sklearn函数:train_test_split(分割训练集和测试集)
x是array类型
from sklearn.model_selection import train_test_split
x_train,x_test = train_test_split(x)
xtrain
x_test- test_size:float or int, default=None
测试集的大小,如果是小数的话,值在(0,1)之间,表示测试集所占有的比例;
如果是整数,表示的是测试集的具体样本数;
如果train_size也是None的话,会有一个默认值0.25
上面的练习,就保持了默认,所以测试集就有3个样本了
- train_size:float or int, default=None
和test_size一样,同上
- random_state:int or RandomState instance, default=None
这个参数表示随机状态,因为每次分割都是随机的,我们重新执行几次上面的函数看看先
只有当shuffle=True时,random_state才起作用或者说才有意义,random_state随机取一个整数就好,保证每次分割出来的数据集是一样的。
shuffle: bool, default=True,默认是
是否重洗数据(洗牌),就是说在分割数据前,是否把数据打散重新排序这样子,看上面我们分割完的数据,都不是原始数据集的顺序,默认是要重洗的
x_train,x_test = train_test_split(x , train_size=4)
x_train
x_train,x_test = train_test_split(x , train_size=0.8)
x_train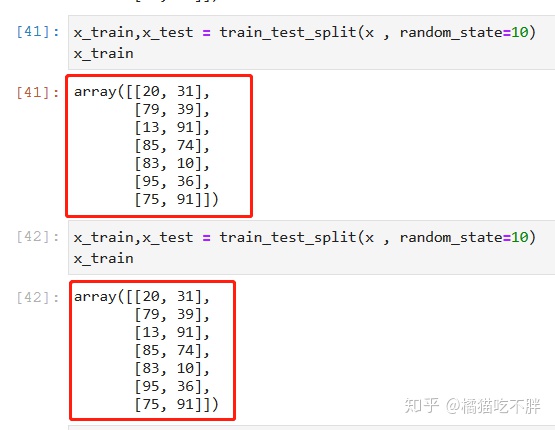

sklearn函数:KFold(分割训练集和测试集)
class
sklearn.model_selection.KFold(n_splits=5,*,shuffle=False,random_state=None)
- n_splits:int, default=5
表示,要分割为多少个K子集
- shuffle:bool, default=False
是否要洗牌(打乱数据)
- random_state:int or RandomState instance, default=None
这和前一篇中提到的随机状态是一样的,需要配合shuffle参数使用
这个参数表示随机状态,因为每次分割都是随机的,我们重新执行几次上面的函数看看先
只有当shuffle=True时,random_state才起作用或者说才有意义,random_state随机取一个整数就好,保证每次分割出来的数据集是一样的。
import numpy as np
from sklearn.model_selection import KFold
X = np.random.randint(1,100,20).reshape((10,2))
X
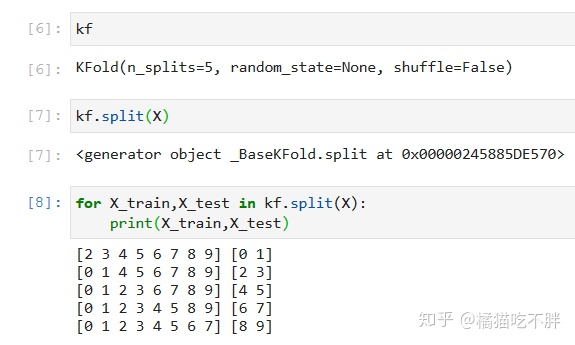
kf = KFold(n_splits=5)
kf
for X_train,X_test in kf.split(X):
print(X_train,X_test)
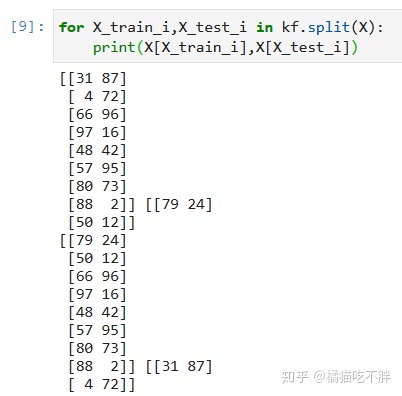
for X_train_i,X_test_i in kf.split(X):
print(X[X_train_i],X[X_test_i])