爬虫基础入门
什么是爬虫:
爬虫又称为网页蜘蛛/网络机器人,是一种按照一定规则,自动爬取万维网的程序或者脚本,是搜索引擎的重要组成。
爬虫的作用:
1.搜索引擎
2.数据分析,发现规律,商品活动等等
3.人工智能, 依靠爬虫获取海量数据
4. 薅羊毛, 抢车票
爬虫产品:
1.神箭手 2.八爪鱼 3.造数 4.后羿采集器
爬虫技术怎么学?
1.python基础语法
2.学习python爬虫常用到的几个重要内置库Requests,用于网页请求
3. 学习正则表达式,re, Xpath,lxml 等网页解析工具
4. 开始一些简单的网页爬取,了解爬取数据过程
5. 了解爬虫的一些反爬机制,header,robot,代理ip,验证码等等
6. 了解爬虫与数据库的结合,如何将爬取数据进行储存
7. 学习应用python的多线程/多进程进行派去,提高爬虫效率
8. 学习爬虫框架scrapy
什么是协议?
协议可以理解为“规则”,是数据传输和数据解释的规则。
HTTP协议
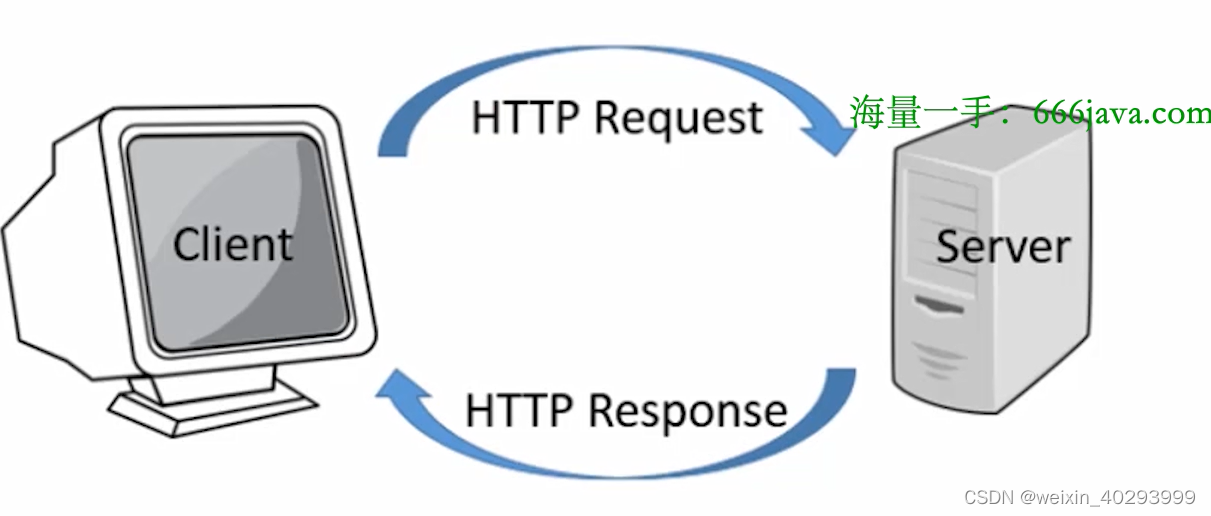
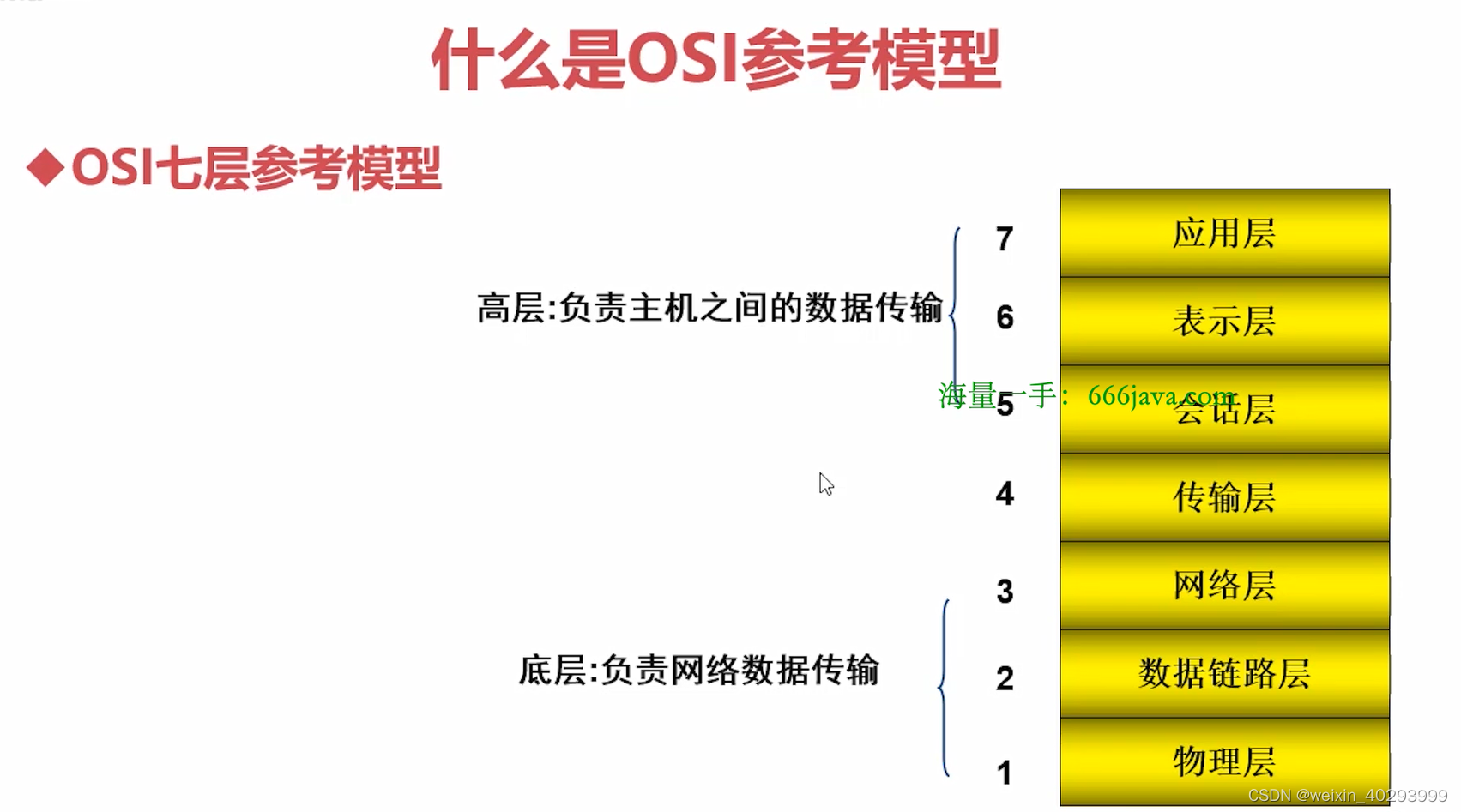

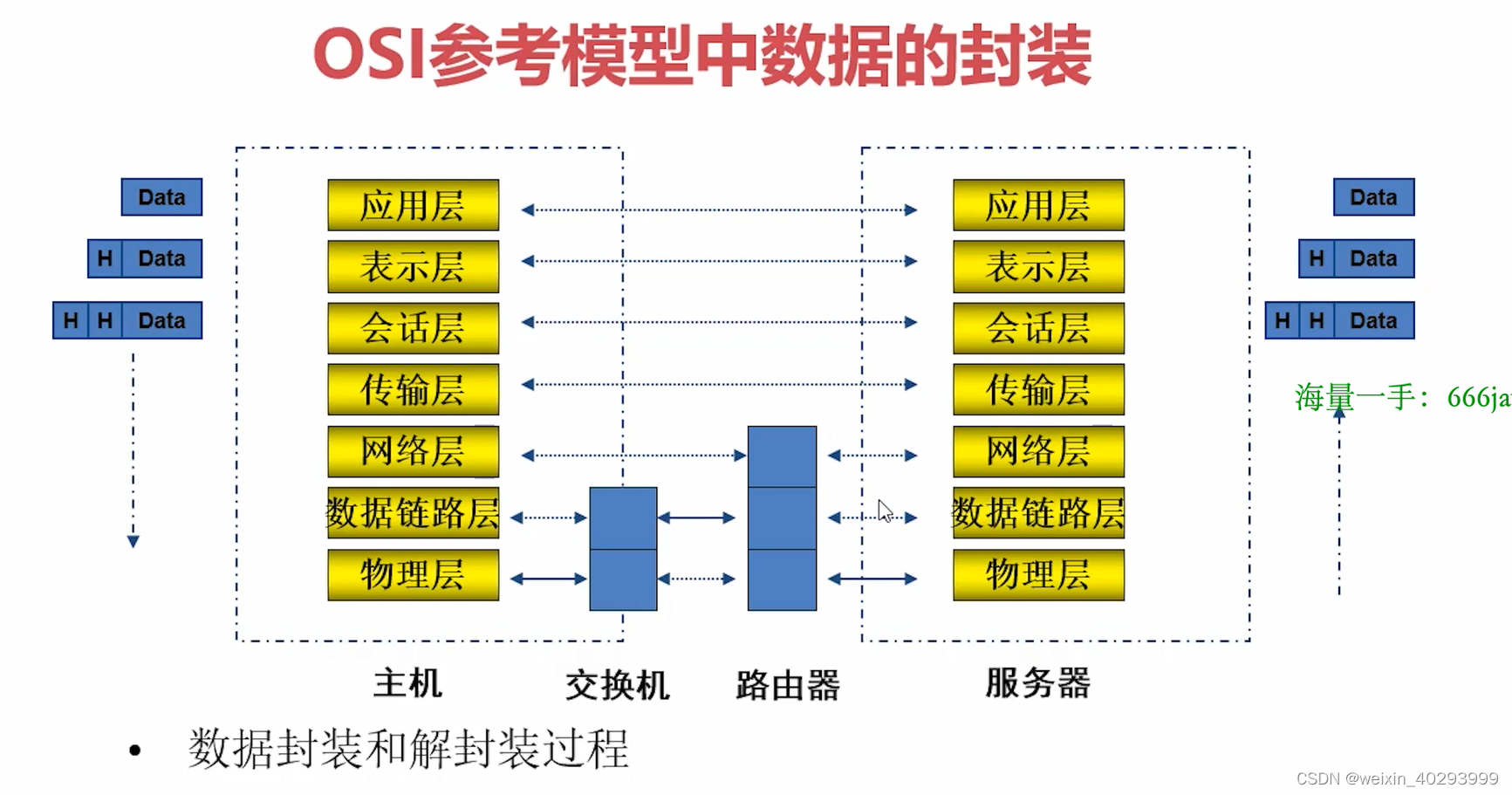
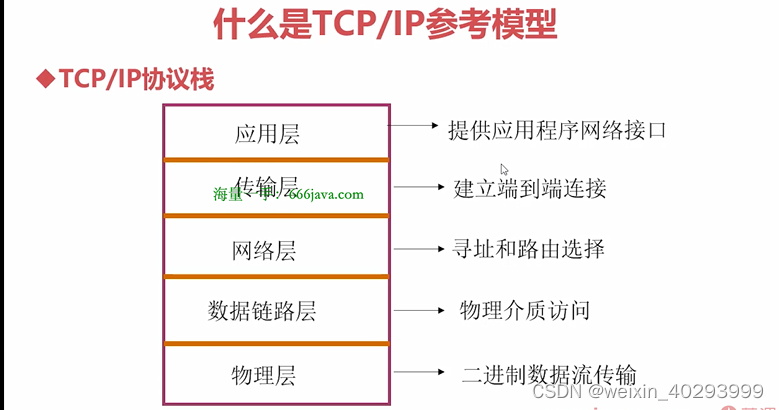
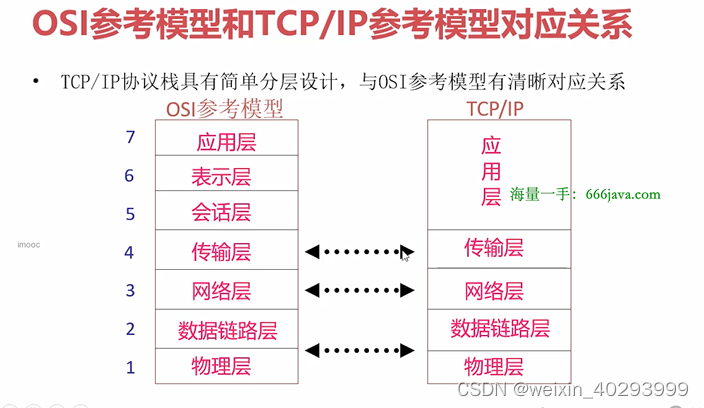
TCP4层,或者5层模型
TCP/IP各层实现的协议:
应用层:
HTTP:超文本传输协议,基于TCP,使用80端口,是用于从www服务器传输超文本到本地浏览器的传输协议。
SMTP:简单邮件传输协议,基于TCP,使用25号端口,是一组用于由源地址到目的地址传送邮件的规则,用来控制新建的发送/中转。
FTP:文件传输协议,基于TCP,一般上传下载用FTP服务,数据端口是20号,控制端口是21号。
TELNET:远程登录协议,基于TCP 使用23号端口,是Internet远程登录服务的标准协议和主要方式。为用户提供了在本地计算机上完成远程主机工作的能力。在终端使用者的电脑上使用telnent程序连接到服务器。使用明码传送,保密性差、简单方便。
DNS:域名解析,基于UDP,使用53号端口,提供域名到IP地址之间的转换。
SSH:安全外壳协议,基于TCP,使用22号端口,为建立在应用层和传基础上的安全协议,ssh是目前比较可靠,专门为远程登录会话和其它网络服务提供安全性的协议。
传输层:
TCP: 传输控制协议,一种面向连接的/可靠的/基于字节流的传输层通信协议。
UDP:用户数据报协议。一种面向无连接的通讯协议,不可靠/基于报文的传输层通信协议。
SCTP:流量传输控制协议。一种面向连接的流传输协议。是TCP的一种改进,继承了它完善的拥塞控制,并且改进了它的一些不足。
