在指定的主字符串中搜索子字符串,
比如到主字符串"asrqqwex" 中搜索 子字符串"rqqw",
有常用的三种方法:
1.暴力搜索法
流程很简单,拿子字符串的第一个字符和主字符串的第一个字符串比较.
如果相同继续比较下一个字符.子字符串全部匹配的话就搜索到了.
如果到某一位字符不同,那么主字符串从第二个字符重新开始比较,重复上面的操作,以此类推.
如下:
asrqqwex

rqqw
asrqqwex
rqqw
asrqqwex
rqqw
这个方法唯一优点就是流程简单,容易理解,缺点就是效率很低 .主字符串长度n , 子字符串长度m,
那么时间复杂度就是 O(m*n).
代码如下:
int ViolentSearch(const char* pat, const char* txt)
{
int n = strlen(txt);
int m = strlen(pat);
for (int i = 0; i <= n - m; i++)//循环主串-子串+1次
{
int j;
for (j = 0; j < m; j++)//循环子串次
{
if (pat[j] != txt[i + j])
{
break;//任意一个不匹配 重新匹配
}
}
if (j == m) return i;//全部匹配返回位置
}
return -1;
}这种方法很容易理解,但是这样的效率很低.
2.KMP算法
暴力搜索法,相当于穷举,所以效率很低.
比如:子串中没有的字符, 主串中出现,就相当于截断,某一段的比较就没有意义了.
再比如:比较 "aaab" 和 "aaaaaaaab",
从第一个字符开始比较 ,比较到第四个字符 发现不同.
然后从第二个字符又开始重新比较已经对比过的234字节 ,显然这也是多余的.
那么就有了更优秀的KMP算法和BM算法sundy算法,来提高效率, 本质是空间换时间,提前创建一个记录子串信息的数组,来辅助我们更快的搜索字符串.
今天我们主要来研究一下, 这两种算法实现的思路,流程以及代码.
KMP算法的核心是一个叫做next的数组,
next数组只和子串有关,是通过子串计算出来的一个长度和子串相同的数组.来辅助我们更好的在主串中搜索子串.
先不要管算法.
我们来看一下next数组成员的含义.
3.next数组的计算
比如子串 char a[] = "abadxyzababmn";
计算next数组前,我们先来了解下什么是前后缀
前缀,就是从第一个字符开始,并且长度小于总字符串的子字符串
我们计算"n"前面的前缀
这里就是"a" "ab" "aba" "abad" "abadx" "abadxy" "abadxyz" ... "abadxyzabab" 没有"abadxyzababm" 因为他是n前面全部字符串了
后缀,就是从最后一个字符向前,并且长度小于总字符串的子字符串
这里就是 "m" "bm" "abm" "babm" "ababm" "zababm" ... "badxyzababm"没有"abadxyzababm" 因为他是n前面全部字符串了
很明显这里的前后缀没有相同的,我们计0
这里没有相同的,仅仅是n的位置计算的结果,不代表前面没有
比如取子串前面"abad"
我们计算"d"前面的前后缀
前缀就是"a" "ab"
后缀就是"a" "ba"
很明显有一个共同前后缀 "a" 长度是1 我们计1
好了,
了解了前后缀,我们可以直接看下next数组里是什么东西了
子串和next数组成员对应关系如下:
a b a d x y z a b a b m n
-1 0 0 1 0 0 0 0 1 2 3 2 0
找到我们刚才说的 n 和 d 是不是 对应的 0 和 1? 那么问题就很简单了
next[0] 固定是-1 其实是可以任意的小于0的特殊值,以表示比较要重新开始了.后面代码就知道了.
next[i] (比如 next[3])表示的是: 和他对应的字符串成员a[i] (这里是'd') 前的字符串(这里是"aba") 的 最长相等前后缀的长度(这里是1)。
是不是理解了next数组的含义
如果不懂.
我们说的通俗一点:next[i]表示的就是 a[i] 前面有几个连续的字符 和子串最前面的字符相同.并且是最长的.
看图

前面有一个字符 和子串最前面的字符相同, 所以是1

前面有三个字符 和子串最前面的字符相同, 所以是3
还是不懂?我们把例子说的更详细一些
这里next[10] 对应 a[10] 分别是 3 和 'b'

b前面 有"aba" 和子串最前面的字符相同.并且是最长的.所以 next[10] 是3

再次提醒注意,不能说b前面有"abadxyzaba" 和子串前面的"abadxyzaba"相同,不能等于前面的最大长度
否则这样的话next数组就没有意义了
任何子串的next数组就都是 结果都会是-1 1 2 3 4 5 6 7 8 .... 了,对吗?
如果你觉得懂了
我们来出几个题目,巩固一下
大家自己计算一下. 其实同学们已经发现了,next[0] = -1 next[1] = 0 这是必然的.
题目1:
a b a b c
-1 0 0 1 2
题目2:
a b a a a b b c a b c
-1 0 0 1 1 1 2 0 0 1 2
题目3:
a a a a a a a a b
-1 0 1 2 3 4 5 6 7
是不是会手动计算 next数组了?
那么我们用C++代码实现next数组的初始化
4.C++代码计算next数组
大家可能说从当前字符位置遍历前面所有的前缀和后缀,
然后计算出最大长度即可.
当然这是没问题,只不过这样效率较低.本身这个算法就是追求效率的,当然要避免穷举.
为了方便大家理解,用了部分中文变量,后面优化再改回来,谢谢理解.
void getNext(const char* t, vector<int>& next)
{
next[0] = -777;//设置一个小于0的特殊值
next[1] = 0;//固定的0
int i = 1;//每次为next数组赋值前,i++,所以是从第3个成员开始
int 匹配字符数 = 0;//初始化0 从第一位开始匹配
while (i < strlen(t) - 1)//循环次数 子串长度-2 因为前2个成员已经初始化完毕了
{
if (匹配字符数 == -777)//看完下面的代码 和 图1 图2 再看这里
//等于这个值,说明什么? 这个值只在next[0]中出现
//任鸟飞逆向
//说明刚才 匹配字符数 = next[匹配字符数] 赋值前的 匹配字符数为0. 这就是设置特殊值的意义.
//既然匹配值为0了,那么就要从头匹配了
{
++i;
匹配字符数 += 777;//从头匹配 初始化0 从第一位开始匹配
next[i] = 匹配字符数;//当前没有匹配到 写入0
}
if (t[i] == t[匹配字符数])//下面图1:匹配到 同时+1 继续匹配下一个 同时把当前匹配的数量写入next数组
{
++i;
++匹配字符数;
next[i] = 匹配字符数;
}
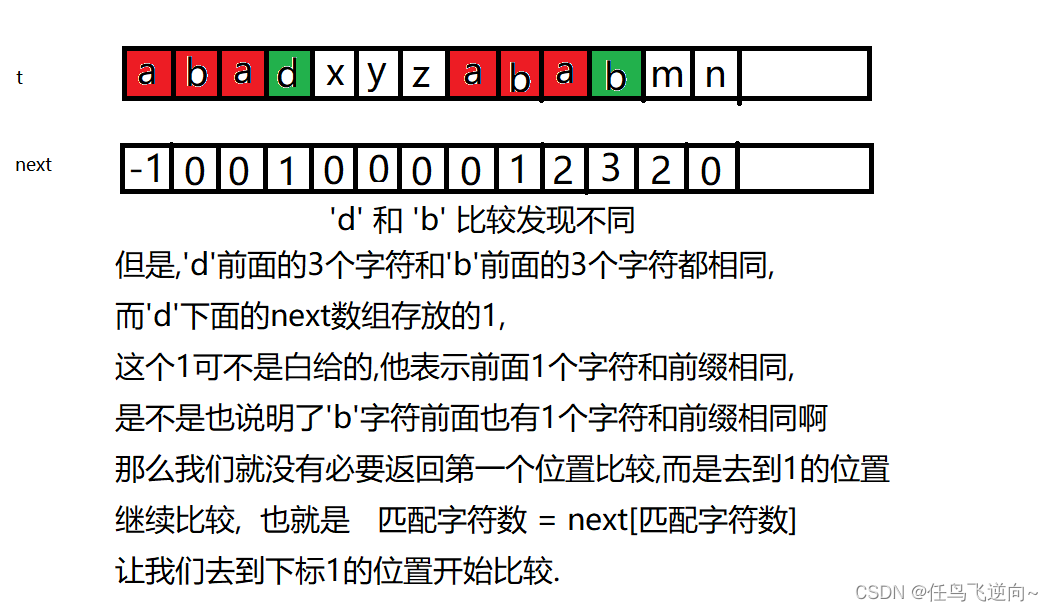
if (t[i] != t[匹配字符数])//下面图2:匹配不到是唯一的难点,下面会具体说明为什么是 匹配字符数 = next[匹配字符数];
{
匹配字符数 = next[匹配字符数];
}
}
}图1 : (红色代表匹配) 任何位置匹配到 同时+1 继续匹配下一个 同时把当前匹配的数量写入next[i+1]
如果继续匹配就是重复操作,继续写入 2,3,4,5...
