Triplet Loss and Online Triplet Mining in TensorFlow(TensorFlow中的三元组损失与在线三元组挖掘)
前言
Triplet loss is known to be difficult to implement, especially if you add the constraints of building a computational graph in TensorFlow.
(众所周知,三元组损失很难实现,特别是在tensorflow中添加构建计算图的约束时。)
In this post, I will define the triplet loss and the different strategies to sample triplets. I will then explain how to correctly implement triplet loss with online triplet mining in TensorFlow.
(在这篇文章中,我将会定义三元组损失和三元组采样的不同策略。然后我会解释如何在Tensor flow中使用在线三元组挖掘正确实现三元组损失。)
Triplet loss and triplet mining(三元组损失和三元组挖掘)
Why not just use softmax?(为什么不仅仅使用softmax)
Usually in supervised learning we have a fixed number of classes and train the network using the softmax cross entropy loss. However in some cases we need to be able to have a variable number of classes. In face recognition for instance, we need to be able to compare two unknown faces and say whether they are from the same person or not.(通常在监督学习中,我们有固定数量的类,并且使用交叉熵损失来训练网络。然而,在某些情况下,我们需要有可变数量的类。例如在人脸识别中,我们需要能够比较两张陌生的面孔,并判断他们是否来自于同一个人。)
Triplet loss in this case is a way to learn good embeddings for each face. In the embedding space, faces from the same person should be close together and form well separated clusters.(在这种情况下,三元组损失是一中种为每一张脸学习良好嵌入的方法。在嵌入空间中,来自同一个人的脸应该靠的很近,形成分离良好的簇。)
Definition of the loss

Triplet loss on two positive faces (Obama) and one negative face (Macron)
The goal of the triplet loss is to make sure that:
(三元组损失的目标是确保:)
- Two examples with the same label have their embeddings close together in the embedding space
(具有相同标签的两个示例在嵌入空间中的嵌入非常紧密) - Two examples with different labels have their embeddings far away.(具有不同标签的两个示例的嵌入距离很远。)
However, we don’t want to push the train embeddings of each label to collapse into very small clusters. The only requirement is that given two positive examples of the same class and one negative example, the negative should be farther away than the positive by some margin. This is very similar to the margin used in SVMs, and here we want the clusters of each class to be separated by the margin.(但是,我们不希望将每个标签的序列嵌入分解为非常小的集群。唯一的要求是,给定同一类的两个正例和一个负例,负例应该比正例远一些。这与SVM中使用的边距非常相似,在这里,我们希望每个类的集群都用边距隔开。)
To formalise this requirement, the loss will be defined over triplets of embeddings:(为了形式化这一要求,损失将在嵌入的三元组上定义:)
- an anchor
- a positive of the same class as the anchor
- a negative of a different class
For some distance on the embedding space d, the loss of a triplet is (a, p, n): (对于嵌入空间上的某一距离d,一个三元组(a, p, n)为:)
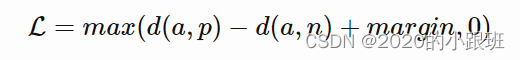
We minimize this loss, which pushes d(a,p) to 0 and
d(a,n) to be greater than d(a,p)+margin. As soon as
n becomes an “easy negative”, the loss becomes zero.(我们将损失最小化,使d(a,p)趋于0,d(a,n)大于d(a,p)+margin.一旦n变成了一个简单的复数,损失变为零)
三元组挖掘
Based on the definition of the loss, there are three categories of triplets:(根据三元组的损失,三元组分为三类:)
- easy triplets: triplets which have a loss of 0, because d(a,p)+margin<d(a,n)
- hard triplets: triplets where the negative is closer to the anchor than the positive, i.e. d(a,n)<d(a,p)
- semi-hard triplets: triplets where the negative is not closer to the anchor than the positive, but which still have positive loss:d(a,p)<d(a,n)<d(a,p)+margin
Each of these definitions depend on where the negative is, relatively to the anchor and positive. We can therefore extend these three categories to the negatives: hard negatives, semi-hard negatives or easy negatives.
The figure below shows the three corresponding regions of the embedding space for the negative.
