爬取网页:https://movie.douban.com/top250
爬取目标:获取电影片名、评分、最短影评、评论人数,并将爬取的数据解析到txt文档中。
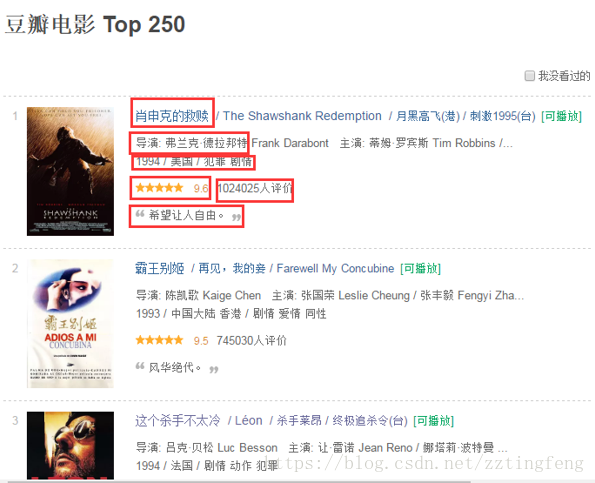
通过F12检查网页对应的HTML代码

网页的尾部信息:

电影列表在页面上的位置为一个class属性为grid_view的ol标签中。
a、每页有25条电影,共有10页。
每个电影的电影名称在:第一个 class属性值为hd 的div标签 下的 第一个 class属性值为title 的span标签里;
b、评分
每个电影的评分在对应li标签里的(唯一)一个 class属性值为rating_num 的span标签里;
c、评论人数
每个电影的评价人数在 对应li标签 里的一个 class属性值为star 的div标签中 的最后一个数字;
d、短评:
每个电影的短评在 对应li标签 里的一个 class属性值为inq 的span标签里。
获取数据:
分析:
问题:如果有403
• 为需要登录的网站没有登录
• 服务器拒绝访问(爬虫被识别)
解决:请求头处理
• UserAgent标识浏览器的类型
• 伪装成浏览器
import requests
import codecs
from bs4 import BeautifulSoup
URL = 'http://movie.douban.com/top250'
def download_page(url):
header = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, \
like Gecko) Chrome/53.0.2785.89 Safari/537.36'
}
data = requests.get(url,headers=header).content
return data
def main():
print(download_page(URL))
if __name__ == '__main__':
main()使用BeautifulSoup解析网页
def getData(html):
soup = BeautifulSoup(html, "html.parser")
movieList=soup.find('ol',attrs={'class':'grid_view'})#找到第一个class属性值为grid_view的ol标签
moveInfo=[]
for movieLi in movieList.find_all('li'):#找到所有li标签
data = []
#得到电影名字
movieHd=movieLi.find('div',attrs={'class':'hd'})#找到第一个class属性值为hd的div标签
movieName=movieHd.find('span',attrs={'class':'title'}).getText()#找到第一个class属性值为title的span标签
#也可使用.string方法
data.append(movieName)
#得到电影的评分
movieScore=movieLi.find('span',attrs={'class':'rating_num'}).getText()
data.append(movieScore)
#得到电影的评价人数
movieEval=movieLi.find('div',attrs={'class':'star'})
movieEvalNum=re.findall(r'\d+',str(movieEval))[-1]
data.append(movieEvalNum)
# 得到电影的短评
movieQuote = movieLi.find('span', attrs={'class': 'inq'})
if(movieQuote):
data.append(movieQuote.getText())
else:
data.append("无")
print(outputMode.format(data[0], data[1], data[2],data[3],chr(12288)))分页: