在生产环境中,会因为很多的原因造成访问请求绕过了缓存,都需要访问数据库持久层,虽然对Redsi缓存服务器不会造成影响,但是数据库的负载就会增大,使缓存的作用降低
一 缓存穿透
1,概念
缓存穿透是指查询一个根本不存在的数据,缓存层和持久层都不会命中。在日常工作中出于容错的考虑,如果从持久层查不到数据则不写入缓存层,缓存穿透将导致不存在的数据每次请求都要到持久层去查询,失去了缓存保护后端持久的意义。
缓存穿透示意图:
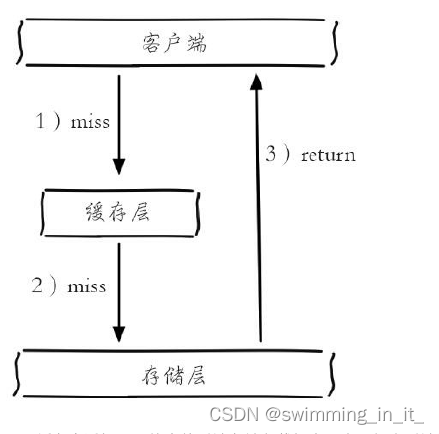
缓存穿透问题可能会使后端存储负载加大,由于很多后端持久层不具备高并发性,甚至可能造成后端存储宕机。通常可以在程序中统计总调用数、缓存层命中数、如果同一个Key的缓存命中率很低,可能就是出现了缓存穿透问题。
2,原因
- 自身业务代码或者数据出现问题(例如:set 和 get 的key不一致)
- 恶意攻击,爬虫等造成大量空命中(爬取线上商城商品数据,超大循环递增商品的ID)
3,解决方案
1.缓存空对象
缓存空对象:是指在持久层没有命中的情况下,对key进行set (key,null)。缓存空对象会有两个问题:
- value为null 不代表不占用内存空间,空值做了缓存,意味着缓存层中存了更多的键,需要更多的内存空间,比较有效的方法是针对这类数据设置一个较短的过期时间,让其自动剔除。
- 缓存层和存储层的数据会有一段时间窗口的不一致,可能会对业务有一定影响。例如过期时间设置为5分钟,如果此时存储层添加了这个数据,那此段时间就会出现缓存层和存储层数据的不一致,此时可以利用消息系统或者其他方式清除掉缓存层中的空对象。
2.布隆过滤器
在访问缓存层和存储层之前,将存在的key用布隆过滤器提前保存起来,做第一层拦截,当收到一个对key请求时先用布隆过滤器验证是key否存在,如果存在在进入缓存层、存储层。可以使用bitmap做布隆过滤器。这种方法适用于数据命中不高、数据相对固定、实时性低的应用场景,代码维护较为复杂,但是缓存空间占用少。
布隆过滤器实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
算法描述:
- 初始状态时,BloomFilter是一个长度为m的位数组,每一位都置为0。
- 添加元素x时,x使用k个hash函数得到k个hash值,对m取余,对应的bit位设置为1。
- 判断y是否属于这个集合,对y使用k个哈希函数得到k个哈希值,对m取余,所有对应的位置都是1,则认为y属于该集合(哈希冲突,可能存在误判),否则就认为y不属于该集合。可以通过增加哈希函数和增加二进制位数组的长度来降低错报率。
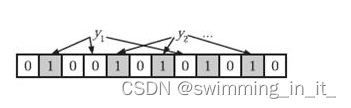
错报原因:
一个key映射数组上多位,一位会被多个key使用,也就是多对多的关系。如果一个key映射的所有位值为1,就判断为存在。但是可能会出现key1 和 key2 同时映射到下标为100的位,key1不存在,key2存在,这种情况下会发生错误率
3,两种方式对比

二 缓存雪崩
1,原因
