该算法的原理大家可以去自行寻找,一般是与k-means进行比较。文章提供了一个KMedoid类,能够实现聚类且将相关的样本输出到excel文件。
因为k-medoid(k中心点)聚类算法是无监督的机器学习算法,一般需要根据聚类结果和样本实际特征进行对比,从而人工解释每一个类的特征是什么。
1、KMedoid类代码
这个代码是我网上搜集得到,在此基础上我添加了新的功能,即:将每一个簇的样本进行统计并输出到excel文件。
from matplotlib import pyplot
import numpy as np
import random
import pandas as pd
class KMediod():
"""
实现简单的k-medoid算法
"""
def __init__(self, data:np.ndarray, k_num_center:int):
self.k_num_center = k_num_center
self.data = data
self.centers=None
self.target=None
self.container=[]
self.df=None
self.dic={}
def ou_distance(self, x:int, y):
# 定义欧式距离的计算
return np.sqrt(sum(np.square(x - y)))
def run_k_center(self, func_of_dis):
"""
选定好距离公式开始进行训练
:param func_of_dis:
:return:
"""
print('初始化', self.k_num_center, '个中心点')
indexs = list(range(len(self.data)))
random.shuffle(indexs) # 随机选择质心
init_centroids_index = indexs[:self.k_num_center]
centroids = self.data[init_centroids_index, :] # 初始中心点
# 确定种类编号
levels = list(range(self.k_num_center))
print('开始迭代')
sample_target = []
if_stop = False
while(not if_stop):
if_stop = True
classify_points = [[centroid] for centroid in centroids]
sample_target = []
# 遍历数据
for sample in self.data:
# 计算距离,由距离该数据最近的核心,确定该点所属类别
distances = [func_of_dis(sample, centroid) for centroid in centroids]
cur_level = np.argmin(distances)
sample_target.append(cur_level)
# 统计,方便迭代完成后重新计算中间点
classify_points[cur_level].append(sample)
# 重新划分质心
for i in range(self.k_num_center): # 几类中分别寻找一个最优点
distances = [func_of_dis(point_1, centroids[i]) for point_1 in classify_points[i]]
now_distances = sum(distances) # 首先计算出现在中心点和其他所有点的距离总和
for point in classify_points[i]:
distances = [func_of_dis(point_1, point) for point_1 in classify_points[i]]
new_distance = sum(distances)
# 计算出该聚簇中各个点与其他所有点的总和,若是有小于当前中心点的距离总和的,中心点去掉
if new_distance < now_distances:
now_distances = new_distance
centroids[i] = point # 换成该点
if_stop = False
print('结束')
return sample_target,centroids
#sample_target记录的是每个样本所属的类别
def get_groups(self):
for l in range(self.k_num_center):
self.container.append([])
for l in range(self.k_num_center):
for item in self.target:
if l==item:
self.container[l].append(data[item])
def toexcel(self):
self.get_groups()
dic=dict()
for o in range(self.centers.shape[0]):
key=str(tuple(self.centers[o]))
dic[key]=self.container[o]
self.dic=dic
self.df=pd.DataFrame(pd.DataFrame.from_dict(dic, orient='index').values.T, columns=list(dic.keys()))
self.df.to_excel('result.xlsx')
def run(self):
predict,self.centers= self.run_k_center(self.ou_distance)
self.target=predict
return predict2、使用方法
①准备好数据,确保数据格式正确,数据格式必须是二维的,即np.ndarray,且不能包含表头,下图中的数据shape为(10,3)。

②建立KMedoid类的实例对象
ins= KMediod(data, k_num_center=5)#data是数据,k_num_center是簇的数量再运行下面的代码即可:
result=ins.run() pyplot.scatter(data[:, 0], data[:, 1], c=result) pyplot.show() ins.toexcel()#将每一个簇的簇心和属于该簇的所有样本输出到excel
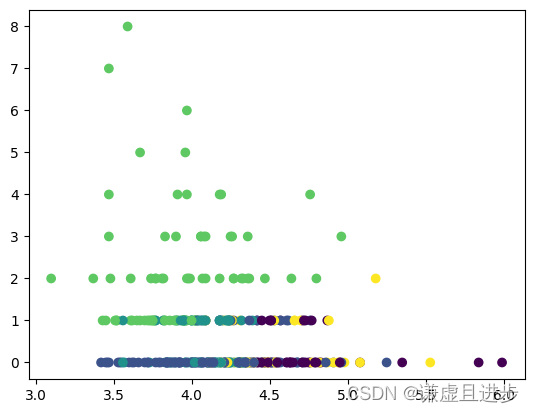
3、效果图
下图是平面图,实际上样本是三维特征的,在立体图中效果更好。