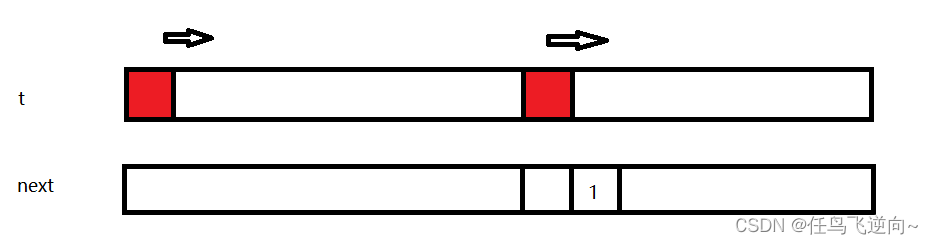
图2:匹配到一个位置不匹配了怎么处理?
我相信到了这里大家就彻底明白next数组的计算过程和方法了.
其实KMP算法在查找字符串的时候,用的逻辑跟这个是一模一样的.
如果你看到这里 ,恭喜你这个算法你已经掌握了百分之八十了.
代码最后优化
变成标准的最简洁的代码(当然上来就给你最简洁的代码, 相信很多人会迷糊)
void getNext(const char* pat,vector<int>& next)
{
next[0] = -1;
int i = 0, j = -1;
while (i < strlen(pat) - 1) {
if (j == -1 || pat[i] == pat[j]) {
++i;
++j;
next[i] = j;
}
else {
j = next[j];
}
}
}现在拿着标准KMP计算next数组的代码 再和我们自己写的代码进行比较,是不是就完全看懂了呢?
因为代码过于精简,直接看的话 确实有一些难懂.
5.KMP算法流程和代码
搞定了next数组的计算
我们来按照这个逻辑,手动搜索一次字符串.
举例 " a b a a b a b a b c a" 中搜索 "a b a b c"
"a b a b c"
的next数组很容易计算出来是
-1 0 0 1 2
看一下完整匹配流程:
a b a a b a b a b c a
a b a b c
-1 0 0 1 2
第四位不匹配 next数组里面是1 说明前面有一个字符和前缀相同
也就是说我们第一位不用比较了,从第二位开始和主串此时的第四位继续匹配就完事了
是不是跟计算next数组的时候一模一样啊
还是 j = next[j] 这就是kmp的核心思想.
我们移动子串方便观察
a b a a b a b a b c a
a b a b c
-1 0 0 1 2 0
第二位不匹配 里面是0 j = next[0] = -1
J = -1 要从头匹配 是不是也和next数组算法一样啊?
a b a a b a b a b c a
a b a b c
-1 0 0 1 2 0
第五位不匹配 里面是2 同理
a b a a b a b a b c a
a b a b c
-1 0 0 1 2 0
匹配成功 退出
任鸟飞逆向
我们发现KMP算法 不走回头路 ,不会重复扫描所以算法和next数组几乎可以说是一模一样的
我们可以把next数组算法中的前缀想象成比较的子串, next数组算法中的子串想象成主串
是不是就没啥区别了
那就不用多说了 直接代码:
int search(const char* pat, const char* text ,vector<int> next)
{
int i = 0;
int j = 0;
while (i < strlen(text))
{
if (j == -1 || text[i] == pat[j])
{
++i;
++j;
if (j == strlen(pat))
{
return i -j;
}
}
else
{
j = next[j];
}
}
}以上两种方法不是绝对的谁好谁不好
当子串和主串都不大的时候, 暴力搜索法反而很快.因为KMP需要做很多初始化和比较的处理
而随着主串和子串的增大,KMP有点越发明显,尤其像我们到4GB 这么大的内存中搜索特征码的时候
KMP算法的效率大约是 暴力搜索法的 特征码长度倍.
6.BM算法
BM算法也是一种高效的字符串匹配算法.