SCTP(Stream Control Transmission Protocol)协议是一种面向连接的传输层协议。与传输控制协议(TCP)和用户数据报协议(UDP)不同,SCTP提供了可靠的原始数据,并支持多路复用、消息传送和流控制。
SCTP最初是开发为IP网络电话(VoIP)应用程序的传输协议,但它也可以用于多种其他应用程序,如可靠文件传输和流媒体。
与TCP相比,SCTP提供了更高的可靠性,支持部分可靠传输,从而避免了丢失数据包的问题,同时还增加了拥塞控制和流量控制功能。SCTP还提供了多路复用功能,可以在单个连接上传输多个流。
总的来说,SCTP比TCP更适用于需要高可靠性和流量控制的应用程序,如VoIP、视频流和金融交易等。
MPTCP:多路径传输控制协议。TCP的多路径版本。SCTP虽然在收发两端由多条路径,但实际只是使用一条路径传输,当该条路径出现故障时,不需要断开连接,二十转移到其它路径。真正意义上实现了多路径并行传输,在连接建立阶段,建立多条路径,然后使用多条路径同时传输数据。


ARP协议 局域网内的
ping命令就是ICMP协议
HTTP请求格式

面试题
请简述:从客户端打开浏览器到服务器返回网页,中间过程?
宏观层面:



围观层面:

request模块的安装
request模块的基本请求方法
request模块保持登录凭证
request设置证书/伪装爬虫


简易网页数据抓取
Request是一个优雅的python HTTP库
中文文档: https://requests.readthedocs.io/projects/cn/zh_CN/latest/
文档英文版:
http://www.python-requests.org/en/master/
网络爬虫的环境集成
#在发送请求的时候,是必须要导入requests包
import requests
# 通过get方法来请求数据,requests.get
# url
# response = requests.get(url='http://www.qq.com')
# 查看返回text
# print(response.text)
#导入requests包
# import requests
#构造发送的数据,字典的格式
# data = {"name":"imooc"}
#发送的是post请求,data关键字,data参数
# response = requests.post('http://httpbin.org/post',data=data)
#查看返回数据
# print(response.text)
#这个网页,返回的get请求的数据和post请求的数据是不一样的。
# import requests
#
#构造的URL的数据,一定要和Post请求做好区分
# data = {'key1':'value1','key2':'value2'}
#使用的是GET请求的方法,params关键字一定要做好区分
