HashMap线程不安全问题以及解决方法
HashMap线程不安全问题以及解决方法
我们都知道
HashMap是线程不安全的,我们应该使用ConcurrentHashMap。但是为什么HashMap是线程不安全的呢
先声明:HashMap的线程不安全体现在会造成**死循环、数据丢失、数据覆盖**这些问题。其中死循环和数据丢失是在JDK1.7中出现的问题,在JDK1.8中已经得到解决,然而1.8中仍会有数据覆盖这样的问题。
JDK1.7扩容造成死循环和数据丢失的分析
HashMap的线程不安全主要是发生在扩容方法中,即根源是在transfer方法中,JDK1.7中HashMap的transfer方法如下:
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
这段代码是HashMap的扩容操作,重新定位每个桶的下标,并采用头插法将元素迁移到新数组中。头插法会将链表的顺序翻转,这也是形成死循环的关键点。理解了头插法后再继续往下看是如何造成死循环以及数据丢失的。
假设现在有两个线程A、B同时对下面这个HashMap进行扩容操作:
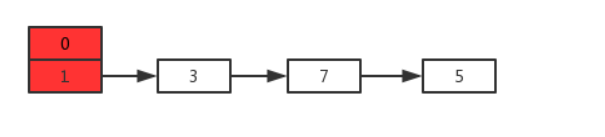
正常扩容后的结果是下面这样的:
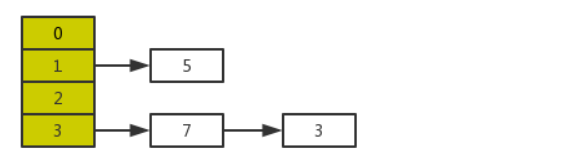
但是当线程A执行到上面transfer函数的第11行代码时,CPU时间片耗尽,线程A被挂起。即如下图中位置所示:

此时线程A中:e=3、next=7、e.next=null
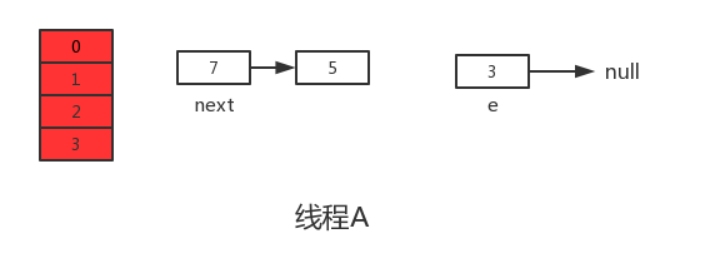
当线程A的时间片耗尽后,CPU开始执行线程B,并在线程B中成功的完成了数据迁移
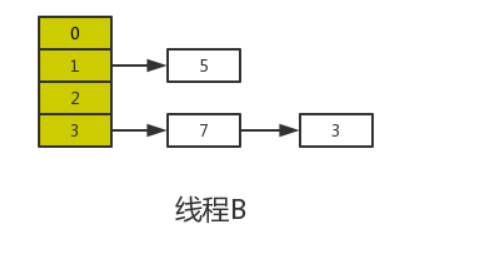
根据Java内存模式可知,线程B执行完数据迁移后,此时主内存中newTable和table都是最新的,也就是说:7.next=3、3.next=null。
随后线程A获得CPU时间片继续执行newTable[i] = e,将3放入新数组对应的位置,执行完此轮循环后线程A的情况如下:

接着继续执行下一轮循环,此时e=7,从主内存中读取e.next时发现主内存中7.next=3,于是乎next=3,并将7采用头插法的方式放入新数组中,并继续执行完此轮循环,结果如下:
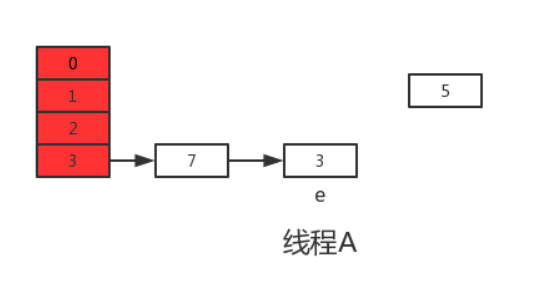
执行下一次循环可以发现,next=e.next=null,所以此轮循环将会是最后一轮循环。接下来当执行完e.next=newTable[i]即3.next=7后,3和7之间就相互连接了,当执行完newTable[i]=e后,3被头插法重新插入到链表中,执行结果如下图所示:
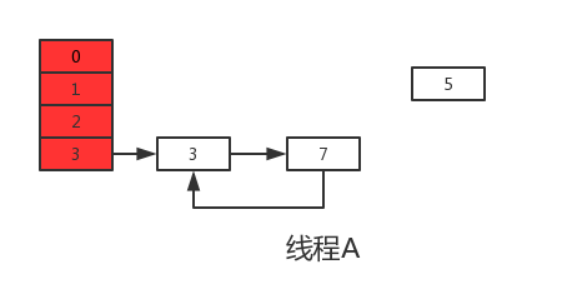
上面说了此时e.next=null即next=null,当执行完e=null后,将不会进行下一轮循环。到此线程A、B的扩容操作完成,很明显当线程A执行完后,HashMap中出现了环形结构,当在以后对该HashMap进行操作时会出现死循环。