我觉得他的设计更简单对于定位特征码这种任务更高效.
首先他也是分两步
第一步生成一个坏字表,类似于KMP的next
第二步开始匹配搜索
我们看下他的坏字表是怎么生成的,有什么作用
在我们搜索的过程中,坏字表可以帮助我们判断子串中是否有这个字符,如果没有会直接跳过很大一段比较.
同时坏字表可以帮我们记录某个字符最后出现的位置.
不是很明白的话
我们直接看代码,非常简单:
void getBadCharTable(const char *pat, int len, int bc[256])
{
memset(bc, -1, sizeof(int) * 256);
for (int i = 0; i < len; i++)
{
bc[(unsigned char)pat[i]] = i;
}
}
所有元素初始值为-1 表示没有这个字符 . 而256 就是覆盖了 00- FF一个字节的所有字符,所以成员数量是256
然后 bc[(unsigned char)pattern[i]] = i; 什么意思呢?
就是把我们的字符串位置 写入到坏字表里. 如果重复出现就最后一次出现覆盖前面的.
来看个简单的例子
"bcdb"
坏字表中就应该是
-1 3 1 2 -1 -1 -1 -1 -1 -1 -1...
所以坏字表即记录了 是否有某个字符 又记录了 字符最后出现的位置.
int bm_search(const char *text, int n, const char *pat, int m)
{
int bc[260];
getBadCharTable(pat, m, bc);
int i = 0;
while (i <= n - m)
{
int j;
for (j = m - 1; j >= 0; j--)
{
if (text[i + j] != pat[j])
{
break;
}
}
if (j < 0)
{
return i;
}
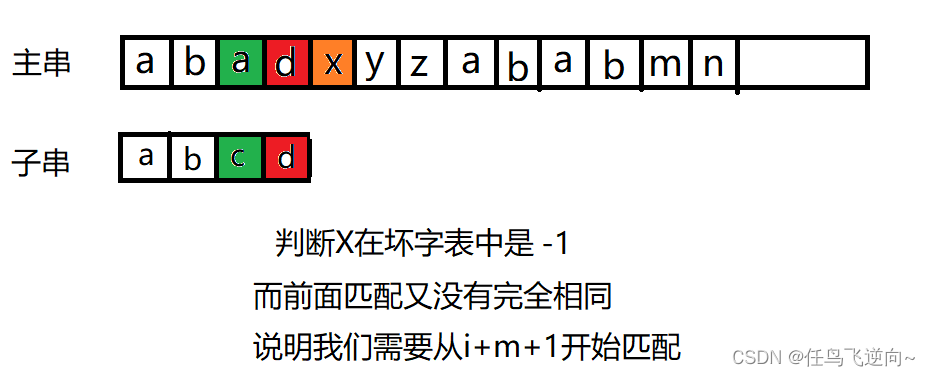
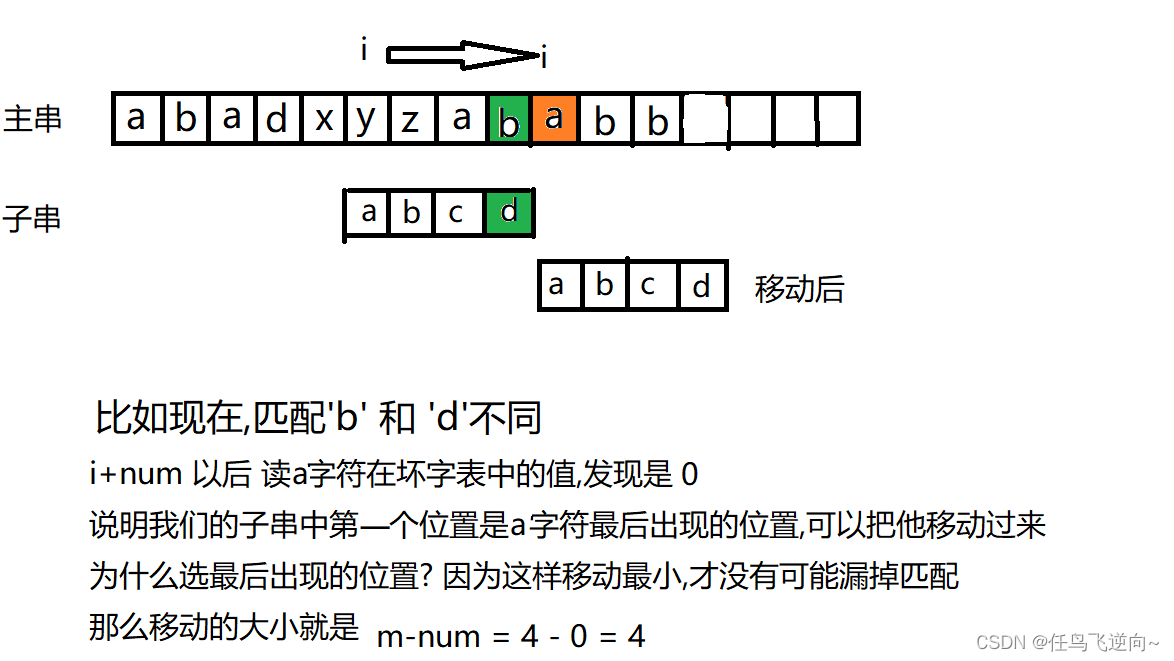
int num = bc[(unsigned char)text[i + m]];// 取下一段的第一个字符坏字表中的值
if (num == -1)//看图3 说明没有 没有就完全截断了 任鸟飞逆向 那么从i+m+1继续开始
i += (m - bc[256]);
else
i += (m - num);//看图4
}
return -1;
}大家会发现:
整体代码和暴力搜索差不多, 可以说是完全一样
只是把暴力搜索的
i++ 改成了
int num = bc[(unsigned char)text[i + m]];
if (num == -1)
i += (m - bc[256]);
else
i += (m - num);这个代码就是两种情况
图3:情况一
附加拓展:
这里int bc[260]; 而不是 int bc[256] i += (m - bc[256]); 而不是 i+= m +1
思考下为什么?
当bc[256]没有初始化的时候 就是-1 满足我们的条件
但是 当我们定义一个特殊字符为通配符的时候 他就可以跳到通配符的位置了.
比如子串长度10 我们本应该 i+10+1
但是现在通配符在5的位置出现

图4:情况二
好了这两种算法是不是彻底明白了呢?
7.编写特征码定位代码
好,算法都学会了,我们可以写个特征码定位的代码,来验证下学习成果了.
头文件:
#pragma once
class Scan
{
public:
LPCSTR className = nullptr;
