目录
一、多表查询

1、概述
①、介绍
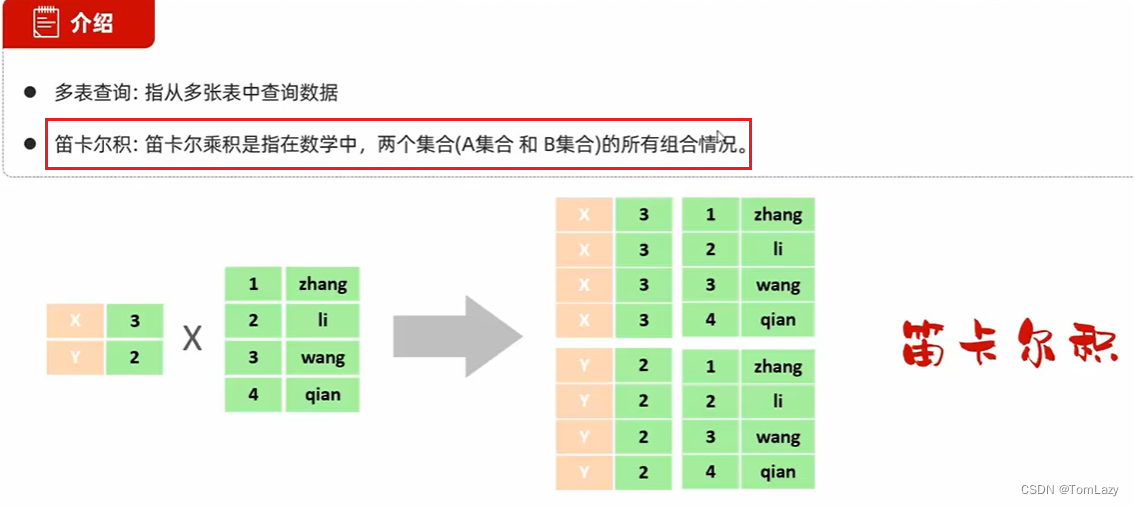
示例:

查询结果:17 * 5 = 85条数据
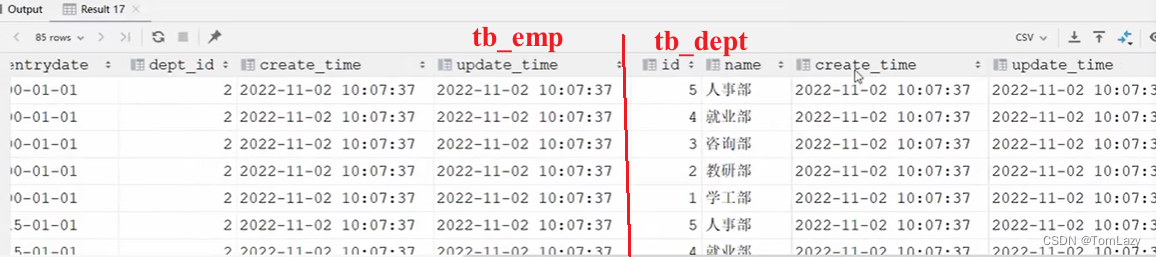
但这样查询会造成笛卡尔积现象。
②、分类

2、内连接查询(仅包含交集部分)
①、语法

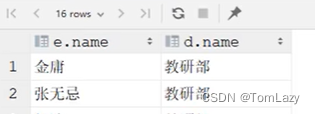
②、示例
| 隐式内连接:
查询结果:
|
| 显式内连接:[inner]可省略
查询结果:
|




| 但由于有时候有的表名会比较长,且难以记住,这时,我们就可以通过起别名的方式来简化表名: |
|
查询结果:
那么需要注意的是,一旦给表起了别名,那么后面在指定字段名的时候,就不能使用表名了,而是应该使用别名 |