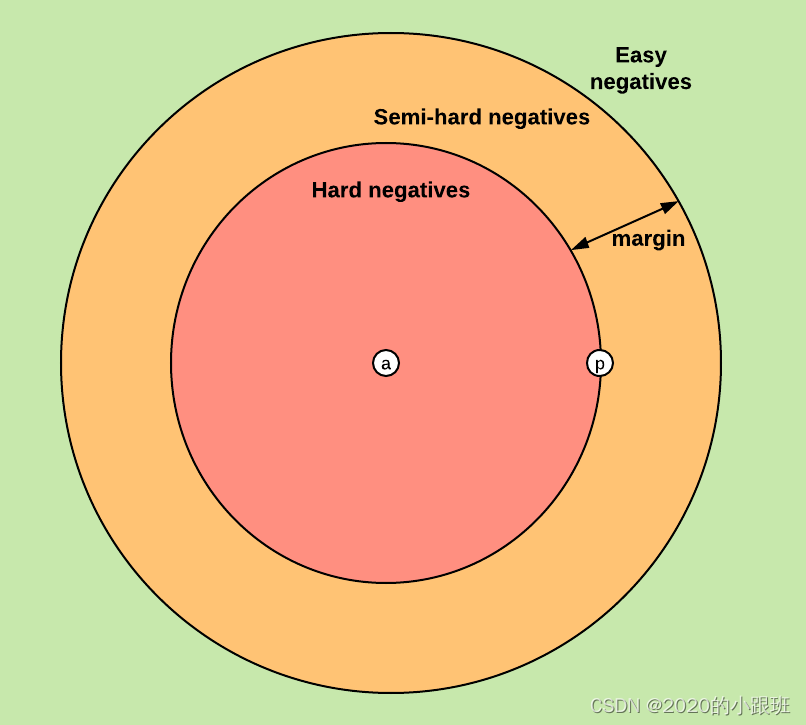
Choosing what kind of triplets we want to train on will greatly impact our metrics. In the original Facenet paper, they pick a random semi-hard negative for every pair of anchor and positive, and train on these triplets.(选择我们想要训练的三元组损失函数将极大地影响我们的参数。对于最初的Facenet论文中,他们为每一对标点和正点选择一个随机的半困难否定,并且在这些三元组上进行训练。)
Offline and online triplet mining(离线和在线三元组挖掘)
We have defined a loss on triplets of embeddings, and have seen that some triplets are more useful than others. The question now is how to sample, or “mine” these triplets.(我们在三元组嵌入上定义了一个损失,并且发现有些三元组比其他的更有效。现在的问题是如何采样,或者说“挖掘”这些三元组。)
Offline triplet mining(离线三元组挖掘)
The first way to produce triplets is to find them offline, at the beginning of each epoch for instance. We compute all the embeddings on the training set, and then only select hard or semi-hard triplets. We can then train one epoch on these triplets.(生成三元组的第一个方法是离线查找他们,比如在每一个epoch的开始。我们在训练集上计算所有的嵌入,然后只选择困难或者半困难的三元组。我们可以在这些三元组上训练一个epoch.)