LPCSTR title = nullptr;
HANDLE hHandle = 0;
uintptr_t beginAddr = 0;
uintptr_t endAddr = 0;
const char* sCode = nullptr;
uintptr_t sCodeAddr[50] = { 0 };
int number = 0;
Scan() {};
Scan(LPCSTR c, LPCSTR t, const char* tzm, uintptr_t begin, uintptr_t end) :className(c), title(t)
, sCode(tzm), beginAddr(begin), endAddr(end)
{
if (className == 0 && title == 0)
{
hHandle = GetCurrentProcess();
}
else
{
HWND hGame = ::FindWindowA(className, title);
if (hGame != NULL)
{
DWORD processId;
::GetWindowThreadProcessId(hGame, &processId);
hHandle = ::OpenProcess(PROCESS_ALL_ACCESS, false, processId);
}
}
};
void sTob();
//如果代码哪里出现问题 可以公众号 任鸟飞逆向 探讨交流
DWORD violentSearch();
DWORD kmpSearch();
DWORD bmSearch();
void scanCallAndBase(const char* vName, const char* hName, int offset, DWORD len, DWORD right);
void scanOffset(const char* vName, int hoffset, int offset, int size);
};
C++:
#include "pch.h"
#include "Scan.h"
#include<vector>
using namespace std;
WORD* tzm = 0;
int len = 0;
const DWORD pageSize = 409600;
BYTE page[409600];
void wprintf_scan(const wchar_t* pszFormat, ...)
{
wchar_t szbufFormat[0x10000];
wchar_t szbufFormat_Game[0x11000] = L"";
va_list argList;
va_start(argList, pszFormat);
vswprintf_s(szbufFormat, pszFormat, argList);
wcscat_s(szbufFormat_Game, L"任鸟飞 ");
wcscat_s(szbufFormat_Game, szbufFormat);
OutputDebugStringW(szbufFormat_Game);
va_end(argList);
}
void Scan::sTob()
{
len = (int)(strlen(sCode) / 3 + 1);
tzm = new WORD[len];
for (int i = 0; i < len; i++)
{
if (sCode[i * 3] == '?' && sCode[i * 3 + 1] == '?')
