目录
(3)transformation算子——flatMap()
(6)transformation算子——intersection()
(7)transformation算子——distinct()
(19)PariRDD算子(transformation算子)——mapValues和flatMapValues()
(20)PariRDD算子(transformation算子)——reduceByKey()
(21)PariRDD算子(transformation算子)——groupByKey()
(22)PariRDD算子(transformation算子)——sortByKey()
(23)PariRDD算子(action算子)——collectAsMap()
(24)PariRDD算子(action算子)——countByKey()
一、spark RDD
(1)RDD简介
RDD(Resilient Distributed Datasets),弹性分布式数据集,是分布式内存的一个抽象概念。RDD提供了一种高度受限的共享内存模型,即RDD是只读的记录分区的集合,只能通过在其他RDD执行确定的转换操作(如map、join和group by)而创建,然而这些限制使得实现容错的开销很低。RDD具备像MapReduce等数据流模型的容错特性,并且允许开发人员在大型集群上执行基于内存的计算。RDD是只读的、分区记录的集合。RDD只能基于在稳定物理存储中的数据集和其他已有的RDD上执行确定性操作来创建。
(2)算子简介
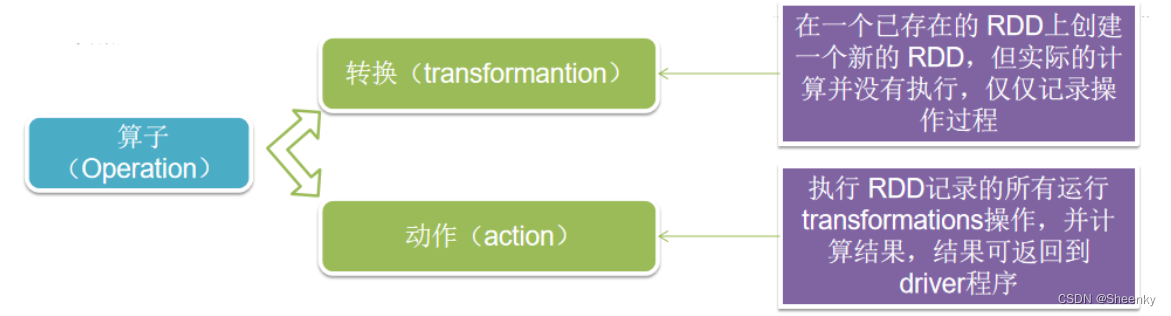
作用于RDD上的Operation分为转换(transformantion)和动作(action)。 Spark中的所有“转换”都是惰性的,当执行“转换”操作时,并不会提交Job,只有在执行“动作”操作,所有operation才会被真正的被执行。这样可以大大提升系统的性能。用一个图片展示如下:
Spark为包含键值对(key-value)类型的RDD提供了一些专有的操作,这些RDD被称PairRDD。
二、RDD的使用(基于Linux系统)
(1)RDD创建
RDD有两种创建方法,分别是:基于数据集合构建、基于外部数据源创建。
①基于数据集合创建
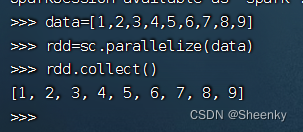
自定义数据集合进行RDD转换(parallelize()函数),通过显示命令collect()显示出rdd样式。
#自定义数据集合
data=[1,2,3,4,5,6,7,8,9]
#创建RDD
rdd=sc.parallelize(data)
#显示rdd,使用collcet()函数
rdd.collect()
②基于外部数据源创建
使用textFile()函数进行进行文件读入,函数内加入的是文件在虚拟机中的绝对路径。
rdd = sc.textFile("file:///root/data/apache.log")
rdd.collect()
(2)transformation算子——map()
map算子将原来RDD的每个数据项通过map中的用户自定义函数f映射转变为一个新的元素,从而
形成新的RDD。简单的来说就是根据map()括号中定义的函数进行映射有点儿类似于遍历的一个过程。而mapPartitions的输入函数是应用于每个分区。mapPartitionsWithIndex:对RDD中的每个分区(带有下标)进行操作,通过自己定义的一个函数来处理。
下面通过例子讲述就会很清晰的讲述出map()函数的作用过程。
#转换成RDD形式
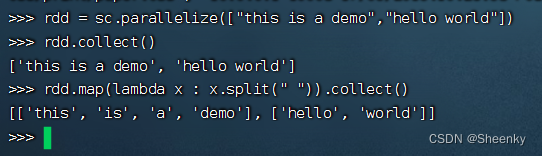
rdd = sc.parallelize(["this is a demo","hello world"])
#进行转换显示
rdd.collect()
#进行map()操作
rdd.map(lambda x : x.split(" ")).collect()结果如图,map()中添加的函数我们选用split()分割函数,不难看出,他先对集合中的两个元素进行遍历,在对没个遍历了的函数进行split()分割,所以博主觉得这个map和Python的map很像。
(3)transformation算子——flatMap()
