BP算法(暴力枚举、朴素模式匹配算法)
算法的思路是从s的每一个字符开始依次与t的字符进行匹配。
每次结束原字符串从i-j+1开始,比较字符串从0开始
#define MAXLEN 255
typedef struct{
char ch[MAXLEN];
int length;
}SString;
int Index(SString S, SString T){
int i=1; //扫描主串S
int j=1; //扫描模式串T
while(i<=S.length && j<=T.length){
if(S.ch[i] == T.ch[j]){
++i;
++j; //继续比较后继字符
}
else{
i = i-j+2;
j=1; //指针后退重新开始匹配
}
}
if(j>T.length)
return i-T.length;
else
return 0;
}
时间复杂度分析:
主串长度为n,模式串长度为m
最多比较n-m+1个子串
最坏时间复杂度 = O(nm)
每个子串都要对比m个字符(对比到最后一个字符才匹配不上),共要对比n-m+1个子串,
复杂度 = O((n-m+1)m) = O(nm - m^2 + m) = O(nm)
PS:大多数时候,n>>m
最好时间复杂度 = O(n)
每个子串的第一个字符就匹配失败,共要对比n-m+1个子串,复杂度 = O(n-m+1) = O(n)
KMP算法
**定义:**KMP算法是D.E.Knuth、J.H.Morris和V.R.Pratt共同提出的,简称KMP算法。
朴素算法理解简单,但两个串都有依次遍历,时间复杂度为O(n*m),效率不高。由此有了KMP算法。
一般的,在一次匹配中,我们是不知道主串的内容的,而模式串是我们自己定义的。
朴素算法中,P的第j位失配,默认的把P串后移一位。
但在前一轮的比较中,我们已经知道了P的前(j-1)位与S中间对应的某(j-1)个元素已经匹配成功了。这就意味着,在一轮的尝试匹配中,我们get到了主串的部分内容,我们能否利用这些内容,让P多移几位(我认为这就是KMP算法最根本的东西),减少遍历的趟数呢?答案是肯定的。再看下面改进后的动图:
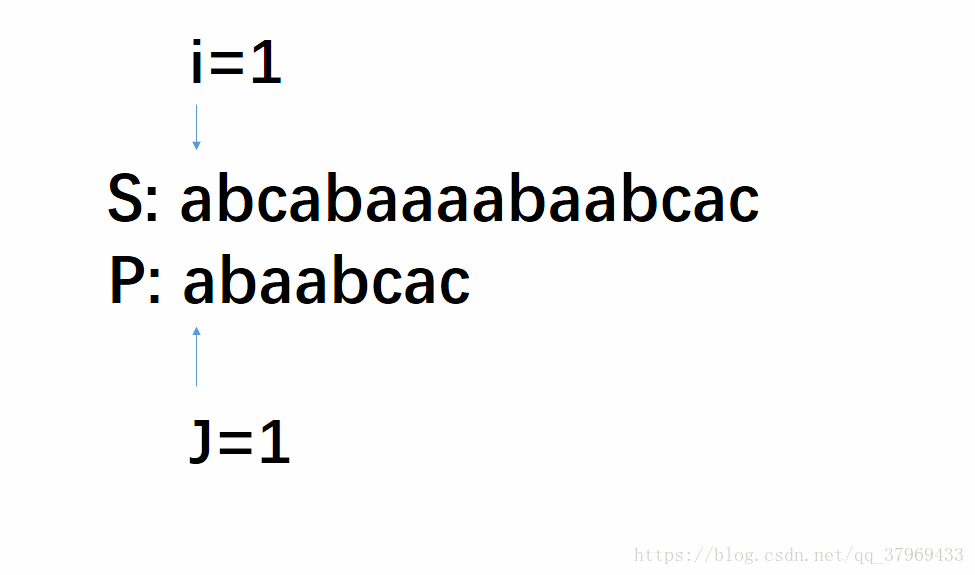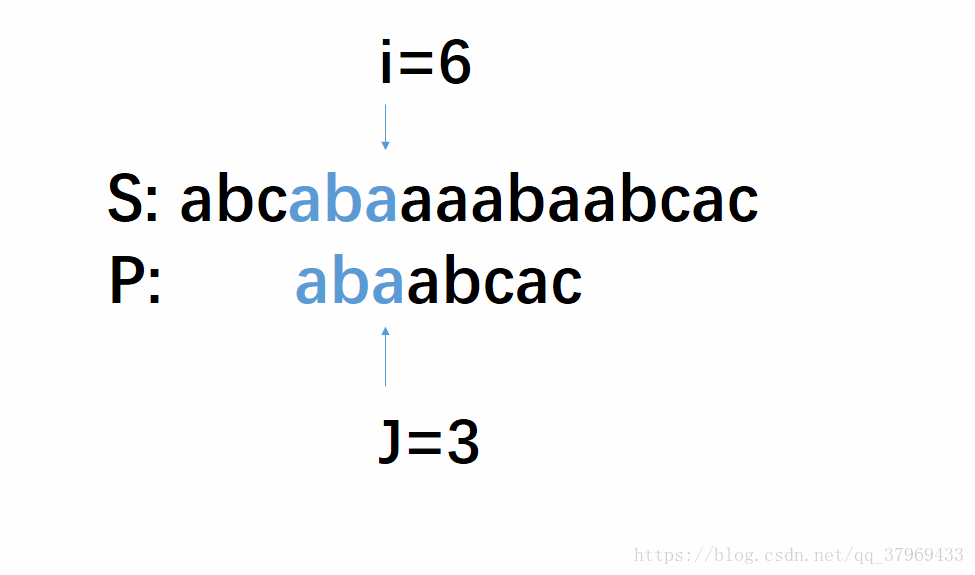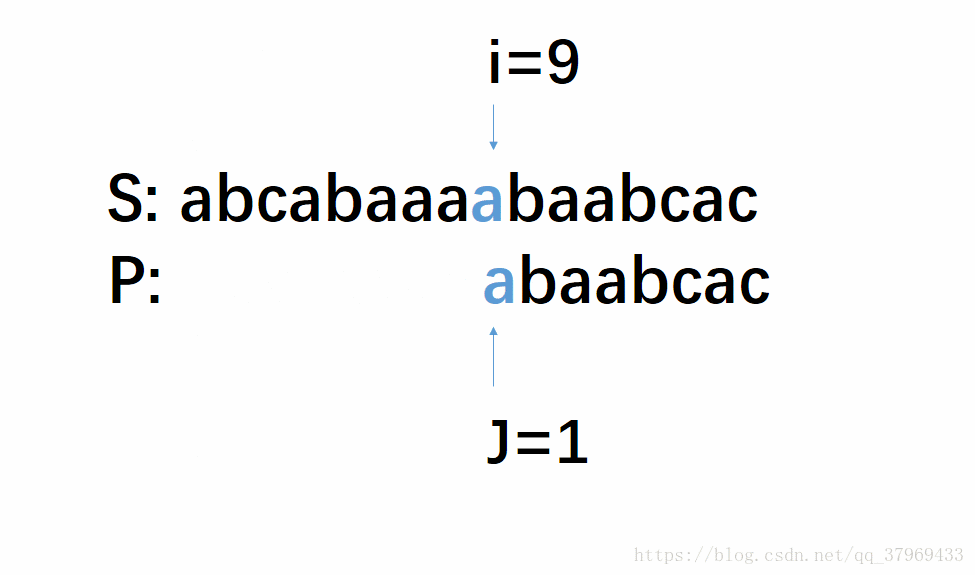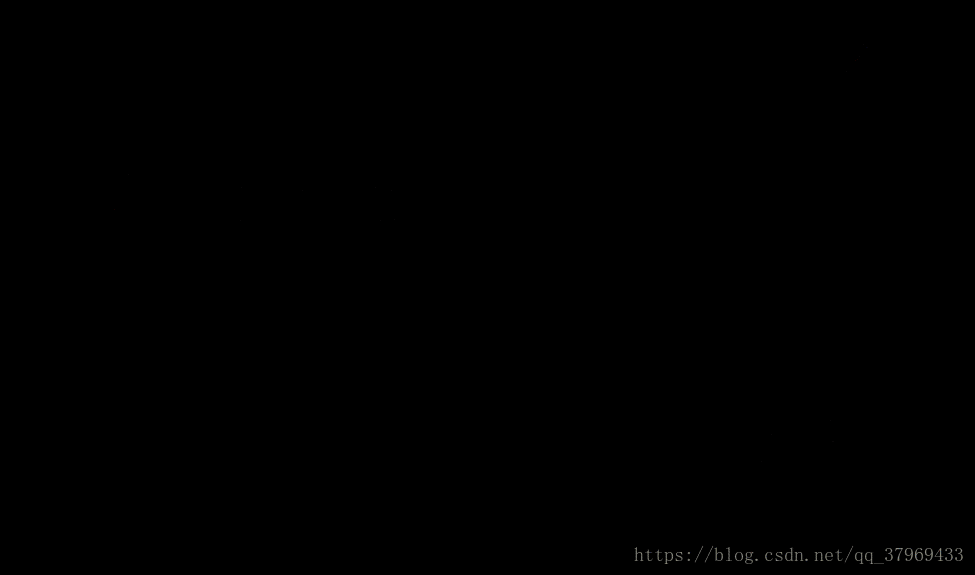
这个模拟过程即KMP算法,若没有看明白,继续往下看相应的解释,理解需要把P多移几位,然后回头再看一遍这个图就很明了了。
相比朴素算法:
朴素算法: 每次失配,主串(S串)的索引i定位的本次尝试匹配的第一个字符的后一个。模式串(P串)的索引j定位到1;
T(n)=O(n*m)
KMP算法: 每次失配,主串(S串)的索引i不动,模式串(P串)的索引j定位到某个数。
T(n)=O(n+m),时间效率明显提高
KMP算法主要是避免主串中的下标回溯,只回溯模式串中的下标j
而这“定位到某个数”,这个数就是接下来引入的next数组值。
代码(求next数组的get_next()代码先不给出,在下一部分给出)
//KMP算法
int Index_KMP(SString S,SString T)
{
int i = 1, j = 1;
int next [T.length + 1];
get_next(T, next); //求模式串的next数组
while(i<=S.length&&j<=T.length)
{
if(j==0||S.ch[i]==T.ch[j])
{
++i;
++j; //继续比较后继字符
}
else
j = next[j]; //模式串向右移动
}
if(j>T.length)
return i - T.length; //匹配成功