3、外连接查询
①、语法

②、示例
| 左外连接:(在真实开发中,一般都使用左外连接,因为右外也可以改成左外) |
|
查询结果:(会完全包含左表数据)
|


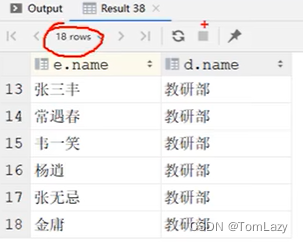
| 右外连接: |
|
查询结果:(会完全包含右表数据)
|

| 思考:是否可以把右外连接的写法改成左外连接的写法? |
| 答案:可以!只需要把两个表调个个
|

4、子查询
①、概述

②、分类

③、标量子查询(子查询返回的结果为一个值)

| 标量子查询案例:
|
| 分解成两步:
将两步合并:
查询结果:
|



|
| 分解成两步:
将两步合并:
查询结果:
|



④、列子查询

| 列子查询示例:
|
| 分解成两步:
a步的返回结果:(列子查询,返回的结果是一列)
将两步合并:
查询结果:
|

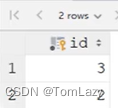


⑤、行子查询

| 行子查询示例:
|
| 分解成两步:
a步的返回结果:(行子查询,返回结果是一行)
将两步合并:(需要用 and 连接两个子查询条件)
查询结果:
但这样合并的写法并不优雅与高效,因此我们可以进行对其进行下列优化:
最终写法:
|

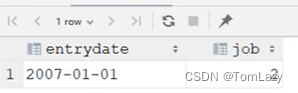




⑥、表子查询

| 表子查询示例:
|
| 分解成两步:
a步的返回结果:(表子查询,返回结果多行多列)
b步的返回结果:(将a步的返回结果作为一个临时表来进行查询)
|


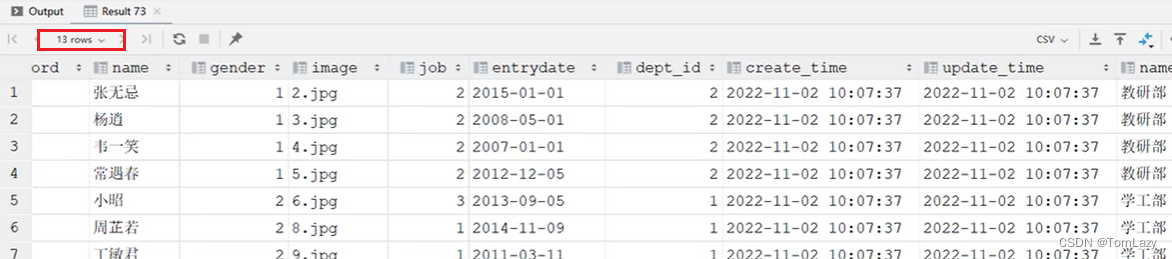
5、案例
①、需求
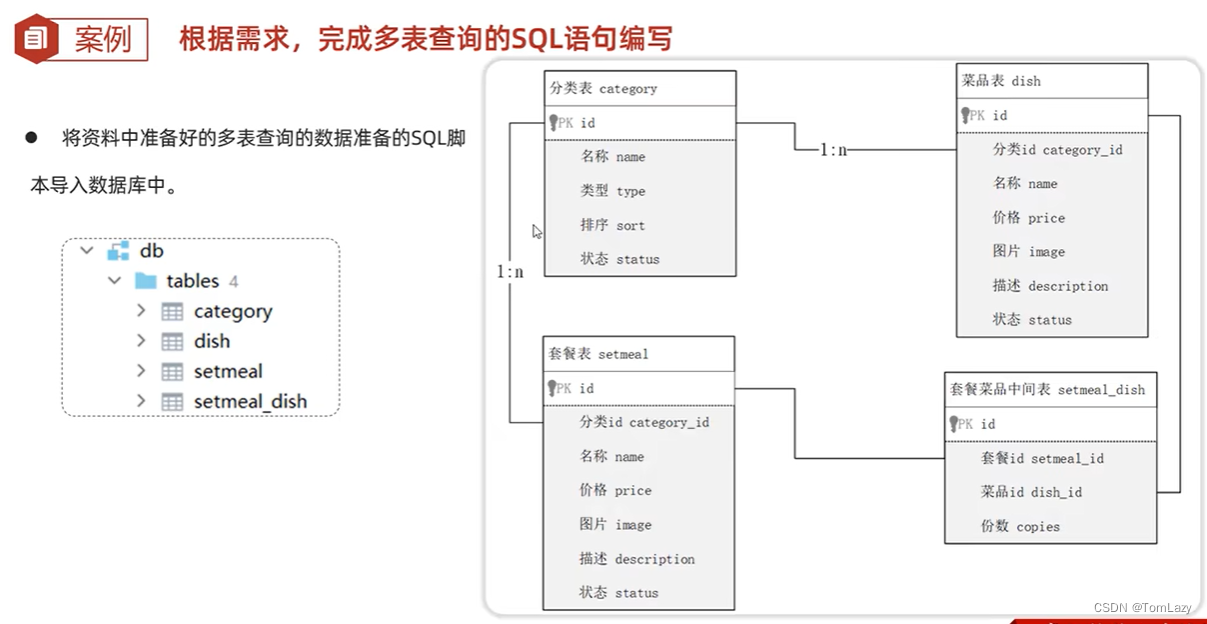
②、案例实现

