一、归并排序
归并排序要额外多开一个数组用于存放归并后的数据,然后再把排序好的数据放回原数组。
归并排序使用递归的写法,大致分位两个步骤,一个是分解,一个是归并。而归并的数据必须是有序的才行,那么如何保证其最开始是有序的呢?
其实这里进入递归到了最底层,其数据被分为单一个数为一个区间的时候,这里就认为其是有序的。
分解会把数据分解为两个区间,然后做比较,如果是升序的话,一个个比较,把较小的放到临时数组。
此时此段区间就变为有序了,返回上一层这段区间就又可以用来被归并。

简单讲解归并流程,假设这里数组已经被分解为了两个有序的区间:
 这里就要依次进行比较然后把较小的数据放到临时数组。把数据放下去以后,i 往前走一步,然后再进行比较。
这里就要依次进行比较然后把较小的数据放到临时数组。把数据放下去以后,i 往前走一步,然后再进行比较。

这里2<4,把2放到下面的数组,然后 j 往前走一位。

依次走到最后数组数据就排序好了,但是这里要注意一个情况,这种比较的方法固定要有一个区间先走完,这里左区间先走完了,但是右区间还剩一个数,也没办法比较了。
所以为了防止这个情况,在归并结束后,如果哪个区间还有数据,就直接加到数组后面就可以,因为排序的数组是有序的,所以直接加到数组后面不会出错。


代码:
void _MergeSort(int* a, int begin, int end, int* temp)
{
if (begin >= end) //至少要有两个区间
return;
int mid = (begin + end) / 2;
//分治 [beging,mid] [mid+1,end]
_MergeSort(a ,begin,mid,temp);
_MergeSort(a, mid+1, end, temp);
int begin1 = begin,end1 = mid;
int begin2 = mid + 1,end2 = end;
int i = begin1; //这里注意是beging1
//归并 把小的放到temp数组中去
while (begin1 <= end1 && begin2 <= end2) {
if (a[begin1]<a[begin2]) {
temp[i++] = a[begin1++];
}
else {
temp[i++] = a[begin2++];
}
}
//如果一个数组走完了,还剩有数据,全部放到数组后面去
while (begin1<=end1) {
temp[i++] = a[begin1++];
}
while (begin2<=end2) {
temp[i++] = a[begin2++];
}
//把数据拷贝回原数组