else
return 0; //没有找到对应的字符串
}
比如,Pj处失配,绿色的是Pj,则我们可以确定P1…Pj-1是与Si…Si+j-2相对应的位置一一相等的
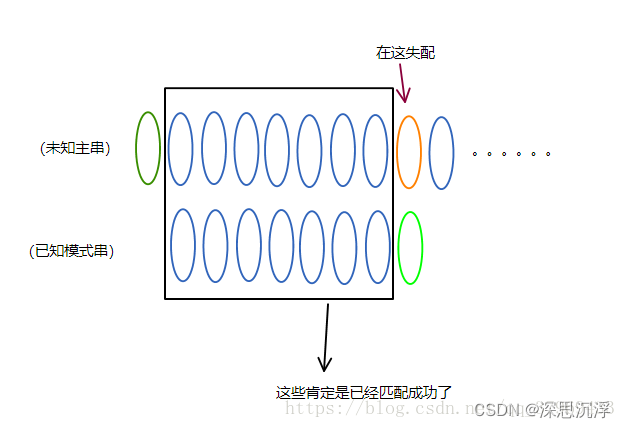
由于失配前面部分已经完全匹配了,此时应该考虑如何在主串中的 i不回溯的情况下只回溯模式串中的 j
此时应该向右边移动模式串直到碰到模式串在失配前的部分模式串与主串在失配前对应数量的部分 对应
即可完成主串中的i不回溯的要求。
每次移动多少次模式串达到 模式串在失配前的部分模式串与主串在失配前对应数量的部分 对应 的要求(及此刻j对应模式串的那个位置),此时应引入的next数组值
求Next数组的方法:
动图解析:

求模式串j的next数组时候前两的的next数组对应的值为固定值:0、1
串的前缀:包含第一个字符,且不包含最后一个字符的子串
的的后缀:包含最后一个字符,且不包含第一个字符的子串
next[j] = s(前后缀最长相等的最大长度) + 1
公式:

代码:
//求模式串T的next数组
void get_next(SString T,int next[])
{
int i =1 ,j = 0; //i用来标识判断到数组的第几个元素,j用来存储于next数组中的元素
next[1] = 0; //next[1]恒为0,与模式串种类无关
while(i<T.length) //后缀下标不能超出模式串的长度
{
if(j==0||T.ch[i]==T.ch[j])//j == 0 next数组中第一个元素 T.ch[i]==T.ch[j] p(i)==p(j)及元素相同,则next[i+1] = next[i] + 1
{
++i;
++j;
next[i] = j; //设置i元素的next数组对应的值
}
else //否则令j = next[j],循环继续
