「昨天爬了情头,今天爬电影,本章带你体验一下如何爬取一部电影」
注:非盈利性东西,也请勿瞎玩。
电影地址,就不提供了,网上一大堆。
文章所涉及的库例如m3u8是需要pip下载的,不建议直接pip install ~ 因为下载不了(亲自尝试),我指定了源进行下载。
教程
老套路,抓包。
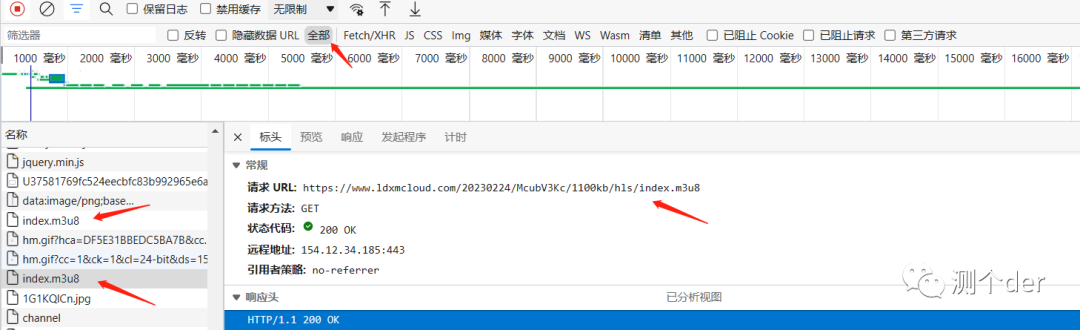 这里只涉及单个.m3u8链接。第一个m3u8包是个广告类的玩意,可以自行下载看。
这里只涉及单个.m3u8链接。第一个m3u8包是个广告类的玩意,可以自行下载看。
直接锁定第二个,Get请求,地址也拿到了。
解析m3u8,也就是发起请求看看
url = 'https://www.ldxmcloud.com/20230224/McubV3Kc/1100kb/hls/index.m3u8'
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36 Edg/111.0.1661.62'
}
reslut = requests.get(url=url,headers=headers)
reslut.encoding='utf-8'
print(reslut.text)这样就能获得一堆的.....ts的东西了,有的时候会有混淆的情况,比如这里就是.jpg文件,不过没事,点进去会重载到.ts。
「但是也要注意了,后缀是.jpg,后面我们需要改动一下」
然后我们使用正则匹配出全部的https://....jpg文件。
正则会吧,不会也不教了,自学吧。
res = re.findall('(https:.*jpg)',reslut.text)好,拿到全部的.jpg文件了。接下来又是发起请求了。
for value in res:
vodie = requests.get(url=value, headers=headers)
with open('report/' + value[-12:-4] + '.ts','ab+') as w:
w.write(vodie.content)
print("加载成功~",value)循环出每一个jpg文件,注意保存格式gaicheng.ts。写入用ab+,其他的没了,照常write就好。
这样就能在我的report下看到一个个ts文件了。
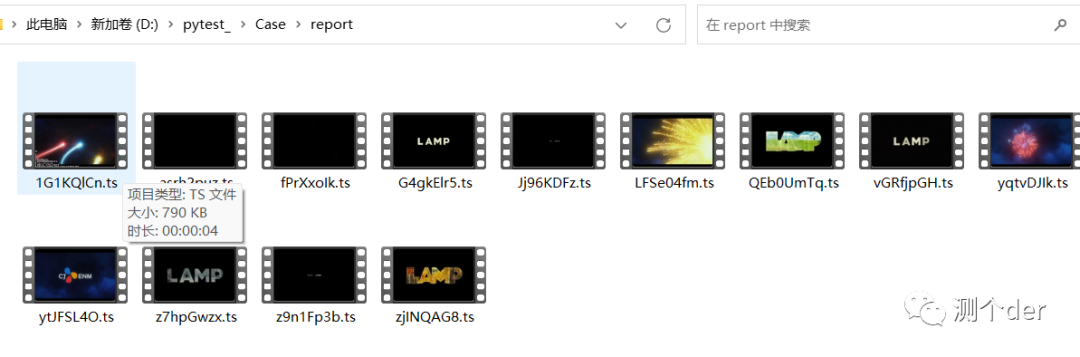
单线程有点慢,有时候请求会卡住,所以,可以关闭再跑一次。
「我这里没有请求完,只是一个示例,可以自行跑完尝试一下——————建议开多线程」
最后就是关键性的东西了,合并ts成一个MP4文件。百度一大堆,随便扒拉了一个。
from tqdm import tqdm
import os
path = 'report/'
files = os.listdir(path)
print(files)
for file in tqdm(files, desc="正在转换视频格式:"):
if os.path.exists(path + file):
with open(path + file, 'rb') as f1:
with open(path + "电影.mp4", 'ab') as f2:
f2.write(f1.read())
else:
print("失败")「tqdm这个可要可不要,就是个进度条的东西,需要第三方下载pip一下即可。」
跑完就能看到一个mp4文件,然后就能顺利播放了。
注意:这里的.m3u8是没有任何加密的东西的,很多电影其实时候加密的,需要解密,可以了解一下m3u8库。
最后:gitee地址~拿代码,单线程,封装好了的。 https://gitee.com/qinganan_admin/reptile-case/tree/master/%E7%94%B5%E5%BD%B1