memcpy(a + begin, temp + begin,(end-begin+1)*sizeof(int));
}
//递归实现
void MergeSort(int *a,int n)
{
int* temp = (int*)calloc(n, sizeof(int));
if (temp==NULL){
perror("tmp初始化失败\n");
return;
}
_MergeSort(a, 0, n-1, temp);
free(temp);
}测试:
归并排序的时间复杂度是典型的:O(N*logN );
二、归并排序非递归实现
归并的非递归直接可以在数组中处理。
其思路是把数组中的数进行分组,设gap个数为一组,每组数又有两个区间,这两个区间做比较,归并成一个有序的区间。有序的区间又可以分组,然后归并。
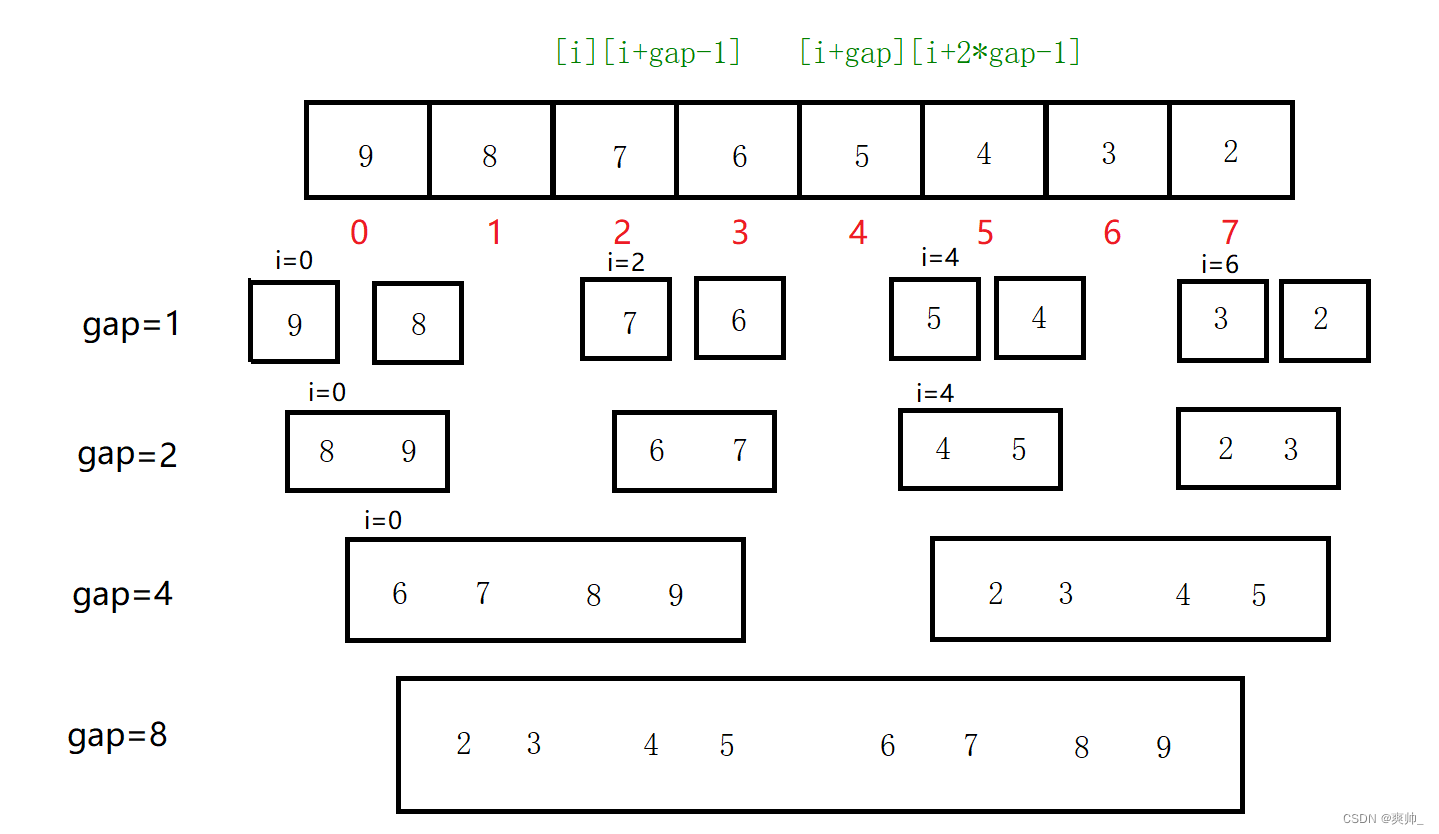
gap=1,每单个一个数分为一组,归并后刚好变为gap=2,两个数的组。依次归并,最后整个数组就有序了。
//归并排序的非递归
void MergeSortNonR(int* a, int n)
{
int* temp = (int*)calloc(n, sizeof(int));
if (temp == NULL) {
perror("tmp初始化失败\n");
return;
}
int gap = 1;
while (gap < n) {
for (int i = 0; i < n; i += 2*gap) { //注意这里是一次跳两组
//[i][i+gap-1] [i+gap][i+2*gap-1]
int begin1 = i, end1 = i + gap - 1;
int begin2 = i + gap, end2 = i + 2 * gap - 1;
int j = begin1;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2]) {
temp[j++] = a[begin1++];
}
else {
temp[j++] = a[begin2++];
}
}
while (begin1 <= end1)
{
temp[j++] = a[begin1++];
}
while (begin2 <= end2) {
temp[j++] = a[begin2++];
}
}
//这里每个数据都归并了所以可以全部拷贝回去。
memcpy(a, temp, sizeof(int) * n);
gap *= 2;
}
free(temp);
}
思路比较好理解,但是要注意的是边界的控制。如果数组的长度不为2的次方倍数,那么不控制边界会造成越界。
