背景:想利用自己收集的一些图片制作数据集进行训练,但是有8000多张,而且都是常见的检测出人就可以,所以想着利用YOLOv5的detect.py以及YOLOv5的原始权重YOLOv5s.pt进行半自动标注。
命令行:
python3 detect.py --weights weights/yolov5s.pt --source data/detect --classes 0 --device 0 --save-txt
(1) --weights weights/yolov5s.pt
采用YOLOv5自带的权重yolov5s.pt,检测人的效果会好一点,如果自己训练的权重也很好,也可以用自己的;
(2)--source data/detect
这里放入想要标注的图片;
(3)--classes 0
YOLOv5的权重可以检测80个类,但是我们只想让它把我们给的图片中的人检测出来,而人在YOLOv5的80个类中是第一位,所以这里采用--classes 0
(4)--device 0
采用哪一块GPU的训练,我们这里采用第一块;
(5)--save-txt
将预测的框坐标以txt文件形式保存。
效果图


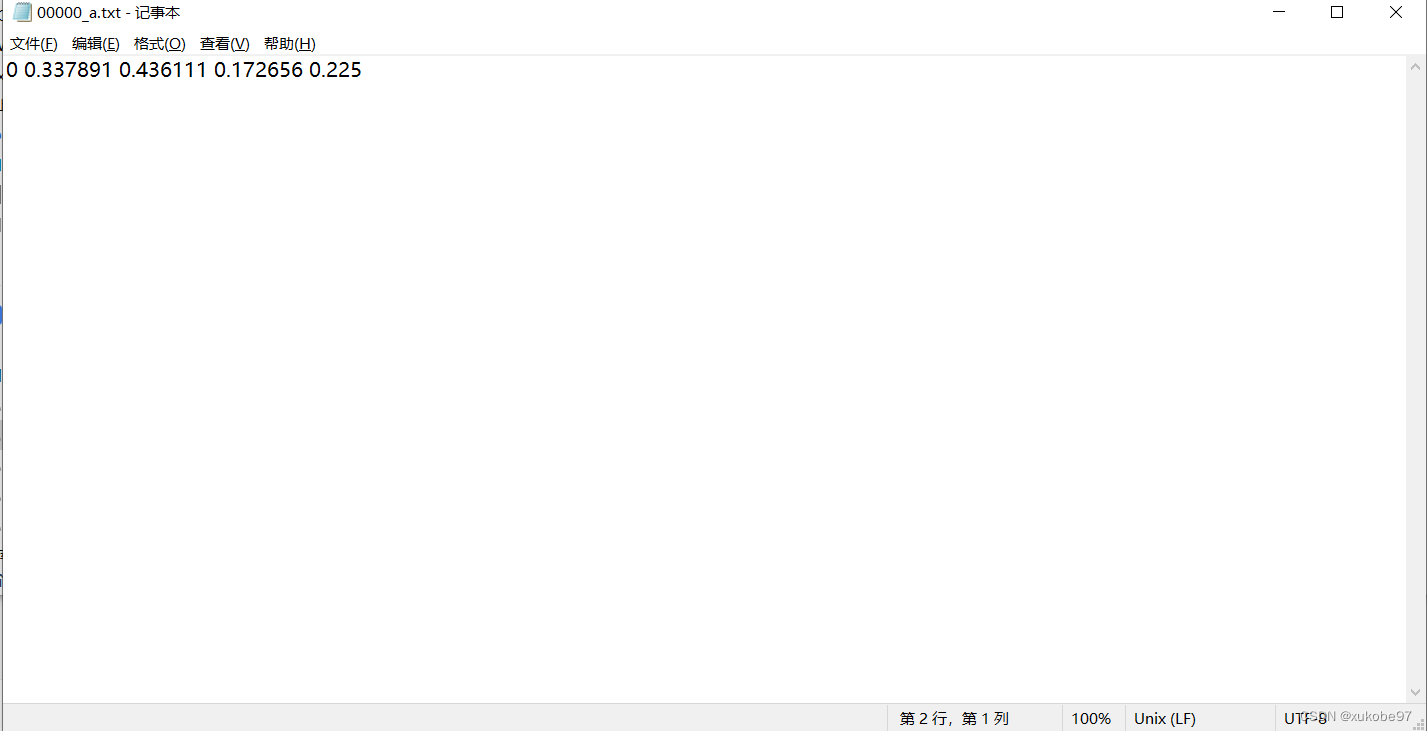
如果你的原始图片上也有txt标签,这就需要将两个txt文档进行合并
可借鉴如下代码:
import os
def concattxt(path1,path2):
num = 0
pathdir1 = os.listdir(path1)#获取第一部分txt文件夹中的文件列表
for txtname in pathdir1:
#name1 = os.path.splitext(txtname)[0]#获取当前txt文件名字
#txtfile1 = open(txtpath1+name1, "rb")
#txtfile2 = open(txtpath2+name1, "rb")
txtfilepath1 = path1+txtname
txtfilepath2 = path2+txtname
txt1 = open(txtfilepath1,'a+', encoding='utf-8')
if os.path.exists(txtfilepath2):
num = num+1
with open(txtfilepath2, 'r', encoding='utf-8') as txt2:
#txt1.write('\n')
for i in txt2:
txt1.write(i)
print('the concat txt num is:',num)
if __name__ == '__main__':
txtpath1 = ''
txtpath2 = ''
concattxt(txtpath1,txtpath2)
如果你想将生成的txt转化为xml,可借鉴这个博客:
yolov5实现半自动化标注/预标注 & txt to xml_国服最强貂蝉的博客-CSDN博客_yolov5 标注
参考文献:
python根据yolov5检测得到的txt文件,截取目标框图片并保存_深度学习菜鸟的博客-CSDN博客