# response = requests.get('http://httpbin.org/get',params=data)
#查看了是哪个URL给我们返回的数据
# # print(response.url)
#查看返回头,注意,是headers不是header
# # print(response.headers)
#查看返回体
# print(response.text)
#请求图片
# import requests
#get方法
# response = requests.get("https://www.imooc.com/static/img/index/logo.png")
#一定要使用wb模式
# with open('imooc.png','wb') as f:
#返回的不再是文本数据了,而是二进制的数据,content
# f.write(response.content)
# #请求的json数据
# import requests
# #定义了一个变量,设置了一个浏览器的请求头,user-agent
# header = {
# 'user-agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3610.2 Safari/537.36'
# }
# #发送自定义的请求头部的时候,关键字是headers
# response = requests.get('http://httpbin.org/ip',headers=header)
# #查看状态码
# # print(response.status_code)
# # #返回的是json数据,response.json
# # data = response.json()
# # print(data)
# # print(data['origin'])
# print(response.headers)
# print(response.request.headers)
# import requests
#
# #设置了关键字timeout超时时间,0.001,如果0.001秒之内,没有给我返回数据,则会抛出一个timeout报错
# #项目里一般设置为2-3秒合适
# response = requests.get('http://www.github.com',timeout=2)
# print(response.status_code)
# print(response.text)
# import requests
# url = 'https://www.baidu.com'
# #定制请求头,使用了一个标准的浏览器的UA
# header = {
# 'user-agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3610.2 