Concretely, we would produce a list of triplets (i,j,k). We would then create batches of these triplets of size B, which means we will have to compute 3B embeddings to get the B triplets, compute the loss of these B triplets and then backpropagate into the network.(具体地说,我们将生成一个三元组列表(i,j,k).我们将会创建大小为B的这些三元组的批次,这意味着我们必须计算3B嵌入来获得B个三元组的损失,然后反向传播到网络中。)
Overall this technique is not very efficient since we need to do a full pass on the training set to generate triplets. It also requires to update the offline mined triplets regularly. (总的来说,这种技术不是非常有效,因为我们需要对训练集进行完整的传递来生成三元组。它还需要定期更新离散挖掘的三元组。)
Oneline triplet mining(在线三元组挖掘)
The idea here is to compute useful triplets on the fly, for each batch of inputs. Given a batch of B examples (for instance B images of faces), we compute the B embeddings and we then can find a maximum of B3 triplets. Of course, most of these triplets are not valid (i.e. they don’t have 2 positives and 1 negative)(这里的思想是为每一批次的输入动态计算有用的三元组。给定一批B个例子(例如B张人脸图像),我们计算B个嵌入,然后我们可以找到B3个三元组的最大值。当然,这些三元组大部分是无效的(即,他们没有两个正点和一个负点))
This technique gives you more triplets for a single batch of inputs, and doesn’t require any offline mining. It is therefore much more efficient. We will see an implementation of this in the last part.(这种技术为单个批次的输入提供了更多三元组,并且不需要任何离线挖掘。因此效率要高得多。我们将会在最后一部分看到他的实现)
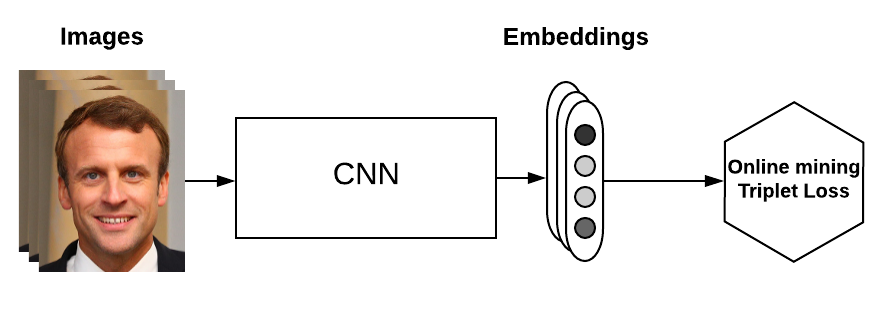
Strategies in online mining
In online mining, we have computed a batch of B embeddings from a batch of B inputs. Now we want to generate triplets from these B embeddings.(在在线挖掘中,我们从一批B个输入计算出一批B个嵌入。现在我们想要从这B个嵌入里面生成三元组。)
Whenever we have three indices i,j,k∈[1,B], if examples i and j have the same label but are distinct, and example k has a different label, we say that (i,j,k) is a valid triplet. What remains here is to have a good strategy to pick triplets among the valid ones on which to compute the loss.(每当我们有三个指标i,j,k∈[1,B],如果例子i和j有相同的标签但不同,而例子k有不同的标签,我们说(i,j,k)是一个有效的三元组。剩下的就是要有一个好的策略,从有效的三元组中挑选三元组来计算损失)
A detailed explanation of two of these strategies can be found in section 2 of the paper In Defense of the Triplet Loss for Person Re-Identification.
They suppose that you have a batch of faces as input of size B=PK, composed of P different persons with K images each. A typical value is K=4. The two strategies are:(他们假设有一批人脸作为大小为B=PK的输入,由P个不同的人组成,每个人有K张图象。典型的值是K=4,两种策略是:)
- batch all: select all the valid triplets, and average the loss on the hard and semi-hard triplets.
(选择所有有效的三元组并平均困难和版困难的三元组的损失)- a crucial point here is to not take into account the easy triplets (those with loss 0), as averaging on them would make the overall loss very small(这里的关键的一点是不要考虑简单三元组(损失为0的三元组),因为对它们进行平均会使总体损失非常小)
- this produces a total of PK(K−1)(PK−K) triplets (PK anchors, K−1 possible positives per anchor, PK-K possible negatives)
- batch hard: for each anchor, select the hardest positive (biggest distance d(a,p)) and the hardest negative among the batch (对每一个标点,选取最难的正点(最大距离d(a,p)))和最难的负点
- this produces PK triplets这将产生PK个三元组
- the selected triplets are the hardest among the batch选中的三元组是批次中最难的三元组
批困难策略产生最好的表现
Additionally, the selected triplets can be considered moderate triplets, since they are the hardest within a small subset of the data, which is exactly what is best for learning with the triplet loss.(另外,选取的三元组可以被认为是中等的三元组,因为他们是一个小数据集中最困难的样本,最有利于学习三元组损失)
However it really depends on your dataset and should be decided by comparing performance on the dev set.(然而,这实际上取决于您的数据集,应该通过比较开发集上的性能来决定)
A naive implementation of triplet loss(三元组损失的简单实现)
离散三元组的简单实现:
anchor_output = ... # shape [None, 128]
positive_output = ... # shape [None, 128]
negative_output = ... # shape [None, 128]
d_pos = tf.reduce_sum(tf.square(anchor_output - positive_output), 1) # 按一定方式计算张量中元素之和
d_neg = tf.reduce_sum(tf.square(anchor_output - negative_output), 1) # 沿着指定的数轴上的平均值,用作降维或者计算tensor的平均值
loss = tf.maximum(0.0, margin + d_pos - d_neg)
loss = tf.reduce_mean(loss)
The network is replicated three times (with shared weights) to produce the embeddings of B anchors,B positives and B negatives. We then simply compute the triplet loss on these embeddings.(该网络被复制三次(使用共享权值),以生成B个标点,B个正点和B个负点。然年简单计算这些嵌入上的三元组损失)
A better implementation with online triplet mining(在线三元组挖掘的更好应用)
计算距离矩阵
As the final triplet loss depends on the distances
d(a,p) and d(a,n), we first need to efficiently compute the pairwise distance matrix. We implement this for the euclidean norm and the squared euclidean norm, in the _pairwise_distances function:(因为最后的三元组损失取决于距离d(a,p)和d(a,n),我们首先需要高效的计算成对距离矩阵。在 _pairwise_distances 函数中,我们使用欧氏范数和平方欧氏范数实现了这个。
"""Define functions to create the triplet loss with online triplet mining."""