flatMap算子首先将map函数应用于该RDD的所有元素,然后将结果平坦化,从而返回新的RDD。
简单的说就是对数据进行一次遍历后执行括号内的函数再进行一次遍历。
rdd = sc.parallelize(["this is a demo","hello world"])
rdd.flatMap(lambda x : x.split(" ")).collect()得到如下结果,因为这儿rdd的性质和pandas的性质不一样,它是不变的,前面也做过说明,因此博主直接盗用前面的rdd。结果显而易见是对map做了一个集合的遍历添加操作。

(4)transformation算子——filter()
filter算子会针对 RDD所有分区的每一个元素进行过滤,满足条件的返回,不满足条件的忽略。在Python编程中这个算子实现方法为遍历判断,添加在集合中输出。
rdd = sc.parallelize([1, 2, 3, 4, 5])
rdd.filter(lambda x: x % 2 == 0).collect()结果如图所示,过滤出符合条件的数据。

(5)transformation算子——union()
可以求两个RDD的并集,返回一个新的RDD,union函数有点雷同与SQL语句的union只是SQL语句中两表数据的连接有一定的限制,而spark中就是求一个并集。
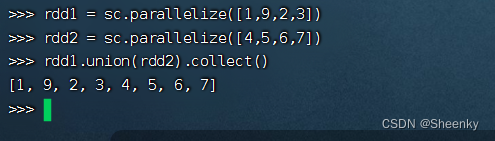
rdd1 = sc.parallelize([1,9,2,3])
rdd2 = sc.parallelize([4,5,6,7])
rdd1.union(rdd2).collect()得到如下结果:
(6)transformation算子——intersection()
算子返回这个 RDD 和另一个 RDD 的交集,输出将不包含任何重复的元素。
rdd1 = sc.parallelize([1,10,2,3,4,5])
rdd2 = sc.parallelize([1,6,2,3,7,8])
rdd1.intersection(rdd2).collect()得到如下交集结果

(7)transformation算子——distinct()
算子能够对RDD中的元素进行去重,返回包含不同元素的新RDD。
rdd = sc.parallelize([1,1,2,3])
rdd .distinct().collect()结果如图:

(8)transformation算子——sample()
对数据进行抽样,有放回抽样和不放回抽样,还有比例抽样
sample(withReplacement:Boolean,fraction:Double,seed:Long)
1、withReplacement;是否是放回式抽样,布尔类型(true,false)
2、fraction:抽样比例,分区内的所占比例
3、seed:抽样算法的初始值
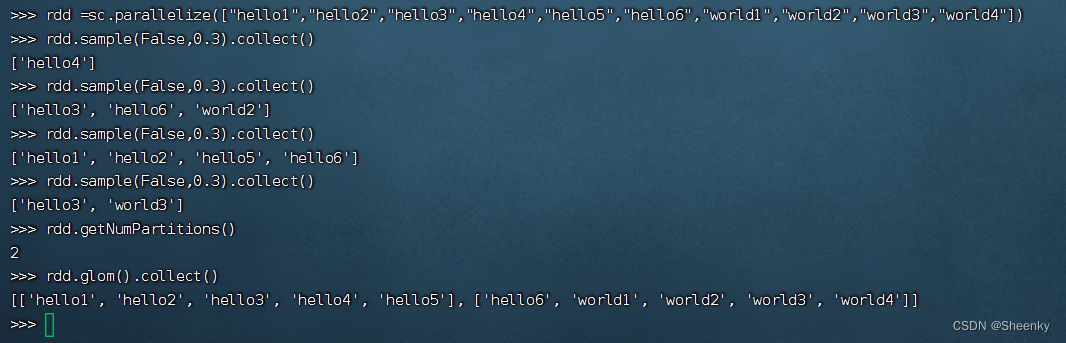
rdd=sc.parallelize(["hello1","hello2","hello3","hello4","hello5","hello6","world1","world2","world3","world4"])
rdd.sample(False,0.3).collect() # 在数据量不大时,不会太准确
rdd.getNumPartitions() # 查看分区数
rdd.glom().collect() # 查看分区的内容得到结果如下,通过getNumPartition()函数,查看分区情况,在分区内进行一个比例抽取。
(9)action算子——reduce()
reduce算子相当于 MapReduce 中的 Reduce 操作,可以通过指定的聚合方法来对 RDD 中元素进
行聚合。
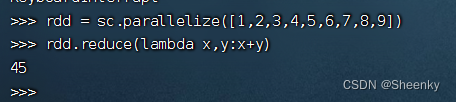
rdd = sc.parallelize([1,2,3,4,5,6,7,8,9])
rdd.reduce(lambda x,y:x+y)运行结果如下:
(10)action算子——count()
返回RDD算子中元素的个数,总元素个数之和,分区不受影响。
rdd = sc.parallelize([1,2,3,4,5,6,7,8,9],3)