Safari/537.36'
# }
#
# response = requests.get(url=url,headers=header)
# print(response.headers)
# #cookie是一个对象RequestsCookieJar,行为和字典类似
# print(response.cookies)
# print(response.cookies['BIDUPSID'])
# import requests
# #可以查看当前发送cookie的url,可以进行测试
# url = 'http://httpbin.org/cookies'
# #使用了字典来构造cookie
# cookies = dict(cookies_are='hello imooc')
# #get请求方法,cookies,变量也叫cookies,不要搞混
# response = requests.get(url=url,cookies=cookies)
# print(response.text)
实例化session方法,用于自动化的记录session信息
import requests
#在requests模块中有session方法
# 为什么没有携带请求头
# 不需要提供定制化的请求头,直接使用python默认的请求头就可以
# 需要提供请求的数据
login_data = {
"email": "[email protected]",
"password": "abcd1234"
}
# 实例化session方法,用于自动化的记录session信息
session = requests.session()
# 发送了一个POST请求,并且提供了login_data数据
# login_response = requests.post(url="http://yushu.talelin.com/login", data=login_data)
# 1.需要把原来的requests替换为实例化好的session
login_response = session.post(url="http://yushu.talelin.com/login", data=login_data)
# print(login_response.text)
# 登录之后,请求个人信息页的时候是失败的
# 可以在请求头中提供cookies就可以访问个人信息页面了
# personal_response = requests.get(url="http://yushu.talelin.com/personal")
# 自动化的带上session,个人的登录凭据信息
personal_response = session.get(url="http://yushu.talelin.com/personal")
import requests
