前言
前面已经将结果很多推荐系统+深度学习的基础模型了,从这篇文章开始也进入到了注意力机制的章节。在AFM开始,大家都不再局限于将特征进行两两交互问题上面,而是开始探索一些新的结构。"Attention Mechanism"这个词现在已经不是新东西了,它来源于人类自然的选择注意习惯, 最典型的例子就是我们观察一些物体或者浏览网页时,不会聚焦于整个物体或者页面,而是会选择性的注意某些特定区域,忽视一些区域,往往会把注意力放到某些显眼的地方。 如果在建模过程中考虑到注意力机制对预测结果的影响,往往效果会更好。 近年来,注意力机制在各个领域大放异彩,比如NLP,CV等, 2017年开始,推荐领域也开始尝试将注意力机制加入模型,比如今天的AFM。
今天也是先介绍一些推荐系统+注意力机制的开胃菜AFM,首先还是看一下王喆老师的《深度学习推荐系统》已经梳理好了的知识体系。

1、AFM模型
AFM(Attentional Factorization Machines)模型也是2017年由浙江大学和新加坡国立大学研究员提出的一个模型,AFM模型其实就是从前面讲解过的NFM模型的进化升级版, 该模型和NFM模型结构上非常相似, 算是NFM模型的一个延伸,在NFM中, 不同特征域的特征embedding向量经过特征交叉池化层的交叉,将各个交叉特征向量进行“加和”, 然后后面跟了一个DNN网络,但是NFM中的加和池化,它相当于“一视同仁”地对待所有交叉特征, 没有考虑不同特征对结果的影响程度,作者认为这可能会影响最后的预测效果, 因为不是所有的交互特征都能够对最后的预测起作用。 没有用的交互特征可能会产生噪声。或者说加大对预测结果重要的特征,抑制噪声特征。
举个例子来说如果应用场景是预测一位男性用户是否购买一款键盘的可能性, 那么“性别=男且购买历史包含鼠标”这个交叉特征, 很可能比“性别=男且用户年龄=30”这一个交叉特征重要。所以对于NFM来说对所有的二阶交叉特征进行无差别加和池化就不是很合理了。因此引入注意力机制就显得非常合理!
首先来看一下AFM的模型架构:
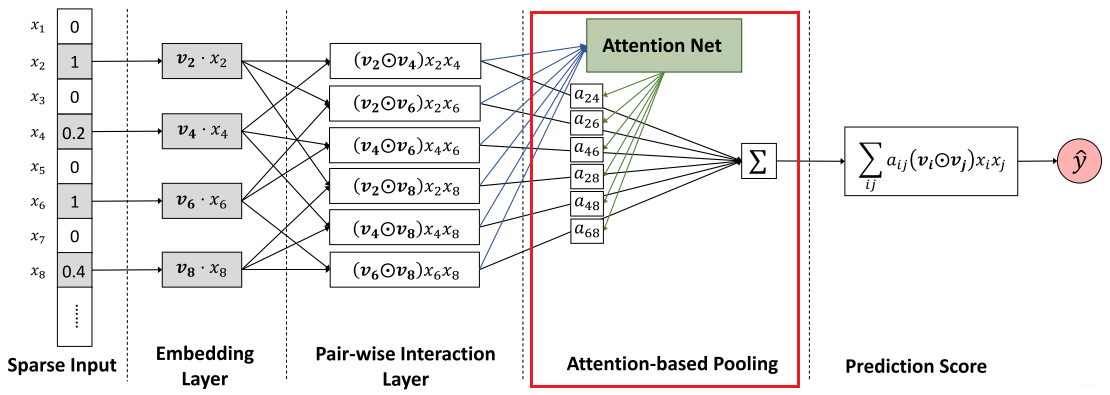
可以看到的是,在这个模型之中并没有DNN模块,但是保存了NFM的二阶交叉特征池化层。
2、二阶交叉池化层
这里的二阶交叉池化层和前面讲过的NFM是一模一样的,在这里我也就不多做叙述了。但是在这里需要注意的是Attention的加入,并不是单单给某一个二维交叉特征一个权重,这样子的话对于未在训练数据中出现的交叉特征就无法进行权重赋予。所以在上图中也可以看到Attention是一个Net的形式给出。也就是用了一个MLP将注意力分数进行参数化。
该注意力网络的结构是一个简单的单全连接层加softmax输出层的结构, 数学表示如下:
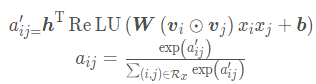
学习的模型参数是特征交叉层到注意力网络全连接层的权重矩阵W 和偏置向量b 以及全连接层到softmax输出层的权重向量h ,这三个的维度分别是 ,
,
, 这里的t tt表示注意力网络隐藏层的单元个数。
就表示了每个交互特征的重要性程度,通过softmax之后, 这是一个0-1之间的数值了。注意力网络与整个模型一起参与反向传播过程, 得到最终的权重参数。
基于注意力的池化层的输出是一个k kk维向量,该向量是所有特征交互向量根据重要性程度进行了区分了之后的一个聚合效果,然后我们将其映射到最终的预测得分中。所以AFM的总体公式如下:

关于模型的学习部分, 当然是根据不同的任务来了, 这个模型也是回归任务和分类任务皆可, 并且相对于NFM, 目前上面暂时没有用到DNN网络来学习高阶的交互了, 这个暂定为了作者未来的研究工作。关于AFM的工作就这些了,也是很简单的(绝不是我在水文章~)。
3、pytorch复现
class Dnn(nn.Module):
def __init__(self, hidden_units, dropout=0.):
"""
hidden_units: 列表, 每个元素表示每一层的神经单元个数, 比如[256, 128, 64], 两层网络, 第一层神经单元128, 第二层64, 第一个维度是输入维度
dropout = 0.
"""
super(Dnn, self).__init__()
self.dnn_network = nn.ModuleList([nn.Linear(layer[0], layer[1]) for layer in list(zip(hidden_units[:-1], hidden_units[1:]))])
self.dropout = nn.Dropout(dropout)