比如一个数组长度等于9,调试的时候这里打印一下区间。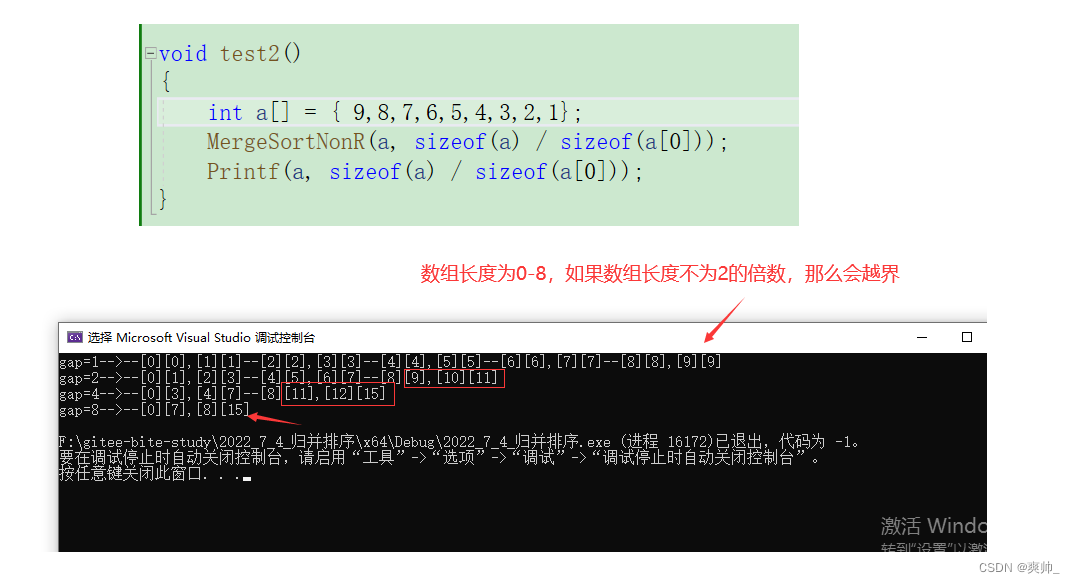
这里就会发现,有点地方的区间大于了数组的长度(数组下标是0-8,9也越界了)。除了begin1不会越界以外,其他的边界都会越界。
所以这里为了防止边界越界,要控制一下边界。
//归并排序的非递归
void MergeSortNonR(int* a, int n)
{
int* temp = (int*)calloc(n, sizeof(int));
if (temp == NULL) {
perror("tmp初始化失败\n");
return;
}
int gap = 1;
while (gap < n) {
printf("gap=%d-->",gap);
for (int i = 0; i < n; i += 2*gap) { //注意这里是一次跳两组
//[i][i+gap-1] [i+gap][i+2*gap-1]
int begin1 = i, end1 = i + gap - 1;
int begin2 = i + gap, end2 = i + 2 * gap - 1;
//修正边界
if (end1 >= n) { //end1越界
end1 = n - 1;
begin2 = n;
end2 = n - 1;
}
else if (begin2 >= n) { //begin2越界
begin2 = n;
end2 = n - 1;
}
else if (end2 >= n) { //end2越界
end2 = n - 1;
}
//打印边界:
printf("--[%d][%d],[%d][%d]",begin1,end1,begin2,end2);
int j = begin1;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2]) {
temp[j++] = a[begin1++];
}
else {
temp[j++] = a[begin2++];
}
}
while (begin1 <= end1)
{
temp[j++] = a[begin1++];
}
while (begin2 <= end2) {
temp[j++] = a[begin2++];
}
}
//这里每个数据都归并了所以可以全部拷贝回去。
memcpy(a, temp, sizeof(int) * n);
printf("\n");
gap *= 2;
}
free(temp);
}
PS:越界后设 begin2 < end2 ,这样越界的右区间就不会进入归并的步骤了。