- 由于缓存层承载着大量请求,有效地保护了存储层,但是如果缓存层由于某些原因不可用(宕机)
- 大量缓存由于超时时间相同在同一时间段失效(大批key失效/热点数据失效),大量请求直接到达存储层,存储层压力过大导致系统雪崩。
2,解决方案
- 可以把缓存层设计成高可用的,即使个别节点、个别机器、甚至是机房宕掉,依然可以提供服务。利用sentinel或cluster实现。
- 采用多级缓存:本地进程作为一级缓存,redis作为二级缓存,不同级别的缓设置超时时间不同,即使某个缓存过期了,那么也有其他级别的缓存兜底。
- 缓存过期的时间尽量采用随机性,尽量让不同的key在不同的时间过期。例如:定时任务新建大批key的时候,设置不同的过期时间
三 缓存击穿
1,原因
- 热点key的并发量特别大
- 在缓存失效的瞬间会有大量的线程来重建缓存,但是缓存重建不能在短时间内重建,造成后端负载过大从而让应用奔溃。
2,解决方案
1.分布式互斥锁:就是在线程重建缓存的时候,设置一个分布式锁,只让一个线程重建缓存即可,其他线程读取缓存数据即可。set key value [expiration EX seconds|PX milliseconds] [NX|XX]
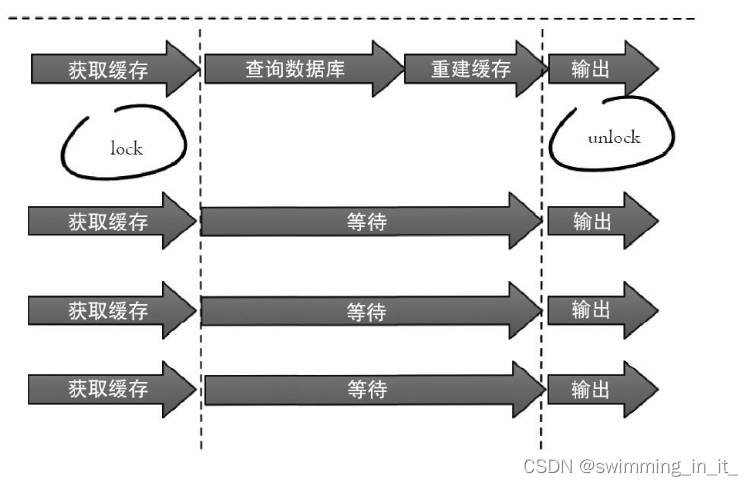
2.永不过期
从缓存层面来看,确实没有设置过期时间,所以不会出现热点key过期后产生的问题,也就是“物理”不过期。从功能层面来看,为每个value设置一个逻辑过期时间,当发现超过逻辑过期时间后,会使用单独的线程去更新缓
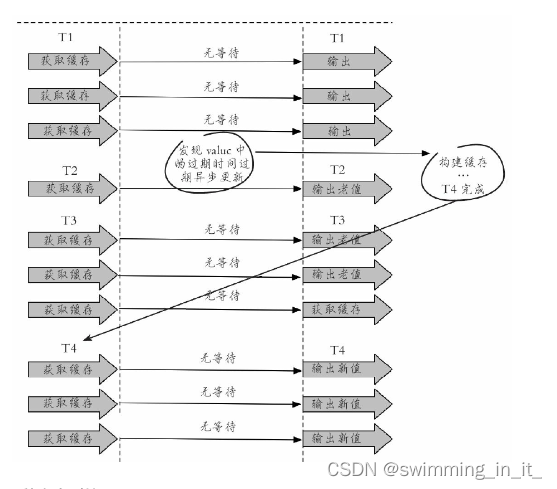
3,方案对比
2种方案对比
分布式互斥锁: 这种方案思路比较简单,但是存在一定的隐患,如果在查询数据库 + 和 重建缓存(key失效后进行了大量的计算)时间过长,也可能会存在死锁和线程池阻塞的风险,高并发情景下吞吐量会大大降低!但是这种方法能够较好地降低后端存储负载,并在一致性上做得比较好。
“永远不过期”: 这种方案由于没有设置真正的过期时间,实际上已经不存在热点key产生的一系列危害,但是会存在数据不一致的情况,同时代码复杂度会增大。
四 其他相关问题
1,热点key
当有大量的请求(几十万)访问某个Redis某个key时,由于流量集中达到网络上限,从而导致这个redis的服务器宕机。造成缓存击穿,接下来对这个key的访问将直接访问数据库造成数据库崩溃,或者访问数据库回填Redis再访问Redis,继续崩溃。
1.发现热点key
- 预估热key,比如秒杀的商品、火爆的新闻等
- 在客户端进行统计,实现简单,加一行代码即可
- 如果是Proxy,比如Codis,可以在Proxy端收集
- 利用Redis自带的命令,monitor、hotkeys。但是执行缓慢(不要用)
- 利用基于大数据领域的流式计算技术来进行实时数据访问次数的统计,比如 Storm、Spark、Streaming、Flink,这些技术都是可以的。发现热点数据后可以写到zookeeper中
2.解决方案