{
tzm[i] = 256;
}
else
{
char c[] = { sCode[i * 3], sCode[i * 3 + 1], '\0' };
tzm[i] = (BYTE)::strtol(c, NULL, 16);
}
}
}
DWORD Scan::violentSearch()
{
sTob();
uintptr_t scanAddr = beginAddr;
number = 0;
while (scanAddr <= endAddr - (DWORD)len)
{
::ReadProcessMemory(hHandle, (LPCVOID)scanAddr, &page, pageSize, 0);
for (int i = 0; i <= pageSize; i++)
{
int j;
for (j = 0; j < len; j++)
{
if (tzm[j] != page[i + j] && tzm[j] != 256)
{
break;
}
}
if (j == len)
{
//如果代码哪里出现问题 可以公众号 任鸟飞逆向 探讨交流
sCodeAddr[number] = scanAddr + i;
number++;
}
}
scanAddr += pageSize;
}
delete[] tzm;
tzm = 0;
return number;
}
void getNext(WORD* tzm,int len, vector<int>& next)
{
next[0] = -1;
int i = 0, j = -1;
while (i < len - 1)
{
if (j == -1 || tzm[i] == tzm[j])
{
++i;
++j;
next[i] = j;
}
else
{
j = next[j];
}
}
}
DWORD Scan::kmpSearch()
{
sTob();
vector<int> next(len);
getNext(tzm,len, next);
uintptr_t scanAddr = beginAddr;
number = 0;
while (scanAddr <= endAddr - (DWORD)len)
{
::ReadProcessMemory(hHandle, (LPCVOID)scanAddr, &page, pageSize, 0);
int i = 0;
int j = 0;
while (i < pageSize)
{
if (j == -1 || page[i] == tzm[j]|| tzm[j] == 256)
{
++i;
++j;
if (j == len)
{
sCodeAddr[number] = scanAddr + i - j;
number++;
j = next[j - (int)1];
}
}
else
{
j = next[j];
}
}
scanAddr += pageSize;
}
delete[] tzm;
tzm = 0;
return number;
}
short bc[260];
void getBadCharTable(WORD* mtzm, int mtzmLength)
{
memset(bc, -1, sizeof(short) * 260);
for (int i = 0; i < mtzmLength; i++)
{
bc[mtzm[i]] = i;
}
}
DWORD Scan::bmSearch()
{
sTob();
getBadCharTable(tzm,len);
uintptr_t scanAddr = beginAddr;
number = 0;
while (scanAddr <= endAddr - (DWORD)len)
{
::ReadProcessMemory(hHandle, (LPCVOID)scanAddr, &page, pageSize, 0);
int i = 0;
while (i <= pageSize)
{
int j;
for (j = len - 1; j >= 0; j--)
{
if (tzm[j] != page[i + j] && tzm[j] != 256)
{
break;
}
}
if (j < 0)
{
sCodeAddr[number] = scanAddr + i;
number++;
}
int num = bc[page[i + len]];
if (num == -1)
i += (len - bc[256]);
else
i += (len - num);
}
scanAddr += pageSize;
}
delete[] tzm;
tzm = 0;
return number;
}
8.比较三种的速度


结果是不是你没有想到的?
BM算法最快 暴力搜索法第二 而KMP反而最慢了
其实原因非常简单,是因为特征码中重复的字符特别的少, 此时KMP和暴力搜索没有什么区别了
然而KMP又进行了很多的处理,所以导致速度最慢
而扫描内存特征码出现没有的字符的概率极其大,所以BM就一骑绝尘了!
当然并没有什么方法是绝对好的
如果是正常英文文件,那么出现重复字符的可能会非常大,因为只有26个字母,此时KMP就很有优势了.
