在使用jieba计算tf-idf时候,
jieba.analyse.extract_tags(txt, topK=10, withWeight=True, allowPOS=())
TF根据txt的输入计算,而每个词IDF是jieba内部给定的。
想根据已有的文本计算idf,利用jieba的分词,计算自定义idf语料库
输入

如图当作三篇文章,通过换行作为文章间隔,最后一篇也要换行
输出
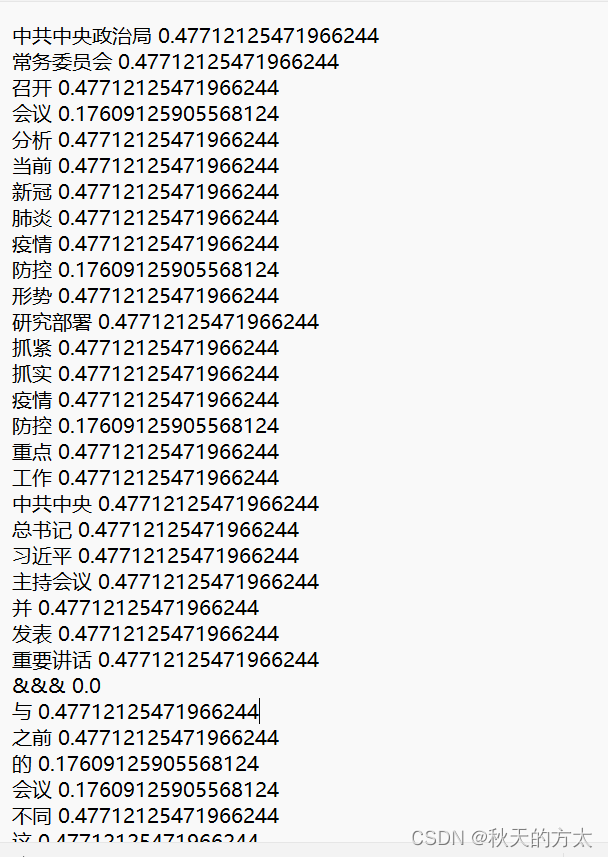
全部代码
#自定义计算idf语料库 python全部代码
import jieba
import math
import jieba.analyse
txt = open(r"C:\Users\19624\Desktop\dissertation\Multiword\a.txt", "r", encoding='utf-8').read()
filename1 = r"C:\Users\19624\Desktop\dissertation\Multiword\idf.txt"
filename2 = r"C:\Users\19624\Desktop\dissertation\Multiword\wdic.txt"
words = jieba.lcut(txt) # 使用精确模式对文本进行分词
with open(filename2, 'a+', encoding='utf-8') as file2:### 每次运行清空一下文件
file2.truncate(0)
with open(filename2, 'a', encoding='utf-8') as file2:#### 将jieba分词结果写入,每词一行,以&&&为每个文本间隔
for i in range(0, len(words)):
if words[i] == '\n':
file2.write('&&&'+'\n') # 写入文件
else:
file2.write(words[i]+'\n') # 写入文件
with open(filename2, encoding='utf-8') as file:
contents = file.readlines() # 读取文件
newList = []
for content in contents:
newContent = content.replace('\n', '')
newList.append(newContent) # 存放在列表中
num = 0 ##统计总文档数
for i in range(0, len(newList)):
if newList[i] == '&&&':
num+=1
with open(filename1, 'a+', encoding='utf-8') as f: ### 每次运行清空一下文件
f.truncate(0)
###计算每个词的idf
for i in range(0, len(newList)):
num1=0
word=newList[i]
j=0
while j < len(newList):
if word==newList[j]:
num1+=1
while newList[j]!='&&&':
j+=1
j+=1
idf=math.log10(num/num1)
with open(filename1, 'a', encoding='utf-8') as file1:
file1.write(word + ' ' + str(idf) + '\n') # 写入文件
换一下输入输出路径,应该就没问题。
txt是输入,filename1是最终输出。