样就构成了随机森林了。
a. bagging : Bootstrap aggregating


•对于分类,我们让不同的机器投票
•对于回归,我们可以平均不同机器的预测
•bagging提高了决策树的性能
b. 上面的过程描述了树的原始的 bagging 算法。随机森林与这个通用的方案只有一点不同:它使用一种改进的学习算法,在学习过程中的每次候选分裂中选择特征的随机子集(减小相关性)。这个过程有时又被称为“特征 bagging”。这样做的原因是 bootstrap 抽样导致的树的相关性:如果有一些特征预测目标值的能力很强,那么这些特征就会被许多树所选择,这样就会导致树的强相关性
c. 决策树