import tensorflow as tf
def _pairwise_distances(embeddings, squared=False):
"""Compute the 2D matrix of distances between all the embeddings.
Args:
embeddings: tensor of shape (batch_size, embed_dim)
squared: Boolean. If true, output is the pairwise squared euclidean distance matrix.
If false, output is the pairwise euclidean distance matrix.
Returns:
pairwise_distances: tensor of shape (batch_size, batch_size)
"""
# Get the dot product between all embeddings
# shape (batch_size, batch_size)
dot_product = tf.matmul(embeddings, tf.transpose(embeddings))
# Get squared L2 norm for each embedding. We can just take the diagonal of `dot_product`.
# This also provides more numerical stability (the diagonal of the result will be exactly 0).
# shape (batch_size,)
square_norm = tf.diag_part(dot_product) # 返回张量的对角线部分
# Compute the pairwise distance matrix as we have:
# ||a - b||^2 = ||a||^2 - 2 <a, b> + ||b||^2
# shape (batch_size, batch_size)
distances = tf.expand_dims(square_norm, 1) - 2.0 * dot_product + tf.expand_dims(square_norm, 0) # 在给定一个input时,在axis轴处给input增加一个维度
# Because of computation errors, some distances might be negative so we put everything >= 0.0
distances = tf.maximum(distances, 0.0)
if not squared:
# Because the gradient of sqrt is infinite when distances == 0.0 (ex: on the diagonal)
# we need to add a small epsilon where distances == 0.0
mask = tf.to_float(tf.equal(distances, 0.0))
distances = distances + mask * 1e-16
distances = tf.sqrt(distances)
# Correct the epsilon added: set the distances on the mask to be exactly 0.0
distances = distances * (1.0 - mask)
return distances
def _get_anchor_positive_triplet_mask(labels):
"""Return a 2D mask where mask[a, p] is True iff a and p are distinct and have same label.
Args:
labels: tf.int32 `Tensor` with shape [batch_size]
Returns:
mask: tf.bool `Tensor` with shape [batch_size, batch_size]
"""
# Check that i and j are distinct
indices_equal = tf.cast(tf.eye(tf.shape(labels)[0]), tf.bool)
indices_not_equal = tf.logical_not(indices_equal)
# Check if labels[i] == labels[j]
# Uses broadcasting where the 1st argument has shape (1, batch_size) and the 2nd (batch_size, 1)
labels_equal = tf.equal(tf.expand_dims(labels, 0), tf.expand_dims(labels, 1))
# Combine the two masks
mask = tf.logical_and(indices_not_equal, labels_equal)
return mask
def _get_anchor_negative_triplet_mask(labels):
"""Return a 2D mask where mask[a, n] is True iff a and n have distinct labels.
Args:
labels: tf.int32 `Tensor` with shape [batch_size]
Returns:
mask: tf.bool `Tensor` with shape [batch_size, batch_size]
"""
# Check if labels[i] != labels[k]
# Uses broadcasting where the 1st argument has shape (1, batch_size) and the 2nd (batch_size, 1)
labels_equal = tf.equal(tf.expand_dims(labels, 0), tf.expand_dims(labels, 1))
mask = tf.logical_not(labels_equal)
return mask
def _get_triplet_mask(labels):
"""Return a 3D mask where mask[a, p, n] is True iff the triplet (a, p, n) is valid.