并且从上图可以发现,元素5在扩容期间被莫名的丢失了,这就发生了数据丢失的问题。
JDK1.8中的线程不安全
JDK1.8出现的问题在JDK1.8中已经解决,如果你去阅读1.8的源码会发现找不到transfer函数,因为JDK1.8直接在resize函数中完成了数据迁移。另外说一句,JDK1.8在进行元素插入时使用的是尾插法(顺序不会出错)。
但是JDK1.8中会出现数据覆盖的情况
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null) // 如果没有hash碰撞则直接插入元素
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) {
// existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
下面从两个情况分析
- 假设两个线程A、B都在进行put操作,并且hash函数计算出的插入下标是相同的,当线程A执行完putVal方法第六行代码(判断是否出现哈希碰撞)后由于时间片耗尽导致被挂起,而线程B得到时间片后在该下标处插入了元素,完成了正常的插入,然后线程A获得时间片,由于之前已经进行了hash碰撞的判断,所有此时不会再进行判断,而是直接进行插入,这就导致了线程B插入的数据被线程A覆盖了,从而线程不安全。
- 而且在putVal方法的size参数,用来判断HashMap的元素个数,在多线程下,线程A、B,这两个线程同时进行put操作时,假设当前HashMap的size大小为10,当线程A执行**size++**时,从主内存中获得size的值为10后准备进行+1操作,但是由于时间片耗尽只好让出CPU,线程B快乐的拿到CPU还是从主内存中拿到size的值10进行+1操作,完成了put操作并将size=11写回主内存,然后线程A再次拿到CPU并继续执行(此时size的值仍为10),当执行完put操作后,还是将size=11写回内存,此时,线程A、B都执行了一次put操作,但是size的值只增加了1,所有说还是由于数据覆盖又导致了线程不安全。
总结
HashMap的线程不安全主要体现在下面两个方面:
1.在JDK1.7中,当并发执行扩容操作时会造成环形链和数据丢失的情况。
2.在JDK1.8中,在并发执行put操作时会发生数据覆盖的情况。
线程不安全的解决方法
Hashtable(废弃)
HashTable为了实现多线程安全,在几乎所有的方法上都加上了synchronized锁(锁的是类的实例,也就是整个map结构),当一个线程访问 Hashtable 的同步方法时,其他线程如果也要访问同步方法,会被阻塞住。
这种方案已经不怎么使用了,所以就不在这里展开说明
Collections.synchronizedMap(一般不用)
Collections.synchronizedMap()返回一个新的Map的实现
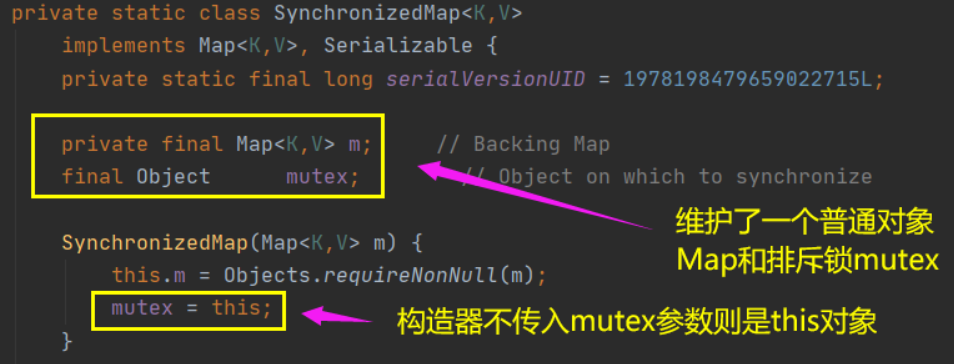
Map<String,String> map = Collections.synchronizedMap(new HashMap<>());
