1.介绍
A. bfs:简称为广度优先搜索算法,其通常用于图论当中需要进行广度遍历的时候使用,其原理就是从最初源点开始进行逐层逐层的遍历搜索信息。
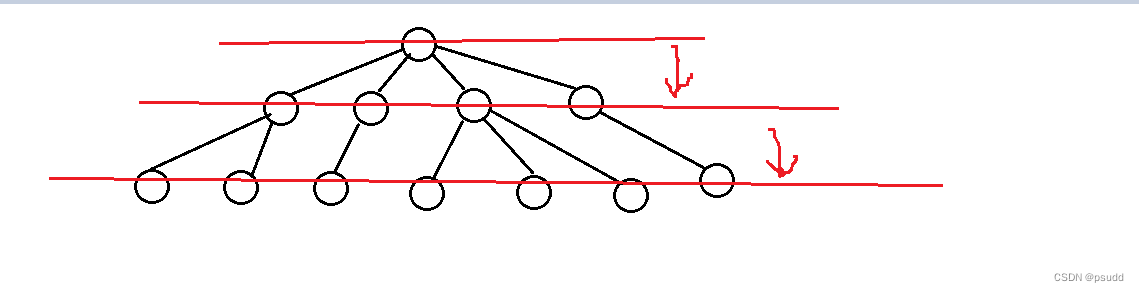
它的特殊之处也就在于我们需要层序遍历每一层的信息,首先搜索完成第二层信息才可以继续搜索第三层然后再是第四层的信息,完成这个操作的关键就是我们需要使用队列去存储结点,这样就可以保证先进入的结点在随后的操作当中也可以优先被拿出来进行访问。
2.细节
A. 保证队列结点和结点标记一致性(防止重复入队列)
防止重复入队列:必须同步队列内结点和标记的的一致性(一旦进入队列必须设置相关标记为false)
即队列的queue.push(x) 和 st[x] = false / true 操作必须同时出现,queue.pop(x) 和 st[x] = true / false 也必须同步
/* 正确代码 */
void bfs(int x){
queue<int> q;
q.push(x);
st[x] = false;
while(!q.empty()){
x = q.front();
q.pop();
for(int i = 0; ; i ++ ){
int j = v[x][i];
if(st[j]){
q.push(j);
st[j] = false;
}
}
}
return ;
}
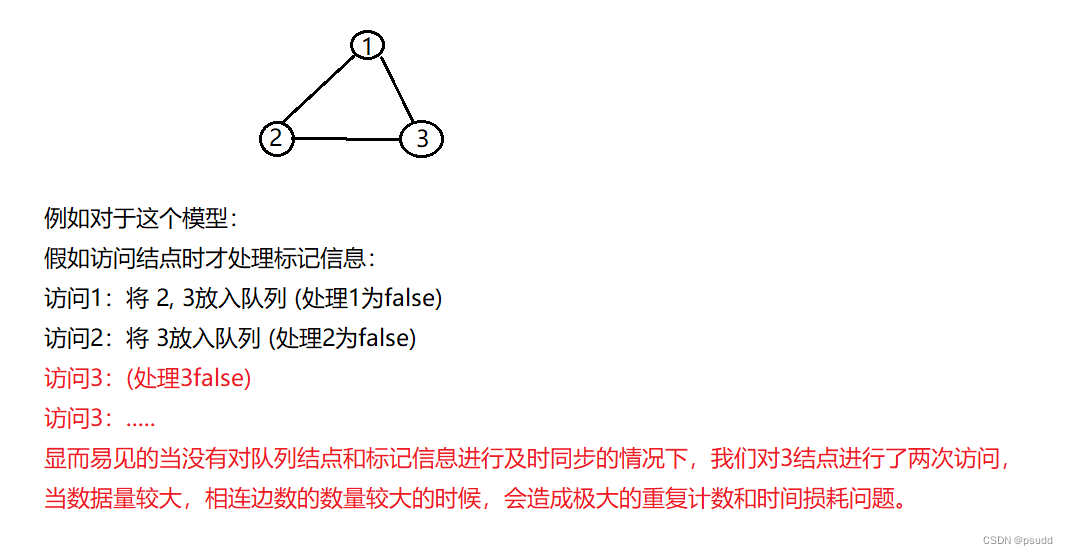
这里建议千万不要将 st[ ]标记的相关处理放到当队列访问结点的时候再处理,因为如果这样子操作不仅对答案正确性可能造成影响而且还会加深其时间复杂度。
/* 错误代码 */
void bfs(int x){
queue<int> q;
q.push(x);
while(!q.empty()){
x = q.front();
q.pop();
st[x] = false; // 千万不能放到队列访问结点时再修改其标记
for(int i = 0; ; i ++ ){
int j = v[x][i];
if(st[j]){
q.push(j);
}
}
}
return ;
}
关键就是如果在队列访问结点的时候再去对其标价进行处理会导致其重复入队列,假如题目是求计数类相关问题的时候,重复进入队列就可能会造成多次重复计数会对答案造成影响。并且因为队列当中可能进入了多个重复的元素,我们就需要对多个重复元素进行处理,这在数据量较大的时候,会大大的加深时间复杂度甚至可能造成Time limit exceded超时