A triplet (i, j, k) is valid if:
- i, j, k are distinct
- labels[i] == labels[j] and labels[i] != labels[k]
Args:
labels: tf.int32 `Tensor` with shape [batch_size]
"""
# Check that i, j and k are distinct
indices_equal = tf.cast(tf.eye(tf.shape(labels)[0]), tf.bool)
indices_not_equal = tf.logical_not(indices_equal)
i_not_equal_j = tf.expand_dims(indices_not_equal, 2)
i_not_equal_k = tf.expand_dims(indices_not_equal, 1)
j_not_equal_k = tf.expand_dims(indices_not_equal, 0)
distinct_indices = tf.logical_and(tf.logical_and(i_not_equal_j, i_not_equal_k), j_not_equal_k)
# Check if labels[i] == labels[j] and labels[i] != labels[k]
label_equal = tf.equal(tf.expand_dims(labels, 0), tf.expand_dims(labels, 1))
i_equal_j = tf.expand_dims(label_equal, 2)
i_equal_k = tf.expand_dims(label_equal, 1)
valid_labels = tf.logical_and(i_equal_j, tf.logical_not(i_equal_k))
# Combine the two masks
mask = tf.logical_and(distinct_indices, valid_labels)
return mask
def batch_all_triplet_loss(labels, embeddings, margin, squared=False):
"""Build the triplet loss over a batch of embeddings.
We generate all the valid triplets and average the loss over the positive ones.
Args:
labels: labels of the batch, of size (batch_size,)
embeddings: tensor of shape (batch_size, embed_dim)
margin: margin for triplet loss
squared: Boolean. If true, output is the pairwise squared euclidean distance matrix.
If false, output is the pairwise euclidean distance matrix.
Returns:
triplet_loss: scalar tensor containing the triplet loss
"""
# Get the pairwise distance matrix
pairwise_dist = _pairwise_distances(embeddings, squared=squared)
# shape (batch_size, batch_size, 1)
anchor_positive_dist = tf.expand_dims(pairwise_dist, 2)
assert anchor_positive_dist.shape[2] == 1, "{}".format(anchor_positive_dist.shape)
# shape (batch_size, 1, batch_size)
anchor_negative_dist = tf.expand_dims(pairwise_dist, 1)
assert anchor_negative_dist.shape[1] == 1, "{}".format(anchor_negative_dist.shape)
# Compute a 3D tensor of size (batch_size, batch_size, batch_size)
# triplet_loss[i, j, k] will contain the triplet loss of anchor=i, positive=j, negative=k
# Uses broadcasting where the 1st argument has shape (batch_size, batch_size, 1)
# and the 2nd (batch_size, 1, batch_size)
triplet_loss = anchor_positive_dist - anchor_negative_dist + margin
# Put to zero the invalid triplets
# (where label(a) != label(p) or label(n) == label(a) or a == p)
mask = _get_triplet_mask(labels)
mask = tf.to_float(mask)
triplet_loss = tf.multiply(mask, triplet_loss)
# Remove negative losses (i.e. the easy triplets)
triplet_loss = tf.maximum(triplet_loss, 0.0)
# Count number of positive triplets (where triplet_loss > 0)
valid_triplets = tf.to_float(tf.greater(triplet_loss, 1e-16))
num_positive_triplets = tf.reduce_sum(valid_triplets)
num_valid_triplets = tf.reduce_sum(mask)
fraction_positive_triplets = num_positive_triplets / (num_valid_triplets + 1e-16)
# Get final mean triplet loss over the positive valid triplets
triplet_loss = tf.reduce_sum(triplet_loss) / (num_positive_triplets + 1e-16)
return triplet_loss, fraction_positive_triplets
def batch_hard_triplet_loss(labels, embeddings, margin, squared=False):
"""Build the triplet loss over a batch of embeddings.
For each anchor, we get the hardest positive and hardest negative to form a triplet.
