研究背景:
针对的背景问题设定:
- 数据异质性:不同终端数据采样自不同分布
- 训练参与率:每一轮训练的终端参与率较低
泛化性解释:
机器学习不仅关注学习算法在训练样本上的性能,更关注其在未知样本上的预测能力
泛化性度量:
指标:期望风险
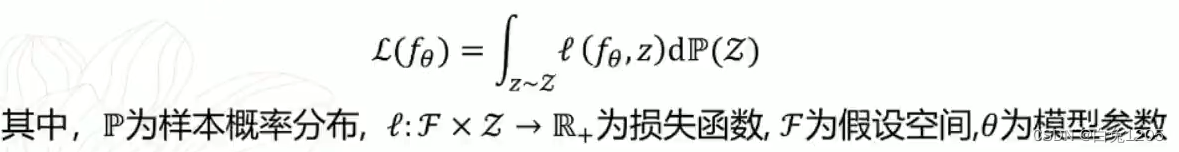

在全概率空间上误差的一个平均值 ,模型在所有样本点上的平均损失是多少
理想情况:选取期望误差最小的模型



主要目标:
探究面向“数据异质性(终端非独立同分布)”和“终端可能掉线”的联邦学习泛化分析
问题建模:

元分布:想用多个终端训练一个人脸识别系统,每个客户端(手机)上面的分布是不一样的,但是拍的都是脸,人脸本质上属于更高层次上的一种分布,这个可以理解为分布的分布
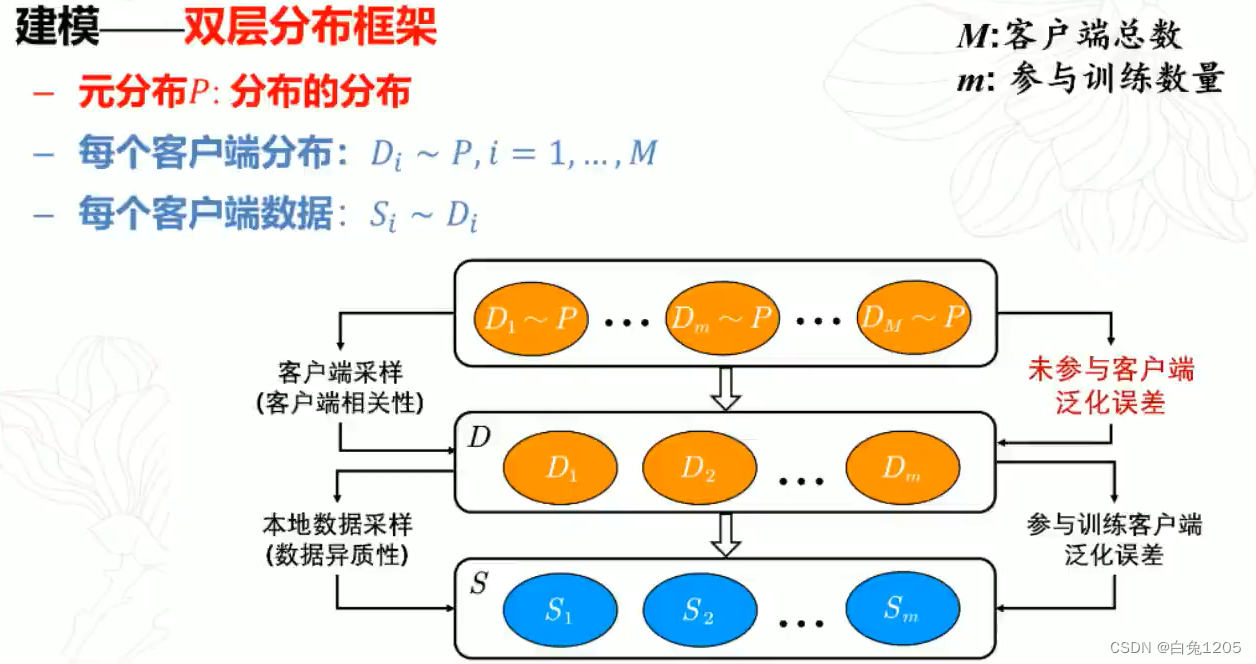
M可以是无穷的,每个m不一样,但是分布的分布是一样的
每个终端来自一个元分布
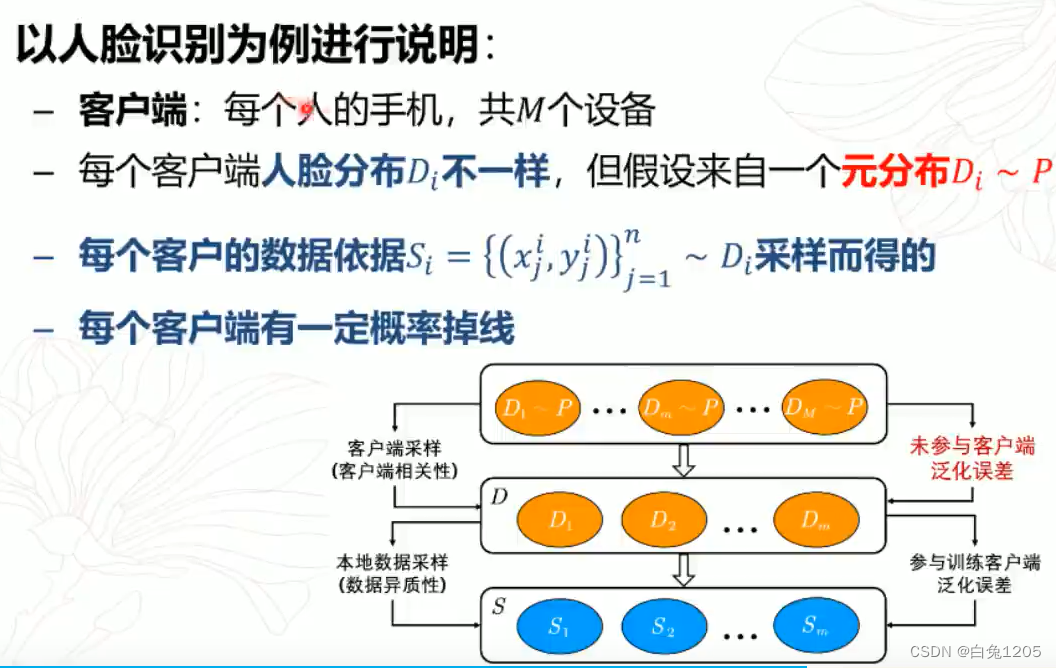

联邦学习泛化分析:


实际情况下,会存在噪音,损失可能是无界的



进一步工作:
