目前这个案例的效果特别不好,而且只能识别字母和数字
一、Demo运行
打开上篇中的OpenCV内容,找到Demo,再找到OCR.Alphabet这个Demo,双击进入Scene。
运行,你会发现这个检测结果太棒了。

二、代码解读
在这里代码就不发了,解读一下整体的逻辑关系。
1.AlphabetOCRScene(挂载在RawImage上)
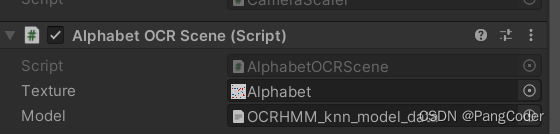
它有两个输入,一个是测试图片,另一个是已经训练好的knn模型。如下
public UnityEngine.Texture2D texture;
public UnityEngine.TextAsset model;主要是依靠AlphabetOCR这个类实现检测,创建这个类需要输入模型的bytes。因此模型文件原本格式是xml,在Unity里需要把xml后缀名改成bytes,然后拖动到Model栏里。
2.AlphabetOCR
它需要Model才能成功创建,因为OCRHMMDecoder的创建需要xml文件路径,为了能在安卓设备里使用OpenCV插件作者特意写了,一段转换函数,将bytes转换成xml文件加载,当初差点没看懂这个是干啥的。如下
public AlphabetOCR(byte[] model)
{
// use temporary file as OpenCV::Contrib::Text doesn not have in-memory reading functions
string folder = UnityEngine.Application.persistentDataPath;
string filename = null;
while (null == filename || System.IO.File.Exists(System.IO.Path.Combine(folder, filename)))
filename = System.IO.Path.GetRandomFileName() + ".xml";
// flush
var tempFile = System.IO.Path.Combine(folder, filename);
System.IO.File.WriteAllBytes(tempFile, model);
// read classifier callback and clean file
ocr = new OCRHMMDecoder.ClassifierCallback(tempFile, CvText.OCRClassifierType.KNN);
System.IO.File.Delete(tempFile);
}创建成功后,首先对图像进行灰度、滤波、二值化、找文字轮廓、获取RotatedRect、分割图像、矫正、最后进行分类检测。大致流程如下
const string vocabulary = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789";
int[] classes;//类别
double[] confidences;//准确度
OCRHMMDecoder.ClassifierCallback ocr = null;
ocr = new OCRHMMDecoder.ClassifierCallback(tempFile, CvText.OCRClassifierType.KNN);
ocr.Eval(二值化分割后图像, out classes, out confidences);
// process
if (confidences.Length > 0)
{
var unit = new RecognizedLetter();
unit.Data = vocabulary[classes[0]].ToString();
unit.Confidence = confidences[0];
}