Args:
labels: labels of the batch, of size (batch_size,)
embeddings: tensor of shape (batch_size, embed_dim)
margin: margin for triplet loss
squared: Boolean. If true, output is the pairwise squared euclidean distance matrix.
If false, output is the pairwise euclidean distance matrix.
Returns:
triplet_loss: scalar tensor containing the triplet loss
"""
# Get the pairwise distance matrix
pairwise_dist = _pairwise_distances(embeddings, squared=squared)
# For each anchor, get the hardest positive
# First, we need to get a mask for every valid positive (they should have same label)
mask_anchor_positive = _get_anchor_positive_triplet_mask(labels)
mask_anchor_positive = tf.to_float(mask_anchor_positive)
# We put to 0 any element where (a, p) is not valid (valid if a != p and label(a) == label(p))
anchor_positive_dist = tf.multiply(mask_anchor_positive, pairwise_dist)
# shape (batch_size, 1)
hardest_positive_dist = tf.reduce_max(anchor_positive_dist, axis=1, keepdims=True)
tf.summary.scalar("hardest_positive_dist", tf.reduce_mean(hardest_positive_dist))
# For each anchor, get the hardest negative
# First, we need to get a mask for every valid negative (they should have different labels)
mask_anchor_negative = _get_anchor_negative_triplet_mask(labels)
mask_anchor_negative = tf.to_float(mask_anchor_negative)
# We add the maximum value in each row to the invalid negatives (label(a) == label(n))
max_anchor_negative_dist = tf.reduce_max(pairwise_dist, axis=1, keepdims=True)
anchor_negative_dist = pairwise_dist + max_anchor_negative_dist * (1.0 - mask_anchor_negative)
# shape (batch_size,)
hardest_negative_dist = tf.reduce_min(anchor_negative_dist, axis=1, keepdims=True)
tf.summary.scalar("hardest_negative_dist", tf.reduce_mean(hardest_negative_dist))
# Combine biggest d(a, p) and smallest d(a, n) into final triplet loss
triplet_loss = tf.maximum(hardest_positive_dist - hardest_negative_dist + margin, 0.0)
# Get final mean triplet loss
triplet_loss = tf.reduce_mean(triplet_loss)
return triplet_loss
To explain the code in more details, we compute the dot product between embeddings which will have shape (B,B). The squared euclidean norm of each embedding is actually contained in the diagonal of this dot product so we extract it with tf.diag_part. Finally we compute the distance using the formula:
(为更详细的解释代码,我们计算形状为(B,B)的嵌入空间的点积。每个嵌入的欧式范数的平方实际上包含在这个点积的对角线中,因此我们用tf.diag_part提取它。最后我们用公式计算距离:)
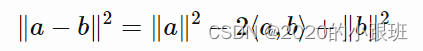
One tricky thing is that if squared=False, we take the square root of the distance matrix. First we have to ensure that the distance matrix is always positive. Some values could be negative because of small inaccuracies in computation. We just make sure that every negative value gets set to 0.0.(一个棘手的
事情是如果平方等于False,我们取距离矩阵的平方根。首先我们要确保距离矩阵总是正的。由于计算中的小误差,有些值可能是复数。我们只是确保每个负值都被设置为0.0)
The second thing to take care of is that if any element is exactly 0.0 (the diagonal should always be 0.0 for instance), as the derivative of the square root is infinite in 0, we will have a nan gradient. To handle this case, we replace values equal to 0.0 with a small epsilon = 1e-16. We then take the square root, and replace the values √ϵ with 0.0.(第二件要注意的事情是,如果任何元素恰好是0.0(例如对角线应该总是0.0),因为根号的导数在0上是无穷大的,我们将有一个nan梯度。为了处理这种情况,我们将等于0.0的值替换为一个小的=1e-16.然后取平方根,将√ϵ的值替换为0.0)
Batch all Strategy
In this strategy, we want to compute the triplet loss on almost all triplets. In the TensorFlow graph, we want to create a 3D tensor of shape (B,B,B) where the element at index (i,j,k) contains the loss for triple (i,j,k).(在这个策略中,我们要计算几乎所有三元组的三元组损失,在Tensorflow图中,我们想要创建一个形状为(B,B,B)的3D张量,其中索引(i,j,k)的元素包含三元(i,j,k)的损失)
We then get a 3D mask of the valid triplets with function _get_triplet_mask. Here, mask[i, j, k] is true iff (i,j,k) is a valid triplet.(然后,我们通过函数_get_triple_mask获得有效三元组的3D掩码。这里掩码[i,j,k]为真,iff(i,j,k)为有效三元组。)
Finally, we set to 0 the loss of the invalid triplets and take the average over the positive triplets.(最后,我们将无效三元组的损失设为0,并对正三元组取平均值。)
Everything is implemented in function batch_all_triplet_loss
def batch_all_triplet_loss(labels, embeddings, margin, squared=False):
"""Build the triplet loss over a batch of embeddings.