| 需求1:
|
| 需求2:
|
| 需求3:(分组聚合)
|
| 需求4:(分组聚合)
|
| 需求5:
|
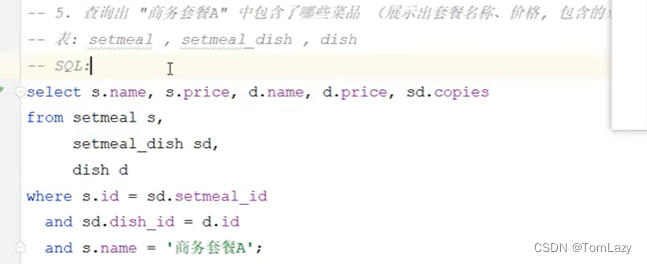
| 需求6:(子查询)
|




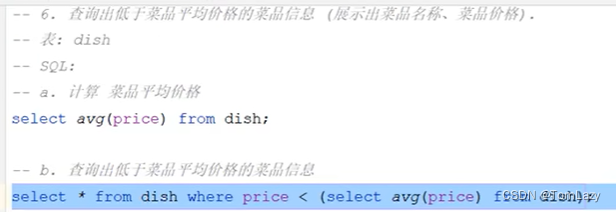
6、小结

二、事务
|
|
|
|
|
而要想解决这一类问题,我们就可以通过数据库当中的事务来进行解决 |




1、介绍 & 操作
①、概念

示例:

注意事项:(由于MySQL中的事务默认是自动提交的,当执行一条DML语句,MySQL会立刻提交。也就是,以上述示例为例,这两条SQL语句属于两个不同的事务)

②、操作

示例:(一旦出现异常就使用 rollback 操作恢复数据,从而保证在操作前后,数据是一致的)
| 执行语句:
|

2、四大特性(ACID)

3、小结

三、索引
一旦遇到数据量很大的数据表时,再对其进行任意的select简单查询,都会耗时很长
| 示例:我们在一个具有600万大小的数据表中查询 sn 为“100000003145003”的数据
|
| 耗时:13 s 306 ms
|

数据量越大,查询效率越低,那么我们就要对其进行优化,从而提高它查询效率,这时候就用到了索引。
| 建立索引:
|
| 耗时:(虽然建立索引的耗时也很长,但是我们只需要一次建立,之后就可以直接使用了)
|
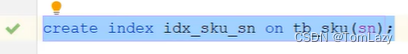

| 当建立完索引以后,我们再次执行一开始的查询语句:
|
| 耗时:6 ms
|



1、索引介绍

①、有无索引的区别
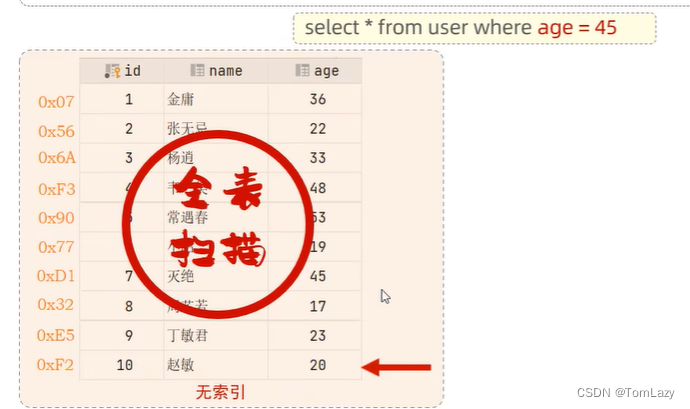
| 没有索引,select是怎么查找的? |
| 从头开始,全表扫描(数据效率非常低,且数据量越大,效率越低)
|
| 有索引:(树形结构——以二叉搜索树为例,非MySQL索引的真实数据结构) |
|
|