def forward(self, x):
for linear in self.dnn_network:
x = linear(x)
x = F.relu(x)
x = self.dropout(x)
return x
class Attention_layer(nn.Module):
def __init__(self, att_units):
"""
:param att_units: [embed_dim, att_vector]
"""
super(Attention_layer, self).__init__()
self.att_w = nn.Linear(att_units[0], att_units[1])
self.att_dense = nn.Linear(att_units[1], 1)
def forward(self, bi_interaction): # bi_interaction (None, (field_num*(field_num-1)_/2, embed_dim)
a = self.att_w(bi_interaction) # (None, (field_num*(field_num-1)_/2, embed_dim)
a = F.relu(a) # (None, (field_num*(field_num-1)_/2, embed_dim)
att_scores = self.att_dense(a) # (None, (field_num*(field_num-1)_/2, 1)
att_weight = F.softmax(att_scores, dim=1) # (None, (field_num*(field_num-1)_/2, 1)
att_out = torch.sum(att_weight * bi_interaction, dim=1) # (None, embed_dim)
return att_out
class AFM(nn.Module):
def __init__(self, feature_columns, mode, hidden_units, att_vector=8, dropout=0.5, useDNN=False):
"""
AFM:
:param feature_columns: 特征信息, 这个传入的是fea_cols array[0] dense_info array[1] sparse_info
:param mode: A string, 三种模式, 'max': max pooling, 'avg': average pooling 'att', Attention
:param att_vector: 注意力网络的隐藏层单元个数
:param hidden_units: DNN网络的隐藏单元个数, 一个列表的形式, 列表的长度代表层数, 每个元素代表每一层神经元个数, lambda文里面没加
:param dropout: Dropout比率
:param useDNN: 默认不使用DNN网络
"""
super(AFM, self).__init__()
self.dense_feature_cols, self.sparse_feature_cols = feature_columns
self.mode = mode
self.useDNN = useDNN
# embedding
self.embed_layers = nn.ModuleDict({
'embed_' + str(i): nn.Embedding(num_embeddings=feat['feat_num'], embedding_dim=feat['embed_dim'])
for i, feat in enumerate(self.sparse_feature_cols)
})
# 如果是注意机制的话,这里需要加一个注意力网络
if self.mode == 'att':
self.attention = Attention_layer([self.sparse_feature_cols[0]['embed_dim'], att_vector])
# 如果使用DNN的话, 这里需要初始化DNN网络
if self.useDNN:
# 这里要注意Pytorch的linear和tf的dense的不同之处, 前者的linear需要输入特征和输出特征维度, 而传入的hidden_units的第一个是第一层隐藏的神经单元个数,这里需要加个输入维度
self.fea_num = len(self.dense_feature_cols) + self.sparse_feature_cols[0]['embed_dim']