我们在调用上面这个方法的时候就需要传入一个Map,如下图可以看到有两个构造器,如果你传入了mutex参数,则将对象排斥锁赋值为传入的对象。
如果没有,则将对象排斥锁赋值为this,即调用synchronizedMap的对象,就是上面的Map
Collections.synchronizedMap()来封装所有不安全的HashMap的方法
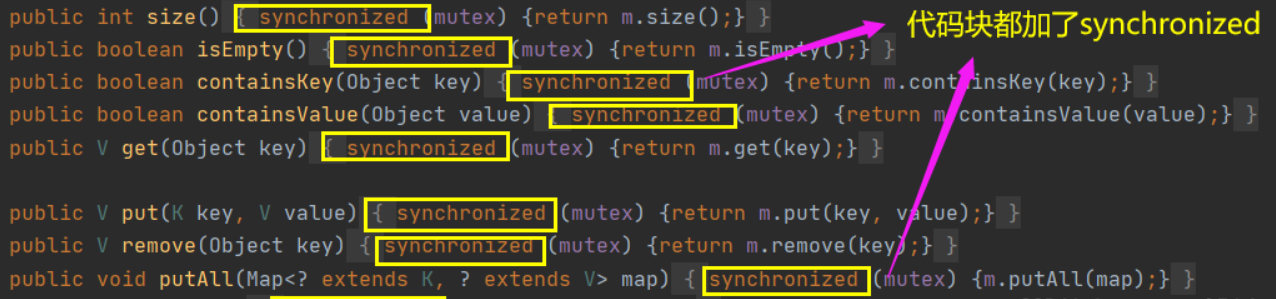
封装的关键点有2处
1)使用了经典的synchronized来进行互斥
2)使用了代理模式new了一个新的类,这个类同样实现了Map接口.在Hashmap上面,synchronized锁住的是对象,所以第一个申请的得到锁,其他线程将进入阻塞,等待唤醒
优点:代码实现十分简单,一看就懂
缺点:从锁的角度来看,基本上是锁住了尽可能大的代码块.性能会比较差
ConcurrentHashMap(常用)
JDK 1.7 中,采用分段锁的机制,实现并发的更新操作,底层采用数组+链表的存储结构,包括两个核心静态内部类 Segment 和 HashEntry。
①、Segment 继承 ReentrantLock(重入锁) 用来充当锁的角色,每个 Segment 对象守护每个散列映射表的若干个桶;
②、HashEntry 用来封装映射表的键-值对;
③、每个桶是由若干个 HashEntry 对象链接起来的链表
分段锁:Segment数组中,一个Segment对象就是一把锁,对应一个HashEntry数组,该数组中的数据同步依赖于同一把锁,不同HashEntry数组的读写互不干扰
JDK 1.8中抛弃了原有的 Segment 分段锁,来保证采用Node + CAS + Synchronized来保证并发安全性。取消类 Segment,直接用table 数组存储键值对;当 Node对象组成的链表长度超过TREEIFY_THRESHOLD 时,链表转换为红黑树,提升性能。底层变更为数组 + 链表 + 红黑树。
CAS性能很高,但synchronized之前一直都是重量级的锁,jdk1.8 引入了synchronized,采用锁升级的方式。
针对 synchronized 获取锁的方式,JVM 使用了锁升级的优化方式,就是先使用偏向锁优先同一线程然后再次获取锁,如果失败,就升级为 CAS 轻量级锁,如果失败就会短暂自旋,防止线程被系统挂起。最后如果以上都失败就升级为重量级锁。
偏向锁:为了在无多线程竞争的情况下尽量减少不必要的轻量级锁执行,始终只有一个线程在执行同步块,在它没有执行完释放锁之前,没有其它线程去执行同步。
轻量级锁:当有两个线程,竞争的时候就会升级为轻量级锁。引入轻量级锁的主要目的是在没有多线程竞争的前提下,减少传统的重量级锁使用操作系统互斥量产生的性能消耗。
重量级锁:大多数情况下,在同一时间点,常常有多个线程竞争同一把锁,悲观锁的方式,竞争失败的线程会不停的在阻塞及被唤醒态之间切换,代价比较大
由于篇幅受限,这里不展ConcurrentHashMap的源码分析,后面有时间,会把详细内容的博客补上。