- 变分布式缓存为本地缓存,发现热key后,把缓存数据取出后,直接加载到本地缓存中。可以采用Ehcache、Guava Cache都可以,这样系统在访问热key数据时就可以直接访问自己的缓存了。(数据不要求时时一致)
- 在每个Redis主节点上备份热key数据,这样在读取时可以采用随机读取的方式,将访问压力负载到每个Redis上。
- 利用对热点数据访问的限流熔断保护措施,每个系统实例每秒最多请求缓存集群读操作不超过 400 次,一超过就可以熔断掉,不让请求缓存集群,直接返回一个空白信息,然后用户稍后会自行再次重新刷新页面之类的。(首页不行,系统友好性差)通过系统层自己直接加限流熔断保护措施,可以很好的保护后面的缓存集群.
2,大key
大key指的是存储的值(Value)非常大。大key会大量占用内存,在集群中无法均衡,Redis的性能下降,主从复制异常。在主动删除或过期删除时会操作时间过长而引起服务阻塞

1,如何发现大key
- redis-cli --bigkeys命令。可以找到某个实例5种数据类型(String、hash、list、set、zset)的最大key。但如果Redis 的key比较多,执行该命令会比较慢。
- 获取生产Redis的rdb文件,通过rdbtools分析rdb生成csv文件,再导入MySQL或其他数据库中进行分析统计,根据size_in_bytes统计big key
2,解决方案
- string类型的big key,尽量不要存入Redis中,可以使用文档型数据库MongoDB或缓存到CDN上。如果必须用Redis存储,最好单独存储,不要和其他key一起存储。采用一主一从或多从。
- 单个简单key存储的value很大,可以尝试将对象分拆成几个key-value, 使用mget获取值,这样分拆的意义在于分拆单次操作的压力,将操作压力平摊到多次操作中,降低对redis的IO影响。hash, set,zset,list 中存储过多的元素,可以将这些元素分拆。
以hash类型举例来说,对于field过多的场景,可以根据field进行hash取模,生成一个新的key,例如原来的
hash_key:{filed1:value, filed2:value, filed3:value …},可以hash取模后形成如下
key:value形式
hash_key:1:{filed1:value}
hash_key:2:{filed2:value}
hash_key:3:{filed3:value}
…
取模后,将原先单个key分成多个key,每个key filed个数为原先的1/N
- 删除大key时不要使用del,因为del是阻塞命令,删除时会影响性能。使用 **lazy delete (unlink命令)**删除指定的key(s),若key不存在则该key被跳过。但是,相比DEL会产生阻塞,该命令会在另一个线程中回收内存,因此它是非阻塞的。 这也是该命令名字的由来:仅将keys从key空间中删除,真正的数据删除会在后续异步操作。
参考链接:
https://blog.csdn.net/womenyiqilalala/article/details/105205532