测试:
还有一种思路,如果区间发生数组越界,那么就不进行归并了。
//归并排序的非递归 第二个控制边界的办法
void MergeSortNonR_Test(int* a, int n)
{
int* temp = (int*)calloc(n, sizeof(int));
if (temp == NULL) {
perror("tmp初始化失败\n");
return;
}
int gap = 1;
while (gap < n) {
printf("gap=%d-->", gap);
for (int i = 0; i < n; i += 2 * gap) { //注意这里是一次跳两组
//[i][i+gap-1] [i+gap][i+2*gap-1]
int begin1 = i, end1 = i + gap - 1;
int begin2 = i + gap, end2 = i + 2 * gap - 1;
//如果end1、begin2越界就不归了
if (end1 >= n || begin2 >= n) {
break;
}
else if (end2 >= n) { //end2越界还是要归并
end2 = n - 1;
}
int m = end2 - begin1 + 1;
//打印边界:
printf("--[%d][%d],[%d][%d]", begin1, end1, begin2, end2);
int j = begin1;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2]) {
temp[j++] = a[begin1++];
}
else {
temp[j++] = a[begin2++];
}
}
while (begin1 <= end1)
{
temp[j++] = a[begin1++];
}
while (begin2 <= end2) {
temp[j++] = a[begin2++];
}
//注意如果不归并了,这里不能把数据拷贝回去,不然会把未初始化的值拷贝回去,所以只能拷贝已经归并了的数据。
memcpy(a + i, temp + i, sizeof(int) * m);
}
printf("\n");
gap *= 2;
}
free(temp);
}
PS:如果是区间越界就跳过归并的话,这里要注意就不能把全部的数据都拷贝回原来的数组,因为没发生归并,这里临时数组里面是未初始化的值,拷贝回去会造成覆盖。所以这里要注意,这里拷贝的话只能拷贝已经归并了的数据。
三、计次排序
计次排序也要额外申请一个数组,其数组大小是原数组最大元素和最小元素的差值。其存的数据是原数组里面数据出现的次数。