②、优缺点

2、索引结构
①、普通结构
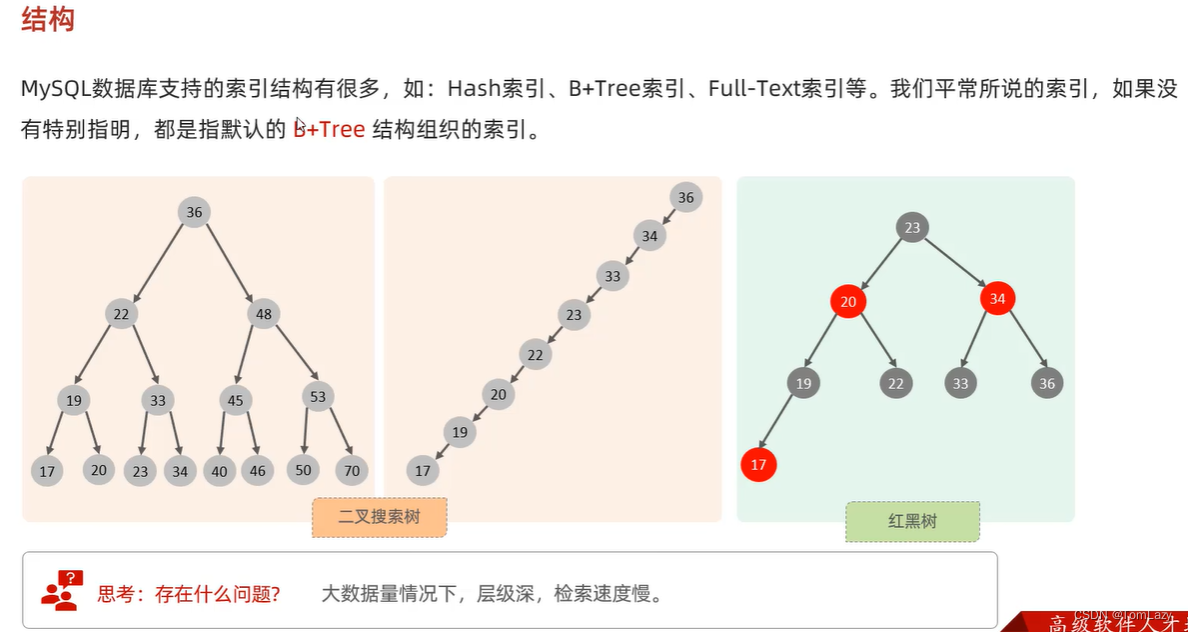
②、B+树(多路平衡搜索树)
所有的数据都只在叶子节点中保存,且所有的Key也都会在叶子节点中出现,非叶子节点只是为了检索数据

3、语法
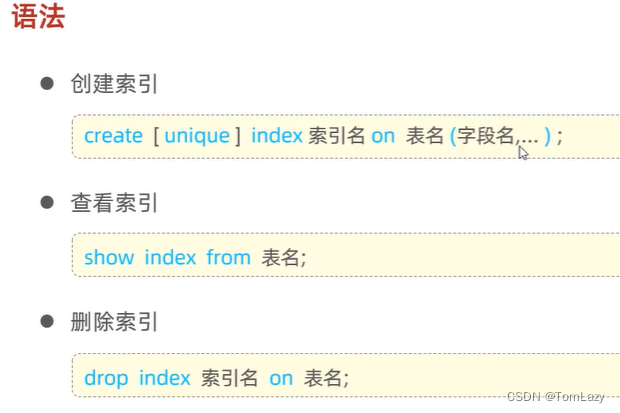

示例:
| 创建:
|
| 查询:
返回了3条记录:(PRIMARY -- 默认创建的主键索引 username字段上定义了唯一约束,一旦添加了唯一约束,就相当于定义了一个唯一索引)
|
| 删除:
效果展示:
|







4、小结
