目录
一、下载m3u8文件
from Crypto.Cipher import AES
from Crypto.Util.Padding import pad
import requests
import asyncio
import aiohttp
import aiofiles
import os
def download_m3u8_file(url, name):
resp = requests.get(url)
with open(name, mode="wb") as f:
f.write(resp.content)二、下载视频
这是会有两种情况出现,给出的代码是第一种情况
情况一:
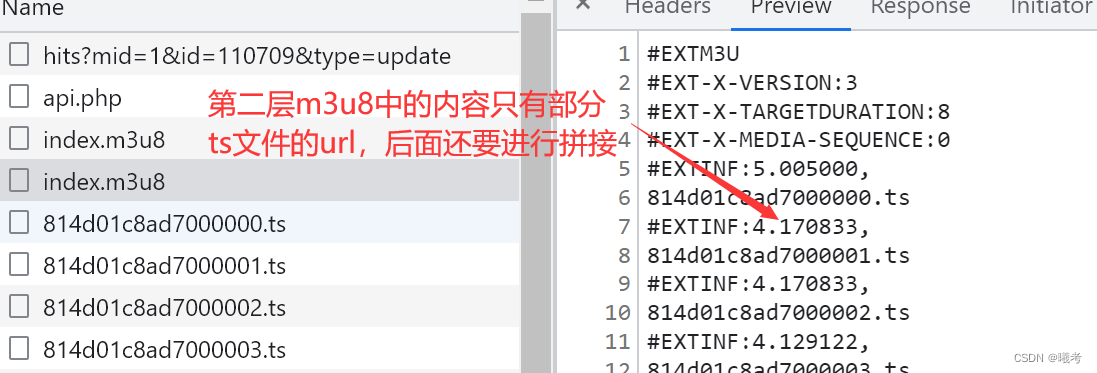
拼接下载ts视频片段用到url

情况二:

# 单个下载
async def download_ts(url, name, session):
async with session.get(url) as resp:
async with aiofiles.open(f"video/{name}", mode="wb") as f:
await f.write(await resp.content.read()) # 把下载到的内容写入到文件中
print(f"{name}下载完毕")
# 异步下载 速度快
async def aio_download(up_url):
tasks = []
async with aiohttp.ClientSession() as session: # 提前准备好session
async with aiofiles.open("movie_second_m3u8.txt", mode="r", encoding='utf-8') as f:
async for line in f:
if line.startswith("#"):
continue
line = line.strip("/") # 去掉没用的空格和换行
line = line.strip()
# print(line)
# 拼接真正的下载ts路径
ts_url = up_url + line
line = ts_url.split("/")[-1]
# print(line) # 文件名称
# print(ts_url) # 下载的url
task = asyncio.create_task(download_ts(ts_url, line, session)) # 创建任务
tasks.append(task)
await asyncio.wait(tasks) # 等待任务结束三、如何合并视频
此处由于我直接使用os.system(f"copy /b {s} movie{j}.mp4")始终无法直接合并视频,所以我使用的是cmd合并视频,下面代码是把cmd合并视频所需要的命令写入到txt文件中去,再使用cmd合并视频,在cmd合并视频之前需要输入 cd 下载视频存放的路径
# 合并视频
def merge_ts():
# windows: copy /b 1.ts+2.ts+3.ts xxx.mp4
lst = []
i = 0
j = 0
path = r"爬取视频后下载的视频所在地址"
file_name_list = os.listdir(path)
with open("movie_second_m3u8.txt", mode="r", encoding="utf-8") as f:
for line in f:
if line.startswith("#"):
continue
line = line.strip("/")
line = line.strip()
line = line.split("/")[-1]
# 确保视频已经下载
if line in file_name_list:
lst.append(f"{line}")
i += 1
# 太长需要分次合并
# 最多合并300个 # 先分次合并出多个movie文件
if i > 300:
j += 1
s = "+".join(lst) # 1.ts 2.ts 3.ts
# print(s)
# 将下载所需的东西写入文件夹
with open(f"合并视频{j}.txt", mode="w", encoding="utf-8") as f:
f.write(f"copy /b {s} movie{j}.mp4")
lst = []
i = 0
print(f"合并视频{j}", "搞定!")
# 没有达到300部分的文件名字 写入合并视频{j+1}文件夹
else:
s = "+".join(lst)
with open(f"合并视频{j+1}.txt", mode="w", encoding="utf-8") as f:
f.write(f"copy /b {s} movie{j+1}.mp4")
print(f"合并视频{j+1}", "搞定!")
lst=[]
for i in range(1,j+2):
lst.append(f"movie{i}.mp4")
# print(lst)
s="+".join(lst)
# print(s)
# 最终合并所有的movie
with open(f"合并视频.txt", mode="w", encoding="utf-8") as f:
f.write(f"copy /b {s} movie.mp4")四、主函数
获取第一层m3u8的url

第一层m3u8下载得到的内容

获取第二层m3u8的url

if __name__ == '__main__':
first_url = input("请输入第一层m3u8下载地址:")
# 下载第一层m3u8文件
download_m3u8_file(first_url, "movie_m3u8.txt")
# 下载第二层m3u8文件
with open("movie_m3u8.txt", mode="r", encoding="utf-8") as f:
for line in f:
# 读取文件获得视频片段下载所需的url
if line.startswith("#"):
continue
else:
line = line.strip() # 去掉空白或者换行符
# 拼接第二层m3u8文件的下载地址
# split中的内容可能会有所不同 方法见图片解析
second_m3u8_url = first_url.split("index.m3u8")[0] + line
# print(second_m3u8_url)
download_m3u8_file(second_m3u8_url, "movie_second_m3u8.txt")
print("m3u8文件下载完毕")
# 每个ts文件下载地址的部分链接 后面还要进行拼接
second_m3u8_url_up = second_m3u8_url.split("index.m3u8")[0]
# 下载视频
loop = asyncio.get_event_loop()
loop.run_until_complete(aio_download(second_m3u8_url_up))
# 合并视频
merge_ts()