We generate all the valid triplets and average the loss over the positive ones.
Args:
labels: labels of the batch, of size (batch_size,)
embeddings: tensor of shape (batch_size, embed_dim)
margin: margin for triplet loss
squared: Boolean. If true, output is the pairwise squared euclidean distance matrix.
If false, output is the pairwise euclidean distance matrix.
Returns:
triplet_loss: scalar tensor containing the triplet loss
"""
# Get the pairwise distance matrix
pairwise_dist = _pairwise_distances(embeddings, squared=squared)
# shape (batch_size, batch_size, 1)
anchor_positive_dist = tf.expand_dims(pairwise_dist, 2)
assert anchor_positive_dist.shape[2] == 1, "{}".format(anchor_positive_dist.shape)
# shape (batch_size, 1, batch_size)
anchor_negative_dist = tf.expand_dims(pairwise_dist, 1)
assert anchor_negative_dist.shape[1] == 1, "{}".format(anchor_negative_dist.shape)
# Compute a 3D tensor of size (batch_size, batch_size, batch_size)
# triplet_loss[i, j, k] will contain the triplet loss of anchor=i, positive=j, negative=k
# Uses broadcasting where the 1st argument has shape (batch_size, batch_size, 1)
# and the 2nd (batch_size, 1, batch_size)
triplet_loss = anchor_positive_dist - anchor_negative_dist + margin
# Put to zero the invalid triplets
# (where label(a) != label(p) or label(n) == label(a) or a == p)
mask = _get_triplet_mask(labels)
mask = tf.to_float(mask)
triplet_loss = tf.multiply(mask, triplet_loss)
# Remove negative losses (i.e. the easy triplets)
triplet_loss = tf.maximum(triplet_loss, 0.0)
# Count number of positive triplets (where triplet_loss > 0)
valid_triplets = tf.to_float(tf.greater(triplet_loss, 1e-16))
num_positive_triplets = tf.reduce_sum(valid_triplets)
num_valid_triplets = tf.reduce_sum(mask)
fraction_positive_triplets = num_positive_triplets / (num_valid_triplets + 1e-16)
# Get final mean triplet loss over the positive valid triplets
triplet_loss = tf.reduce_sum(triplet_loss) / (num_positive_triplets + 1e-16)
return triplet_loss, fraction_positive_triplets
Batch hard strategy
In this strategy, we want to find the hardest positive and negative for each anchor.(在这种策略中,我们想为每一个标点找到最难的正负值。)
Hardest positive(最困难正值)
To compute the hardest positive, we begin with the pairwise distance matrix. We then get a 2D mask of the valid pairs (a,p)(i.e. a≠p and a and p have same labels) and put to 0 any element outside of the mask.(为了计算最困难的正值,我们从成对距离矩阵开始,然后得到有效对(a,p)的2Dmask(即 a≠p并且a和p有相同的标签),并将mask外的任何元素置为0.