9.CQYH 课程中的数据我们做定位练习
BaseRole
scan.sCode = "E8 ?? ?? ?? ?? 90 48 8B 0D ?? ?? ?? ?? 48 85 C9 74 0D 48 8B 89 48 02 00 00";
scan.scanCallAndBase("BaseRole", "MMOGame-Win64-Shipping.exe", 6, 7, 0);BaseAroundTree
scan.sCode = "0D 00 FF FF FF FF C0 89 05";
scan.scanCallAndBase("BaseSkillAttackCounter", "MMOGame-Win64-Shipping.exe", 7, 6, 0);PacketCall
scan.sCode = "48 89 5C 24 10 48 89 74 24 18 57 48 83 EC 20 80 B9 68 01 00 00 00";
scan.bmSearch();
printf_AsmHook("#define PacketCall (uintptr_t)MMOGamehmodul + 0x%X",scan.sCodeAddr[0] - (uintptr_t)h);PacketCallRCX
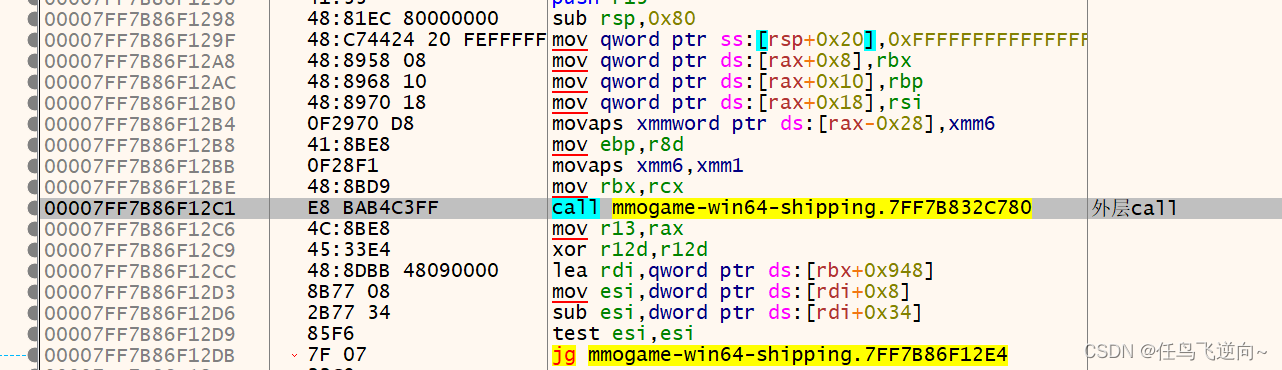
scan.sCode = "E8 ?? ?? ?? ?? 4C 8B E8 45 33 E4 48 8D BB 48 09 00 00 8B 77 08 2B 77 34";
scan.bmSearch();
uintptr_t PacketCallRCXAddr = scan.sCodeAddr[0] + 5 + *(int*)(scan.sCodeAddr[0] + 1);
uintptr_t packRCX = PacketCallRCXAddr + 7 + *(int*)(PacketCallRCXAddr + 3) - (uintptr_t)h;
printf_AsmHook("#define PacketCallRCX (uintptr_t)MMOGamehmodul + 0x%X", packRCX);这种周围没有特征码可以定位

我们只能返回外层定位,再根据call的偏移进来取
BaseAround
scan.sCode = "7E 41 41 B8 08 00 00 00 8B C8 E8 ?? ?? ?? ?? 48 83 3D";
scan.scanCallAndBase("BaseAround", "MMOGame-Win64-Shipping.exe", 0xF, 8, 1);BaseAroundTree
scan.sCode = "48 3B 1D ?? ?? ?? ?? E9 ?? ?? ?? ?? 48 8B 8F 5C 06 00 00";
scan.scanCallAndBase("BaseAroundTree", "MMOGame-Win64-Shipping.exe", 0, 7, 0);BasePackage_offset
scan.sCode = "73 74 0F B7 C2 45 0F B7 C0";
scan.bmSearch();
printf_AsmHook("#define BasePackage_offset 0x%X", *(DWORD*)(scan.sCodeAddr[0] + 0x11));BasePackage
scan.sCode = "90 8B 53 24 48 8D 0D";
scan.scanCallAndBase("BasePackage", "MMOGame-Win64-Shipping.exe", -0x18, 7, 0);BaseItemNameTree
scan.sCode = "41 8B 54 24 08 4C 8B 05";
scan.scanCallAndBase("BaseItemNameTree", "MMOGame-Win64-Shipping.exe", 5, 7, 0);BaseGroundItemTree
scan.sCode = "4C 8B 05 DF 07 78 01 4D 8B C8 4D 8B 00 48 8D 54 24 48";
scan.scanCallAndBase("BaseGroundItemTree", "MMOGame-Win64-Shipping.exe", 0, 7, 0);