0、前言
本篇博文主要讲解有监督学习与无监督学习、分类问题与回归问题、生成模型与判别模型、交叉验证、过拟合与欠拟合、偏差与方差分解、正则化、维数灾难相关知识。
1.有监督学习与无监督学习
根据样本数据是否带有标签值,可以将机器学习算法分成有监督学习和无监督学习两类:
有监督学习的样本数据带有标签值,它从训练样本中学习得到一个模型,然后用这个模型对新的样本进行预测推断。有监督学习的典型代表是分类问题和回归问题。
无监督学习对没有标签的样本进行分析,发现样本集的结构或者分布规律。无监督学习的典型代表是聚类,表示学习,和数据降维,它们处理的样本都不带有标签值。
2.分类问题与回归问题
在有监督学习中,如果样本的标签是整数,则预测函数是一个向量到整数的映射,这称为分类问题。如果标签值是连续实数,则称为回归问题,此时预测函数是向量到实数的映射。
3.生成模型与判别模型
分类算法可以分成判别模型和生成模型。给定特征向量x与标签值y,生成模型对联合概率p(x,y)建模,判别模型对条件概率p(y|x)进行建模。另外,不使用概率模型的分类器也被归类为判别模型,它直接得到预测函数而不关心样本的概率分布:
![]()
判别模型直接得到预测函数f(x),或者直接计算概率值p(y|x),比如SVM和logistic回归,softmax回归,判别模型只关心决策面,而不管样本的概率分布的密度。
生成模型计算p(x, y)或者p(x|y) ,通俗来说,生成模型假设每个类的样本服从某种概率分布,对这个概率分布进行建模。
机器学习中常见的生成模型有贝叶斯分类器,高斯混合模型,隐马尔可夫模型,受限玻尔兹曼机,生成对抗网络等。典型的判别模型有决策树,kNN算法,人工神经网络,支持向量机,logistic回归,AdaBoost算法等。
4.交叉验证
交叉验证(cross validation)是一种统计准确率的技术。k折交叉验证将样本随机、均匀的分成k份,轮流用其中的k-1份训练模型,1份用于测试模型的准确率,用k个准确率的均值作为最终的准确率。
5.过拟合与欠拟合
欠拟合也称为欠学习,直观表现是训练得到的模型在训练集上表现差,没有学到数据的规律。引起欠拟合的原因有模型本身过于简单,例如数据本身是非线性的但使用了线性模型;特征数太少无法正确的建立映射关系。
过拟合也称为过学习,直观表现是在训练集上表现好,但在测试集上表现不好,推广泛化性能差。过拟合产生的根本原因是训练数据包含抽样误差,在训练时模型将抽样误差也进行了拟合。所谓抽样误差,是指抽样得到的样本集和整体数据集之间的偏差。
引起过拟合的可能原因有:
①模型本身过于复杂,拟合了训练样本集中的噪声。此时需要选用更简单的模型,或者对模型进行裁剪。
②训练样本太少或者缺乏代表性。此时需要增加样本数,或者增加样本的多样性。
③训练样本噪声的干扰,导致模型拟合了这些噪声,这时需要剔除噪声数据或者改用对噪声不敏感的模型。
6.偏差与方差分解
模型的泛化误差可以分解成偏差和方差。偏差是模型本身导致的误差,即错误的模型假设所导致的误差,它是模型的预测值的数学期望和真实值之间的差距。
方差是由于对训练样本集的小波动敏感而导致的误差。它可以理解为模型预测值的变化范围,即模型预测值的波动程度。
模型的总体误差可以分解为偏差的平方与方差之和:
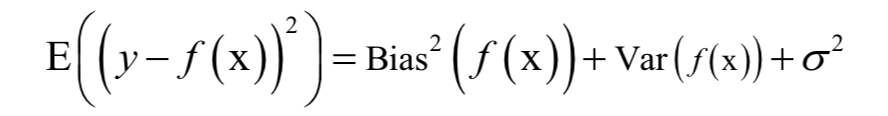
如果模型过于简单,一般会有大的偏差和小的方差;反之如果模型复杂则会有大的方差但偏差很小。
7.正则化
为了防止过拟合,可以为损失函数加上一个惩罚项,对复杂的模型进行惩罚,强制让模型的参数值尽可能小以使得模型更简单,加入惩罚项之后损失函数为:
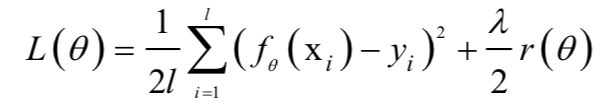
正则化被广泛应用于各种机器学习算法,如岭回归,LASSO回归,logistic回归,神经网络等。除了直接加上正则化项之外,还有其他强制让模型变简单的方法,如决策树的剪枝算法,神经网络训练中的dropout技术,提前终止技术等。
8.维数灾难
为了提高算法的精度,会使用越来越多的特征。当特征向量维数不高时,增加特征确实可以带来精度上的提升;但是当特征向量的维数增加到一定值之后,继续增加特征反而会导致精度的下降,这一问题称为维数灾难。