The last step is just to take the maximum distance over each row of this modified distance matrix. The result should be a valid pair (a,p) since invalid elements are set to 0.(最后一步实在修改后的距离矩阵中取每一行的最大距离。结果应该是一个有效对(a,p),因为无效元素被设置为0)
Hardest negative
The hardest negative is similar but a bit trickier to compute. Here we need to get the minimum distance for each row, so we cannot set to 0 the invalid pairs (a,n)(invalid if a and n have the same label)(最困难的负值时类似的,但计算起来有点棘手。这里我们需要得到每一行的最小距离,因此我们不能将无效对(a,n)设置为0(如果a和n具有相同的标签则无效))
Our trick here is for each row to add the maximum value to the invalid pairs (a,n). We then take the minimum over each row. The result should be a valid pair (a,n) since invalid elements are set to the maximum value.(这里的技巧是让每一行向无效对(a,n)添加最大值。然后对每一行取最小值。结果应该是一个有效的对(a,n),因为无效元素被设置为最大值。)
The final step is to combine these into the triplet loss:(最后一步是将这些三元组损失联合起来:)
triplet_loss = tf.maximum(hardest_positive_dist - hardest_negative_dist + margin, 0.0)
def batch_hard_triplet_loss(labels, embeddings, margin, squared=False):
"""Build the triplet loss over a batch of embeddings.
For each anchor, we get the hardest positive and hardest negative to form a triplet.
Args:
labels: labels of the batch, of size (batch_size,)
embeddings: tensor of shape (batch_size, embed_dim)
margin: margin for triplet loss
squared: Boolean. If true, output is the pairwise squared euclidean distance matrix.
If false, output is the pairwise euclidean distance matrix.
Returns:
triplet_loss: scalar tensor containing the triplet loss
"""
# Get the pairwise distance matrix
pairwise_dist = _pairwise_distances(embeddings, squared=squared)
# For each anchor, get the hardest positive
# First, we need to get a mask for every valid positive (they should have same label)
mask_anchor_positive = _get_anchor_positive_triplet_mask(labels)
mask_anchor_positive = tf.to_float(mask_anchor_positive)
# We put to 0 any element where (a, p) is not valid (valid if a != p and label(a) == label(p))
anchor_positive_dist = tf.multiply(mask_anchor_positive, pairwise_dist)
# shape (batch_size, 1)
hardest_positive_dist = tf.reduce_max(anchor_positive_dist, axis=1, keepdims=True)
tf.summary.scalar("hardest_positive_dist", tf.reduce_mean(hardest_positive_dist))
# For each anchor, get the hardest negative
# First, we need to get a mask for every valid negative (they should have different labels)
mask_anchor_negative = _get_anchor_negative_triplet_mask(labels)
mask_anchor_negative = tf.to_float(mask_anchor_negative)
# We add the maximum value in each row to the invalid negatives (label(a) == label(n))
max_anchor_negative_dist = tf.reduce_max(pairwise_dist, axis=1, keepdims=True)
anchor_negative_dist = pairwise_dist + max_anchor_negative_dist * (1.0 - mask_anchor_negative)
# shape (batch_size,)
hardest_negative_dist = tf.reduce_min(anchor_negative_dist, axis=1, keepdims=True)
tf.summary.scalar("hardest_negative_dist", tf.reduce_mean(hardest_negative_dist))
# Combine biggest d(a, p) and smallest d(a, n) into final triplet loss
triplet_loss = tf.maximum(hardest_positive_dist - hardest_negative_dist + margin, 0.0)
# Get final mean triplet loss
triplet_loss = tf.reduce_mean(triplet_loss)
return triplet_loss
Testing our implementation
If you don’t trust that the implementation above works as expected, then you’re right! The only way to make sure that there is no bug in the implementation is to write tests for every function in *model/triplet_loss.py *
This is especially important for tricky functions like this that are difficult to implement in TensorFlow but much easier to write using three nested for loops in python for instance. The tests are written in model/tests/test_triplet_loss.py, and compare the result of our TensorFlow implementation with the results of a simple numpy implementation.
To check yourself that the tests pass, run:
pytest model/tests/test_triplet_loss.py
Here is a list of the tests performed:
test_pairwise_distances(): compare results of numpy of tensorflow for pairwise distance
test_pairwise_distances_are_positive(): make sure that the resulting distance is positive
test_gradients_pairwise_distances(): make sure that the gradients are not nan
test_triplet_mask(): compare numpy and tensorflow implementations
test_anchor_positive_triplet_mask(): compare numpy and tensorflow implementations
test_anchor_negative_triplet_mask(): compare numpy and tensorflow implementations
test_simple_batch_all_triplet_loss(): simple test where there is just one type of label
test_batch_all_triplet_loss(): full test of batch all strategy (compares with numpy)
test_batch_hard_triplet_loss(): full test of batch hard strategy (compares with numpy)