
目录
0 实验目的:
设计、编制、实现并调试一个词法分析器,加深对词法分析的理解。
扫描二维码关注公众号,回复: 14701925 查看本文章
1 实验要求:
根据编译原理理论课所讲授的“单词的转换图”。如下图,编写识别单词的词法分析器,控制台输出识别出的每个单词。

2 实验内容:
1.待分析的简单的词法:
(1).关键字:
begin if then while do end 等等;
(2).运算法和界符:
:= + - * / < <= <> > >= = ; ( ) #
(3).其他单词是标识符(ID)和整型常数(SUM),通过以下正规式定义:
ID = letter(letter|digit)*
NUM = digit digit*
(4).空格有空白、制表符和换行符组成。空格一般用来分隔ID、SUM、运算符、界符和关键字,词法分析阶段常被忽略。
2.各种单词符号对应的种别码:
3.词法分析器的功能:
各种单词符号对应的种别码 单词符号 种别码 单词符号 种别码 begin 1 : 17 if 2 := 18 then 3 < 20 while 4 <> 21 do 5 <= 22 end 6 > 23 letter(letter|digit)* 10 >= 24 digit digit* 11 = 25 + 13 ; 26 - 14 ( 27 * 15 ) 28 / 16 # 0
输入:所给文法的源程序字符串。
输出:二元组(syn,token,sum)构成的序列。
其中:syn为单词种别码;
token为存放的单词自身字符串;
sum为整型常数。
例如:对源程序begin a:=9 if a>b then x:=2*a+1/3; end的源文件,经过词法分析后输出如下序列:
(1,begin)(10,x)(18,:=)(11,9)(26,;)(2,if)......
3 实验思路:
- 首先我们应该确认待分析的五类简单的单词字符(关键字,标识符,常数,运算符,界符)。同时,我们也要知道单词符号的种类值。
- 将整个程序分成五个部分:判断关键字函数,判断字母函数,判断数字函数,核心子程序(语法分析程序),主函数。
- 设一个token数组,接收控制台输入字符流,并送给语法分析程序。同时,设置一个存放关键字key的数组。语法分析程序读取每个字符并进行判断(字母或者下划线,符号,数字)
(1).如果是字母或者下划线,读取字符,直到下一个字符不是字母、下划线或者数字,将这一串字符保存到数组。进而与关键字数组比较,确定是关键字还是标识符。
(2).如果是数字,读取字符直到不是数字。
(3).如果是运算符或者界符,读取字符,并超前读取一位字符,先确定没有争议的字符,接着判断有争议的字符,如果判断异常,则输出对应的返回值。- 主函数调用核心子程序(语法分析程序),并按照(种别码,单词字符)的形式输出,结束程序。
4 实验代码:
#include <bits/stdc++.h>
using namespace std;
int isDigit();
int isAlpha();
int isKey();
void scan(int &attr, int &i, char s[],int &n);
char iskey[6][50] = {"if", "then", "begin", "while", "do", "end"};
char token[50];
//主函数
int main()
{
char s[100];
printf("请输入字符串(以#结尾)\n");
int flag=0;
while (scanf("%s", s))
{
if(strcmp(s, "#") == 0)
break;
int i = 0;
int n=1;
int attr;
if(flag==0)
{
printf("(种别码,单词属性)\n");
flag=1;
}
while (i <strlen(s))
{
scan(attr, i, s,n);
if(n==1)
printf("(%d,%s)\n", attr, token);
}
}
return 0;
}
int isAlpha(char ch)//判断是不是字母
{
if ((ch >= 'a' && ch <= 'z') || (ch >= 'A' && ch <= 'Z'))