# verify默认是开启的
# 是一个自签名的证书的网站
# 当前浏览器是没有这个网站的证书的
response = requests.get(url="https://218.28.111.252/login.html", verify=False)
print(response.text)
# dynamic.xingsudaili.com:10010
import requests
# 用来查看我们源IP地址的
url = "http://pv.sohu.com/cityjson"
# response = requests.get(url=url)
# 47.240.60.15
# print(response.text)
proxy = {
# http://用户名:密码@代理的接口信息
"http": "http://dazhuang:[email protected]:10010",
"https": "http://dazhuang:[email protected]:10010"
}
while True:
response = requests.get(url=url, proxies=proxy)
print(response.text)
import requests
# 构造4页连接
# 发送请求,请求4页连接数据
# 获取response数据response.text
# with open文件,把response.text写入html文件
header = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36"
}
proxy = {
# http://用户名:密码@代理的接口信息
"http": "http://dazhuang:[email protected]:10010",
"https": "http://dazhuang:[email protected]:10010"
}
for i in range(1, 5):
# 构造4页链接
url = "http://yushu.talelin.com/book/search?q=python&page={}".format(i)
# 发送请求, 还要携带自定义的请求头和购买的代理
response = requests.get(url=url, headers=header, proxies=proxy)
# 获取response数据
# print(response.text)
# 将response数据写入html文件
html_file_name = "page_{}.html".format(i)
# 写入本地html文件
with open(html_file_name, "w", encoding="utf-8") as f:
f.write(response.text)
print("{}文件已下载好".format(html_file_name))