rdd.count()得到如下结果,因此我们知道不管你怎么分区,他记录的都是整个RDD中每个分区的元素之和

(11)action算子——take()
算子返回前n个值的集合
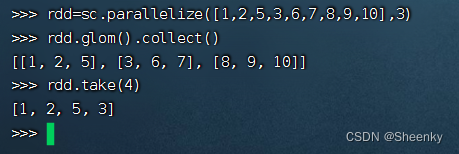
rdd=sc.parallelize([1,2,5,3,6,7,8,9,10],3)
rdd.glom().collect()
rdd.take(4)得到如下结果,发现算子与分区关
(12)action算子——first()
返回RDD第一个值,类型为元素类型
sc.parallelize([5,10, 1, 2, 9, 3, 4, 5, 6, 7]).first()
(13) action算子——top()
返回RDD中元素的前n个最大值的集合
sc.parallelize([1,2,6,7,8,3,4]).top(3)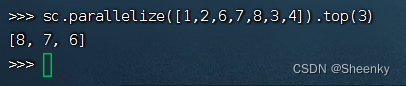
(14)action算子——collect()
collect() 算子通常用在单元测试中,可以将整个RDD的内容返回到本地
rdd = sc.parallelize([1,2,3,4,5])
rdd.collect()
(15)action算子——countByValue()
统计一个RDD中各个value的出现次数
rdd = sc.parallelize([1,1,1,2,2,3,4,5,5])
rdd.countByValue() 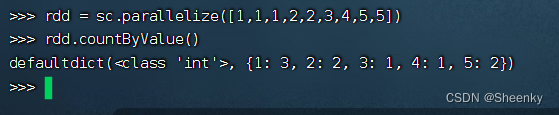
(16)action算子——foreach()
foreach遍历RDD的每个元素,并执行f函数操作,没有返回值(不需要把 RDD 发回本地),特别适合
用于将数据写入数据库,存储在文件中的操作.
rdd = sc.parallelize([1,2,3,4,5])
rdd.foreach(lambda x: print(x+1))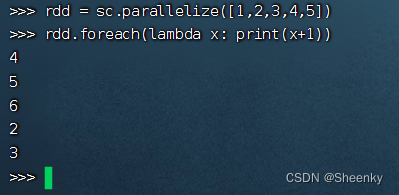
(17)action算子——takeSample()
takeSample的作用类似于sample算子,但是可以指定要获取样本的个数
def takeSample(
withReplacement: Boolean,
num: Int,
seed: Long = Utils.random.nextLong): Array[T] = withScope { ... }
)
withReplacement:是否可以多次抽样(true可以,false不可以)
num:返回样本的数量
seed:随机数生成器的种子(一般都是默认不会指定)不可以重复抽样,样本个数num大于RDD个数时,返回RDD个数
rdd = sc.parallelize([1,2,3,4,5])
rdd.takeSample(False,8)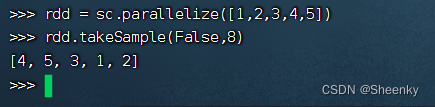
不可以重复抽样,样本个数num小于RDD个数时,返回样本个数
rdd = sc.parallelize([1,2,3,4,5])
rdd.takeSample(False,3)
可以重复抽样,样本个数num大于RDD个数时,返回样本个数
rdd = sc.parallelize([1,2,3,4,5])
rdd.takeSample(True,8)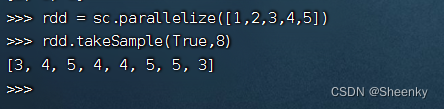
可以重复抽样,样本个数num小于RDD个数时,返回样本个数
rdd = sc.parallelize([1,2,3,4,5])
rdd.takeSample(True,3)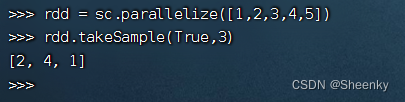
(18)action算子——aggregate()
aggregate(zeroValue, seqOp, combOp)
zeroValue:U
这个值代表的是我们需要设置的初始值,该初始值可以是不与原RDD的元素类型相同,可以是
Int,String,元组等等任何我们所需要的类型,根据自己的需求来。
seqOp: (U, T) => U
这里需要定义一个函数,注意,是函数,U的类型与我们在第一步中定义的初始值得类型相同。这