j = next[j];
}
}

代码讲解视频:KMP算法之求next数组代码讲解_哔哩哔哩_bilibili
文章推荐:(21条消息) 算法:next数组的求法详解_demon_倔强青铜的博客-CSDN博客_next数组
思路分析:
两点定理:
1、next[i+1]的最大值为next[i]+1
2、
如果p(i)==p(next[i]),那么next[i+1]可能的值为next[i]+1
如果p(i) !=p(next[i]),那么next[i+1]可能的次大值为next[next[i]]+1,以此类推即可求出next[i+1]
我们能确定next数组第一二位一定分别为0,1,后面求解每一位的next值时,根据前一位进行比较。
从第三位开始,将前一位与其next值对应的内容进行比较,
如果相等,则该位的next值就是前一位的next值加上1;
如果不等,向前继续寻找next值对应的内容来与前一位进行比较,
直到找到某个位上内容的next值对应的内容与前一位相等为止,
则这个位对应的值加上1即为需求的next值;
如果找到第一位都没有找到与前一位相等的内容,那么求解的位上的next值为1。

切记:不是左右对称,两个都是从左到右开始比较
KMP算法优化:

可以看出 l 和P(next[4])对比不匹配,然后再和p(nextp[next[4]])对比也就是和p(next[1])对比也不匹配,进行了一次五意义的对比。
求nextval数组的方法
根据next中的两点定理可以知道next数组中元素p(i)相等的元素对比结果一致,则nextval数组相比于next数组应该把重复的元素的nextval设为相同
//求模式串T的nextval数组
void get_next(SString T, int next[])
{
int i = 1, j = 0; //i用来标识判断到数组的第几个元素,j用来存储于next数组中的元素
