文章目录
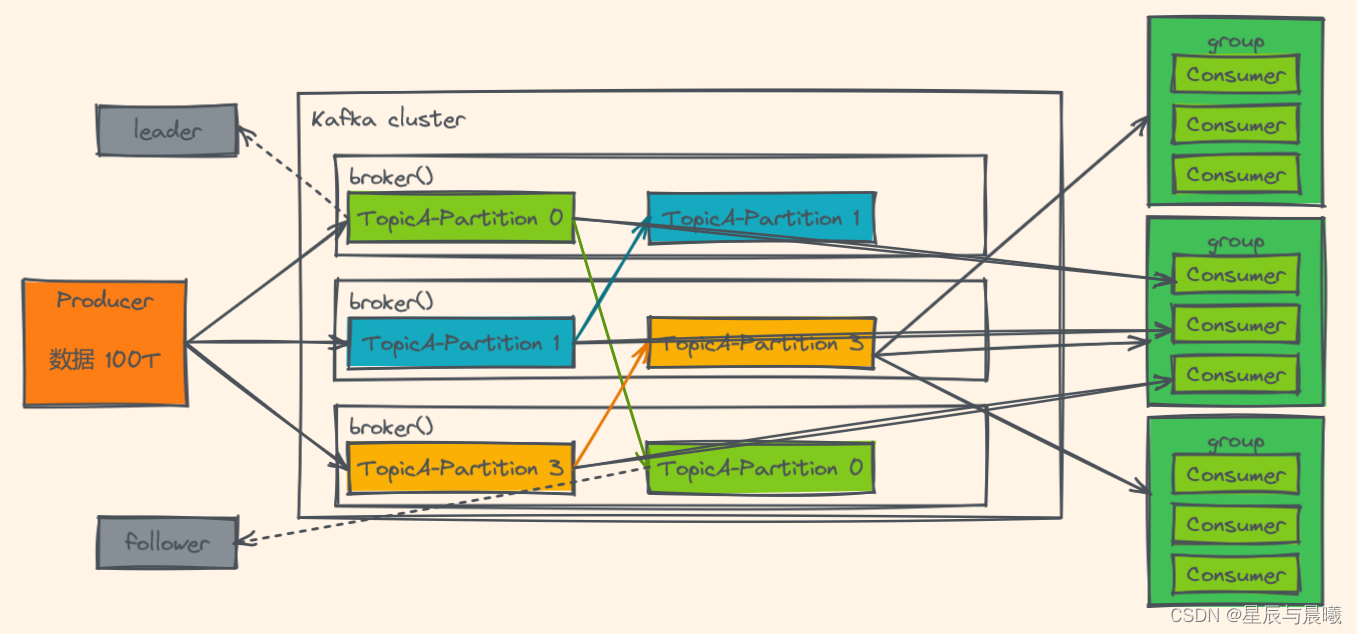
broker
- 一个 Kafka 的集群通常由多个 broker 组成,这样才能实现负载均衡、以及容错
- broker是无状态(Sateless)的,它们是通过ZooKeeper来维护集群状态
- 一个 Kafka 的 broker 每秒可以处理数十万次读写,每个broker都可以处理TB消息而不影响性能
zookeeper
- ZK用来管理和协调broker,并且存储了Kafka的元数据(例如:有多少topic、partition、consumer)
- ZK服务主要用于通知生产者和消费者 Kafka 集群中有新的 broker 加入、或者Kafka集群中出现故障的broker。
Kafka 现在已将ZooKeeper剥离,因为维护两套集群成本较高,社区就提出KIP-500就是要替换掉ZooKeeper的依赖。
producer(生产者)
- 生产者负责将数据推送给broker的topic
consumer(消费者)
- 消费者负责从broker的topic中拉取数据,并自己进行处理
consumer group(消费者组)
- consumer group是kafka提供的可扩展且具有容错性的消费者机制
- 一个消费者组可以包含多个消费者
- 一个消费者组有一个唯一的ID(group Id)
- 组内的消费者一起消费主题的所有分区数据
分区(Partitions)
- 在Kafka集群中,主题(Topic)被分为多个分区
副本(Replicas)
- 副本可以确保某个服务器出现故障时,确保数据依然可用
- 在Kafka中,一般都会设计副本的个数>1
主体(Topic)
- 主题是一个逻辑概念,用于生产者发布数据,消费者拉取数据。
- Kafka中的主题必须要有标识符,而且是唯一的,Kafka中可以有任意数量的主题,没有数量上的限制。
- 在主题中的消息是有结构的,一般一个主题包含某一类消息
- 一旦生产者发送消息到主题中,这些消息就不能被更新(更改)
偏移量(offset)
- offset记录着下一条将要发送给Consumer的消息的序号
- 默认Kafka将offset存储在ZooKeeper中
- 在一个分区中,消息是有顺序的方式存储着,每个在分区的消费都是有一个递增的id。这个就是偏移量offset。
- 偏移量在分区中才是有意义的。在分区之间,offset是没有任何意义的
Kafka支持有多个消费者同时消费一个主题中的数据。
Leader和Follower
在 Kafka 中,每个 topic 都可以配置多个分区以及多个副本。每个分区都有一个 leader 以及 0 个或者多个 follower,在创建 topic 时,Kafka 会将每个分区的 leader 均匀地分配在每个 broker 上。我们正常使用kafka是感觉不到leader、follower的存在的。但其实,所有的读写操作都是由leader处理,而所有的follower都复制leader的日志数据文件,如果leader出现故障时,follower就会被选举为leader。所以,可以这样说:
- Kafka中 的 leader 负责处理读写操作,而 follower 只负责副本数据的同步。
- 如果 leader 出现故障,其他 follower 会被重新选举为leader。
- follower 像一个 consumer 一样,拉取 leader 对应分区的数据,并保存到日志数据文件中。
Kafka的幂等性
拿 http 举例来说,一次或多次请求,得到地响应是一致的(网络超时等问题除外),换句话说,就是执行多次操作与执行一次操作的影响是一样的。
如果,某个系统是不具备幂等性的,如果用户重复提交了某个表格,就可能会造成不良影响。例如:用户在浏览器上点击了多次提交订单按钮,会在后台生成多个一模一样的订单。
在没有幂等性的时候:
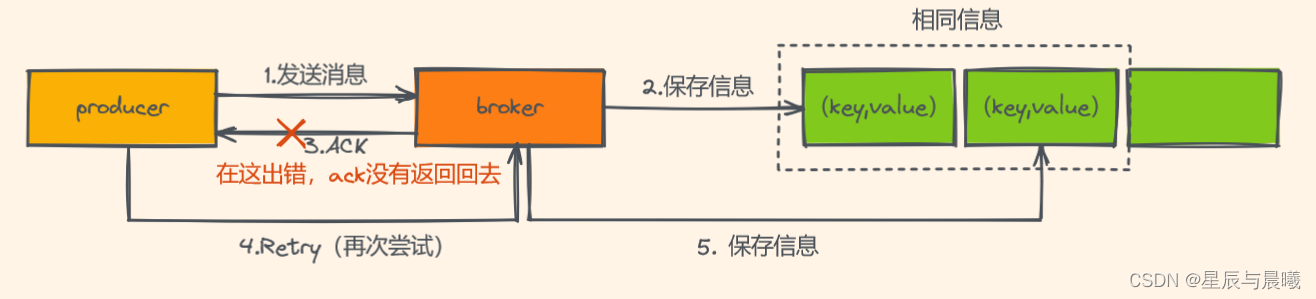
同一信息被重复保存。
所以为了实现生产者的幂等性,Kafka引入了 Producer ID(PID)和 Sequence Number的概念。
- PID:每个Producer在初始化时,都会分配一个唯一的PID,这个PID对用户来说,是透明的。
- Sequence Number:针对每个生产者(对应PID)发送到指定主题分区的消息都对应一个从0开始递增的Sequence Number。
Sequence Number在ACK 返回成功接收后,才会递增一下,而在broker当中若是查到当前Sequence Number的小于等于上一次,就选择不会保存。

Kafka的事务
Kafka的事务是2017年Kafka 0.11.0.0引入的新特性。类似于数据库的事务。
Kafka事务指的是生产者生产消息以及消费者提交 offset 的操作可以在一个原子操作中,要么都成功,要么都失败。尤其是在生产者、消费者并存时,事务的保障尤其重要。
Producer接口中定义了以下5个事务相关方法:
- initTransactions(初始化事务):要使用Kafka事务,必须先进行初始化操作;
- beginTransaction(开始事务):启动一个Kafka事务;
- sendOffsetsToTransaction(提交偏移量):批量地将分区对应的offset发送到事务中,方便后续一块提交;
- commitTransaction(提交事务):提交事务;
- abortTransaction(放弃事务):取消事务;