然后按照出现的次数把数据写回原来的数组。此排序是个非比较排序。
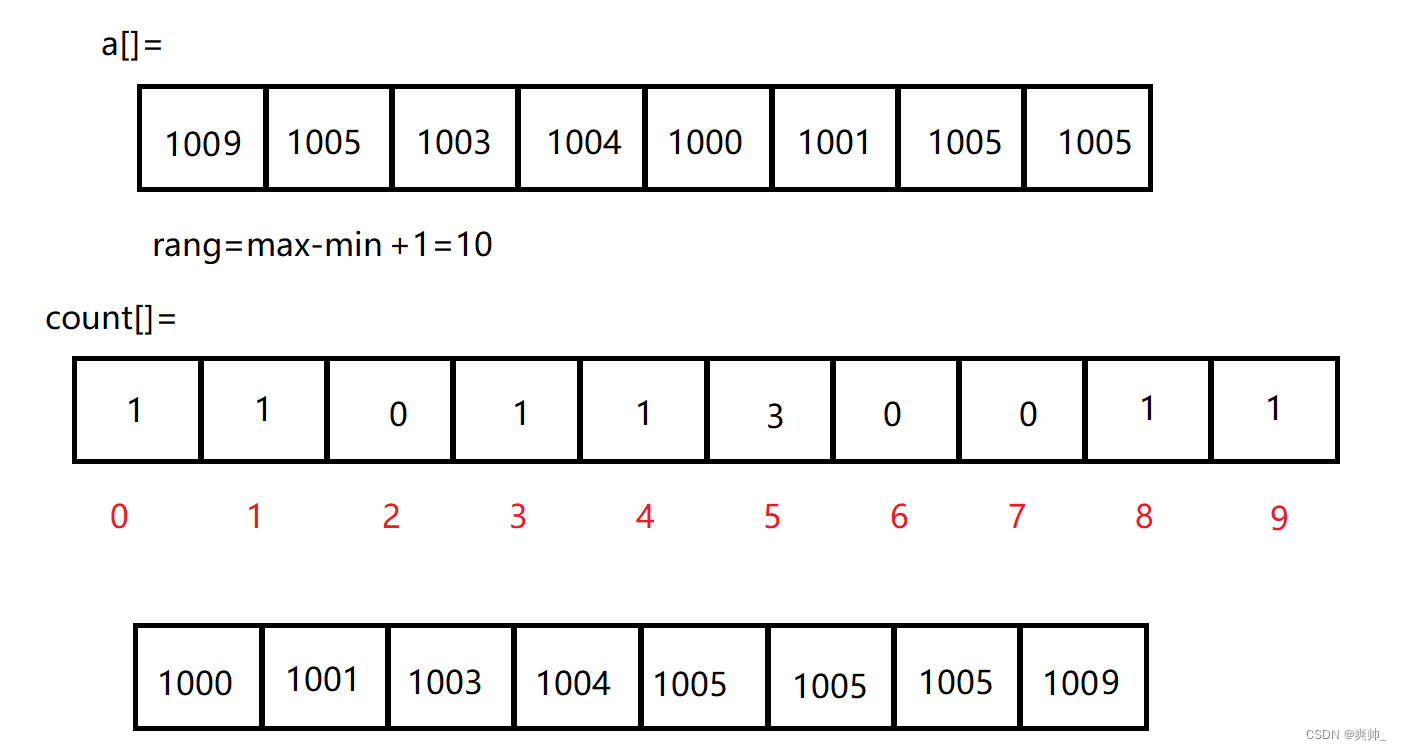
代码:
//计次循环
void CountSort(int *a,int n)
{
//选出最大最小的数,计算差值
int max=a[0], min=a[0];
for (int i = 0; i < n;i++) {
if (a[i]>max) {
max = a[i];
}
if (a[i]<min) {
min = a[i];
}
}
int rang = max - min+1;
int* count = (int*)calloc(rang,sizeof(int));
if (count==NULL) {
perror("count为NULL");
exit(-1);
}
for (int i = 0; i < n;i++) {
//记录出现数据的次数
count[a[i] - min]++;
}
//放回原数组
int k = 0;
for (int j = 0; j < rang;j++) {
while (count[j]--) {
a[k++] = j + min;
}
}
free(count);
}测试:
局限性:
1.浮点数、字符串不能排序。
2.数据范围大,空间复杂度会很高。
此排序的性质就决定了它只能排序范围比较小,重复度较高的数据。如果数据范围交到,其时间和空间的消耗都比较多。
时间复杂度: O( max(rang,N) )
空间复杂度: O(rang) //最小值和最大值的差值越大约消耗空间
拓展:
排序稳定性:
一个数组 6 3 5 4 5 9 1
两个5,排序完成后,红色的还是在黄色的前面,保证相对顺序不变,那么排序就是稳定的。
对于单个数据,稳定性毫无意义。
但是多个数据,部分数据相同,有意义。
| 排序 | 时间最坏 | 时间最好 | 空间复杂度 | 稳定性 |
|---|---|---|---|---|
| 插入排序 | O(N^2) | O(N) | O(1) | √ |
| 希尔排序 | O(N^1.3) | O(N^1.3) | O(1) | × |
| 选择排序 | O(N^2) | O(N^2) | O(1) | × |
| 堆排序 | O(N*logN) | O(N*logN) | O(1) | × |
| 冒泡排序 | O(N^2) | O(N) | O(N) | √ |
| 快速排序 | O(N^2) | O(N*logN) | O(logN) | × |
| 归并排序 | O(N*logN) | O(N*logN) | O(N) | √ |