hidden_units.insert(0, self.fea_num)
self.bn = nn.BatchNorm1d(self.fea_num)
self.dnn_network = Dnn(hidden_units, dropout)
self.nn_final_linear = nn.Linear(hidden_units[-1], 1)
else:
self.fea_num = len(self.dense_feature_cols) + self.sparse_feature_cols[0]['embed_dim']
self.nn_final_linear = nn.Linear(self.fea_num, 1)
def forward(self, x):
dense_inputs, sparse_inputs = x[:, :len(self.dense_feature_cols)], x[:, len(self.dense_feature_cols):]
sparse_inputs = sparse_inputs.long() # 转成long类型才能作为nn.embedding的输入
sparse_embeds = [self.embed_layers['embed_'+str(i)](sparse_inputs[:, i]) for i in range(sparse_inputs.shape[1])]
sparse_embeds = torch.stack(sparse_embeds) # embedding堆起来, (field_dim, None, embed_dim)
sparse_embeds = sparse_embeds.permute((1, 0, 2))
# 这里得到embedding向量之后 sparse_embeds(None, field_num, embed_dim)
# 下面进行两两交叉, 注意这时候不能加和了,也就是NFM的那个计算公式不能用, 这里两两交叉的结果要进入Attention
# 两两交叉enbedding之后的结果是一个(None, (field_num*field_num-1)/2, embed_dim)
# 这里实现的时候采用一个技巧就是组合
#比如fild_num有4个的话,那么组合embeding就是[0,1] [0,2],[0,3],[1,2],[1,3],[2,3]位置的embedding乘积操作
first = []
second = []
for f, s in itertools.combinations(range(sparse_embeds.shape[1]), 2):
first.append(f)
second.append(s)
# 取出first位置的embedding 假设field是3的话,就是[0, 0, 0, 1, 1, 2]位置的embedding
p = sparse_embeds[:, first, :] # (None, (field_num*(field_num-1)_/2, embed_dim)
q = sparse_embeds[:, second, :] # (None, (field_num*(field_num-1)_/2, embed_dim)
bi_interaction = p * q # (None, (field_num*(field_num-1)_/2, embed_dim)
if self.mode == 'max':
att_out = torch.sum(bi_interaction, dim=1) # (None, embed_dim)
elif self.mode == 'avg':
att_out = torch.mean(bi_interaction, dim=1) # (None, embed_dim)
else:
# 注意力网络
att_out = self.attention(bi_interaction) # (None, embed_dim)
# 把离散特征和连续特征进行拼接
x = torch.cat([att_out, dense_inputs], dim=-1)
if not self.useDNN:
outputs = F.sigmoid(self.nn_final_linear(x))
else:
# BatchNormalization
x = self.bn(x)
# deep
dnn_outputs = self.nn_final_linear(self.dnn_network(x))
outputs = F.sigmoid(dnn_outputs)
return outputs