return 1;
else
return 0;
}
int isKey(char s[])//判断关键字
{
for (int i = 0; i < 6; i++)
{
if (strcmp(s, iskey[i]) == 0)
{
return i + 1;
}
}
return -1;
}
int isDigit(char ch)//判断是不是数字
{
if (ch >= '0' && ch <= '9')
return 1;
else
return 0;
}
void scan(int &attr, int &i, char s[],int &n)//核心子程序(语法分析程序)
{
int temp = 0;
if (s[i] == ' ')
i++;
if (isAlpha(s[i]))//开头是字母
{
while (isDigit(s[i]) || isAlpha(s[i]))
{
token[temp++] = s[i];
i++;
}
token[temp] = '\0';
attr = isKey(token);
if (attr == -1)
{
attr = 10;
}
}
else if (isDigit(s[i]))//开头是数字
{
while (isDigit(s[i]))
{
token[temp++] = s[i];
i++;
}
token[temp] = '\0';
attr = 11;
}
else//如果是运算符或者界符
{
switch (s[i])
{
case '+':
attr = 13;
token[0] = s[i];
token[1] = '\0';
break;
case '-':
attr = 14;
token[0] = s[i];
token[1] = '\0';
break;
case '*':
attr = 15;
token[0] = s[i];
token[1] = '\0';
break;
case '/':
attr = 16;
token[0] = s[i];
token[1] = '\0';
break;
case '=':
attr = 25;
token[0] = s[i];
token[1] = '\0';
break;
case ';':
attr = 26;
token[0] = s[i];
token[1] = '\0';
break;
case '(':
attr = 27;
token[0] = s[i];
token[1] = '\0';
break;
case ')':
attr = 28;
token[0] = s[i];
token[1] = '\0';
break;
case '#':
attr = 0;
token[0] = s[i];
token[1] = '\0';
break;
}
if (s[i] == ':')
{
token[temp++] = s[i];
if (s[i + 1] == '=')
{
i++;
token[temp++] = s[i];
attr = 18;
}
else
{
attr = 17;
}
token[temp] = '\0';
}
if (s[i] == '<')
{
token[temp++] = s[i];
if (s[i + 1] == '>')
{
i++;
token[temp++] = s[i];
attr = 21;
}
else if (s[i + 1] == '=')
{
i++;
token[temp++] = s[i];
attr = 22;
}
else
{
attr = 20;
}
token[temp] = '\0';
}
if (s[i] == '>')
{
token[temp++] = s[i];
if (s[i + 1] == '=')
{
i++;
token[temp++] = s[i];
attr = 24;
}
else
{
attr = 23;
}
token[temp] = '\0';
}
i++;
}
}5 实验结果:
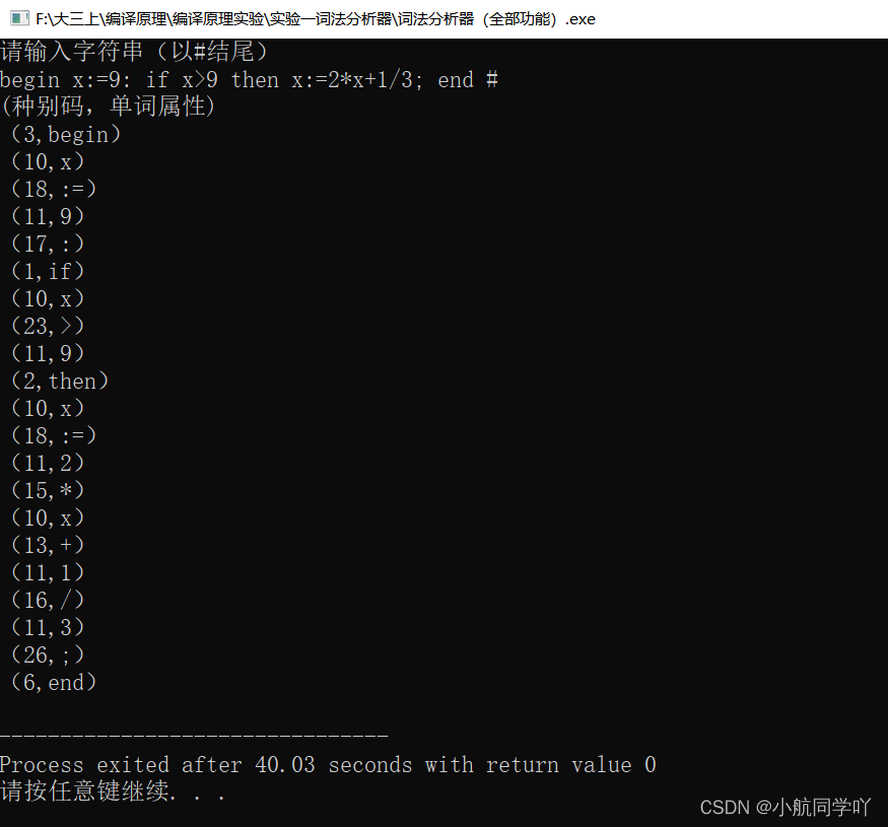
6 实验总结:
这个实验的要求不一样,如果你需要的不是这个,你可以稍微改一下,需要探讨的话可以与我私信。
7 实验程序以及实验报告下载链接:
