1、背景情况
业务使用的索引进行了一个切换,从老索引(老集群)切换到了新索引(新集群),更改了主分片数目,其他条件未修改。切换当天研发与测试人员都测试通过。
2、问题描述
索引切换的第二天,研发同学反馈查询使用报错:
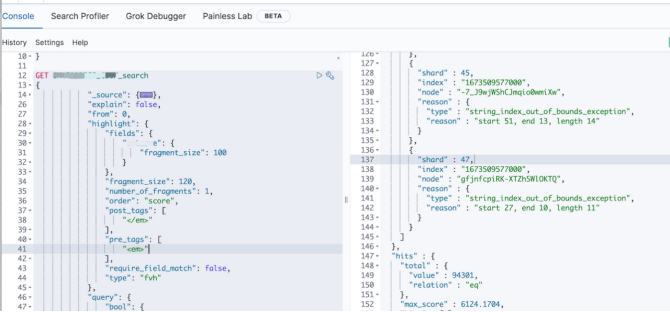
经过初步调试,发现报错的内容是在 highlight 模块的 fvh 类型使用,这个操作主要查询了字段 a-name。
这里补充一下 highlight 的使用类型知识。
highlight 的高亮处理有三种 unified/plain/fvh,在大文本下比较合适的是 fvh。
fvh Highlighter 会直接利用 index 的时候创建的 term vector 来得到高亮片段匹配的查询分词,这里就需要一个 mapping 的配置 "term_vector" : "with_positions_offsets"。
具体的 highlight type 属性可以参照官方文档
https://www.elastic.co/guide/en/elasticsearch/reference/current/highlighting.html)
同时,发现了 github 上这个报错的源码注释:
https://github.com/apache/lucene/blob/d5d6dc079395c47cd6d12dcce3bcfdd2c7d9dc63/lucene/highlighter/src/java/org/apache/lucene/search/vectorhighlight/FastVectorHighlighter.java
可以肯定的是 term vector 的计算导致了这个报错。
还好老索引还在,term vector 也可以使用 api 去查看存储的信息内容。
GET 索引名/_termvectors/id?fields=字段名新索引中的搜索关键字如下所示:

旧索引中的搜索关键字如下所示:

可以明显看到在新老索引里,存的position offset 这两个信息是完全不一样的。
而尝试通过 termvector 去实时(on the fly https://www.elastic.co/guide/en/elasticsearch/reference/current/docs-termvectors.html#docs-termvectors-api-generate-termvectors)计算,还是得到的同样的两个结果。
现在的问题:相同的文档信息出现了不同的 term vector 结果。
3、排查方向
和研发同学沟通讨论后,主要进行了两方面的排查:
1.在新老集群上进行索引配置的复制,首先排除集群环境的问题。
2.索引有不少自定义的分词器和复杂的参数使用,对索引配置进行进一步分析。
新建测试索引后,我们发现老集群上的测试索引也有这样的错误。且测试索引的 termvector 信息与新索引信息一致。

因此可以排除集群环境的问题。
同时研发同学注意到,termvector 信息中出现了本身文档外的信息:
“text”:["某某科技公司"]
“term_vectors":["mou","ke","ji","gong","si","某","科技","公司"]而多余的 term vector 信息则来自于另一个存储拼音的字段 b-name,该字段同时设置了 copy to 属性,把内容复制给了问题字段 a-name。

这时,研发同学发现了问题:在新旧索引切换的过程中,客户端也进行了更换。之前是 nodejs JSON上传,nodejs的json是有序的,而切换后的客户端使用的是 golang,golang里面的jsoniter不会有序,排列随机。
因此不同排序的 json 字段在 copy to 的复杂使用下,产生了不同的 term vector。对此进行了测试索引的故障复现。测试数据如下:
{
"b-name" : "mou mou ke ji gong si",
"a-name" : "某某科技公司",
}b-name 在 a-name 之前,term vector 如下:

字段进行调换后:
4、结论与复盘
实际过程中,我们排查的脑图如下:

图片建议放大查看
针对这个复杂的使用场景也是踩了不少坑。真的是魔鬼隐藏在细节里,json 字段顺序的问题也会导致这样晦涩难找的 bug。
同时也遗留了个小问题:term vector 的 api (on the fly)并不能复现这个场景的问题,是因为计算的是已写入lucene文件的数据,还是模拟的数据写入?那是不是功能的bug,还是理解有差?
5、作者介绍
金多安,Elastic 认证工程师,Elastic资深运维工程师,死磕Elasticsearch知识星球嘉宾,星球Top活跃技术专家,Elastic中文社区日报责任编辑
推荐阅读

更短时间更快习得更多干货!
和全球 近1900+ Elastic 爱好者一起精进!

比同事抢先一步学习进阶干货!