里的T代表即为RDD中每个元素的值。该函数的功能是,在每个分区内遍历每个元素,将每个元素与U进行聚合,具体的聚合方式,我们可以自定义。
combOp: (U, U) => U
这里同样需要定义一个函数,这里的U即为每个分区内聚合之后的结果。该函数的主要作用就是对
每个分区聚合之后的结果进行再次合并,即分区之间的合并。
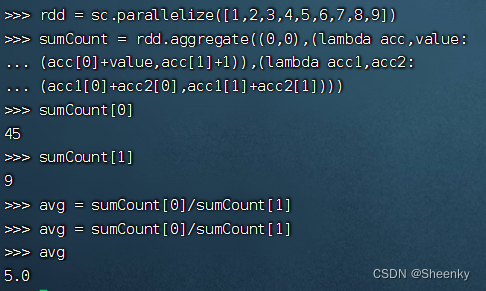
rdd = sc.parallelize([1,2,3,4,5,6,7,8,9]) #求列表的平均值
sumCount = rdd.aggregate((0,0),(lambda acc,value:
(acc[0]+value,acc[1]+1)),(lambda acc1,acc2:
(acc1[0]+acc2[0],acc1[1]+acc2[1])))
avg = sumCount[0]/sumCount[1]结果如图,第一个值为设定初始值,第二个函数对初始值分别进行处理,初始值是一个元组,函数二就是进行对组数进行赋值(即类似的结构([1,2,3,4,5,6,7,8,9],[1,1,1,1,1,1,1,1,1])),函数三是对数组进行聚合求和操作(即(45,9))
(19)PariRDD算子(transformation算子)——mapValues和flatMapValues()
对键值对每个value都应用一个函数,但是,key不会发生变化
x = sc.parallelize([("a", ["apple", "banana", "lemon"]), ("b", ["grapes"])])
x.mapValues(lambda item:len(item)).collect()
x.mapValues(lambda item:item).collect()
x.flatMapValues(lambda item:item).collect()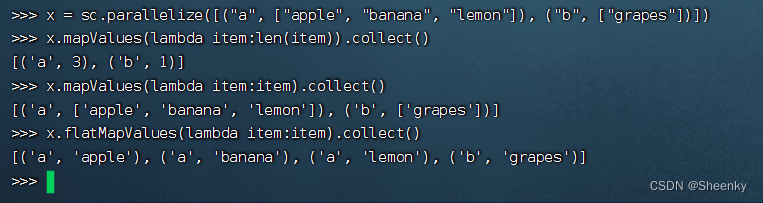
(20)PariRDD算子(transformation算子)——reduceByKey()
reduceByKey算子合并key对应的所有值,不改变RDD类型
rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 2)])
rdd.reduceByKey(lambda x,y:x+y).collect()
(21)PariRDD算子(transformation算子)——groupByKey()
groupByKey算子根据key值进行分组
rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 2)])
rdd.groupByKey().mapValues(len).collect()
rdd.groupByKey().mapValues(list).collect()
(22)PariRDD算子(transformation算子)——sortByKey()
sortByKey算子根据key值进行排序,默认升序
第一个参数:True升序,False降序
第二个参数:分区数
tmp = [('a', 1), ('b', 2), ('1', 3), ('d', 4), ('2', 5)]
sc.parallelize(tmp).sortByKey().first()
sc.parallelize(tmp).sortByKey(False, 1).collect()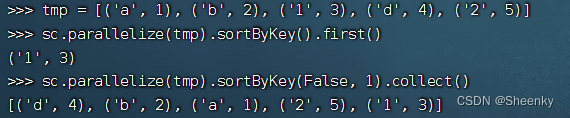
(23)PariRDD算子(action算子)——collectAsMap()
collectAsMap算子将结果以字典的形式返回,便于查询
m = sc.parallelize([(1, 2), (3, 4)])
m.collectAsMap()

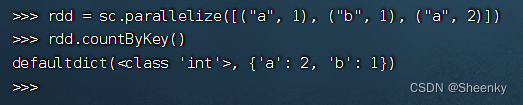
(24)PariRDD算子(action算子)——countByKey()
countByKey算子统计每个Key键的元素数
rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 2)])
rdd.countByKey()