next[1] = 0; //next[1]恒为0,与模式串种类无关
while (i < T.length) //后缀下标不能超出模式串的长度
{
if (j == 0 || T.ch[i] == T.ch[j])//j == 0 next数组中第一个元素 T.ch[i]==T.ch[j] p(i)==p(j)及元素相同,则next[i+1] = next[i] + 1
{
++i;
++j;
if (T.ch[i] != T.ch[j])
next[i] = j; //设置i元素的next数组对应的值
else
next[i] = next[j];
}
else //否则令j = next[j],循环继续
j = next[j];
}
}
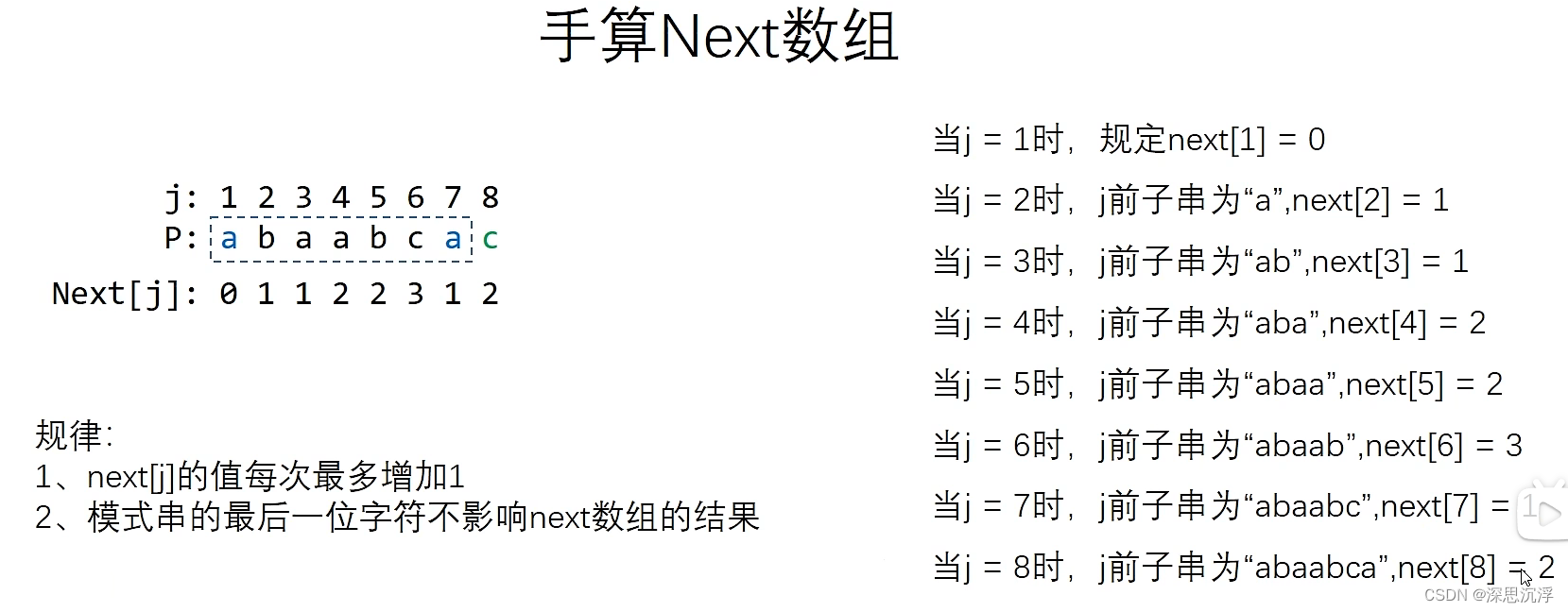
举例:若给出a b a a b c a c则对应的next数组和nextval数组为
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
|---|---|---|---|---|---|---|---|---|
| p | a | b | a | a | b | c | a | c |
| next | 0 | 1 | 1 | 2 | 2 | 3 | 1 | 2 |
| nextval | 0 | 1 | 0 | 2 | 1 | 3 | 0 | 2 |
注意:手写时候p4的nextval[4]应为0但是代码多比较了一次nextval[2],此处还没想好好的解决办法
KMP算法的主要在当前对文本串和模式串检索的过程中,若出现了不匹配,如何充分利用已经匹配的部分。
该算法较BF算法有较大改进,主要是消除了主串指针的回溯,从而使算法效率有了某种程度的提高。
但是前提是模式串中前后存在元素相同的部分,及前缀和后缀相同,如果不存在或者存在少的情况下KMP算法和BF算法时间上消耗差不多