目录
SGI STL空间配置器
谈一谈为什么需要空间配置器
源于C++new和delete在容器中直接使用的弊端
new=get memory + _construct(T())
delete=free memory + _destroy(~T())
上述这种形式, 单独创建一个对象的时候使用, 完全没有问题. 但是如果在容器书写的时候, 我们直接的使用new + delete去申请容器的底层内存 + 释放容器的底层内存. 是否合理???
内存申请和对象构造的强耦合, 导致仅需要内存申请的时候 存在大量没必要的构造T()
/*
eg : 我自己写了一个vector<int>.
现在我需要先申请一个n = 10的容器.
我本意只是需要这块空间, 但是你却直接给我构造了对象
咋地, 调构造不要钱(调用函数的消耗)是吧
同样, 我析构的时候.它是整个容器都调用了~T(),
但是可能我的有效对象根本没有装满容器
*/
namespace myvector
{
template<class InputIteractor>
void for_each(InputIteractor first, InputIteractor last) {
while (first != last) {
cout << *first++ << " ";
}
cout << endl;
}
template<class T>
class vector {
typedef T* iterator;
typedef const T* const_iterator;
public:
//null obj constructor
vector() : _first(0), _last(0), _end_of_storage(0) {}
vector(int n)
: _first(new T[n]), _last(_first + n), _end_of_storage(_last) {
}
template<class InputIteractor>
vector(InputIteractor first, InputIteractor last)
:_first(0), _last(0), _end_of_storage(0) {
size_t _cap = size_t(last - first);
_first = new T[_cap];
_last = _first + _cap;
_end_of_storage = _last;
iterator iter = _first;
while (first != last) {
(*iter) = *first++;
++iter;
}
}
iterator begin() {
return _first;
}
const_iterator begin() const {
return _first;
}
iterator end() {
return _last;
}
const_iterator end() const {
return _last;
}
size_t size() {
return size_t(_last - _first);
}
size_t capacity() {
return size_t(_end_of_storage - _first);
}
T& operator[](size_t ind) {
return *(_first + ind);
}
const T& operator[](size_t ind) const {
return *(_first + ind);
}
~vector() {
if (_first) {
delete[] _first;
}
_first = nullptr;
_last = nullptr;
_end_of_storage = nullptr;
}
private:
/*
数据结构写法
size_t _size;
size_t _cap;
T* _data;
*/
//stl 迭代器设计
iterator _first;
iterator _last;
iterator _end_of_storage;
//Alloc _allocator;
};
}
int main() {
myvector::vector<Test> ve(5);
return 0;
}ans

上述想表达啥意思??? 我后序如果需要插入元素, 我自己会创建元素插入, 但是我此时仅仅只是需要这样一个空间, 但是直接使用new之后的结果则是给每个对象都调用了一次T()构造了一次
浪费. 几个对象, 或者默认构造不复杂还OK, 如果对象数目大,或者构造耗时长. 这个也许是一个性能的退化.
所以分离内存管理 + 对象管理是一个可以优化的点. Allocator空间配置器作为第二个参数, 独立容器内存的分配管理很有必要
看如下版本
//其他几乎是一摸一样的和数据结构的正常写法, 核心所在就是那点iterator的设计.
namespace myvector
{
template<class T>
struct Allocator {
T* allocate(size_t size) {//仅malloc
cout << "allocate: " << size << endl;
return (T*)malloc(sizeof(T) * size);
}
void deallocate(void* p) {//仅free
cout << "deallocate" << endl;
free(p);
}
void constructor(T* p, const T& val) {//定位new
cout << "place new" << endl;
new (p) T(val); //定位 new
}
void destroy(T* p) {//仅销毁对象资源
cout << "destroy" << endl;
p->~T();//调用析构
}
};
template<class InputIteractor>
void for_each(InputIteractor first, InputIteractor last) {
while (first != last) {
cout << *first++ << " ";
}
cout << endl;
}
template<class T, class Alloc = Allocator<T>>
class vector {
typedef T* iterator;
typedef const T* const_iterator;
public:
//null obj constructor
vector() : _first(0), _last(0), _end_of_storage(0) {}
vector(int n) {
_first = _allocator.allocate(n);
_last = _first;//起始没有元素
_end_of_storage = _first + n;
}
template<class InputIteractor>
vector(InputIteractor first, InputIteractor last)
:_first(0), _last(0), _end_of_storage(0) {
size_t _cap = size_t(last - first);
_first = new T[_cap];
_last = _first + _cap;
_end_of_storage = _last;
iterator iter = _first;
while (first != last) {
(*iter) = *first++;
++iter;
}
}
iterator begin() {
return _first;
}
const_iterator begin() const {
return _first;
}
iterator end() {
return _last;
}
const_iterator end() const {
return _last;
}
size_t size() {
return size_t(_last - _first);
}
size_t capacity() {
return size_t(_end_of_storage - _first);
}
T& operator[](size_t ind) {
return *(_first + ind);
}
const T& operator[](size_t ind) const {
return *(_first + ind);
}
~vector() {//消除内存 + 析构有效空间对象
//先析构有效对象
for (int i = 0; i < size(); ++i) {
_allocator.destroy(_first + i);
}
_allocator.deallocate(_first);//free内存
_first = nullptr;
_last = nullptr;
_end_of_storage = nullptr;
}
private:
/*
数据结构写法
size_t _size;
size_t _cap;
T* _data;
*/
//stl 迭代器设计
iterator _first;
iterator _last;
iterator _end_of_storage;
Alloc _allocator;
};
}ans
完全给避免了没有必要的T()和~T()调用
Alloc是可以进行选择的. 说明存在多种空间配置器. 甚至我们可以自己实现. 同样, STL中也是提供了两种不同的Alloc空间配置器. 底层采取宏定义的形式限制默认空间配置器是alloc ( 二级空间配置器SGI STL内存池 )
一级空间配置器
本质上其实就是glibc中的malloc 和 free.
直接使用OK吗? OK, 内存直接交给用户去向系统申请。是否存在问题, 存在, 用户申请的内存很可能是没有规律的小块内存. 大量的小块内存的申请会带来内存碎片. 导致大内存的申请失败.
如下的_malloc_alloc_template就是allocator (T )追溯到最后的一级空间配置器类
一级空间配置器函数细节分析
//SGI Allocator相较于operator new的优势所在一.
static void* _S_oom_malloc(size_t);
static void* _S_oom_realloc(void*, size_t);
#ifndef __STL_STATIC_TEMPLATE_MEMBER_BUG
static void (* __malloc_alloc_oom_handler)();
//oom: out of memory 内存溢出, 内存不足的意思.SGI SIL 多出来的_S_oom_malloc + _S_oom_realloc 功能是干啥? 往下追溯一下
template <int __inst>
void*
__malloc_alloc_template<__inst>::_S_oom_malloc(size_t __n)
{
void (* __my_malloc_handler)();//malloc_handler: 回调处理函数
void* __result;
/*
while (set alloc_oom_handler)
循环不断的执行handler
直至 malloc sucess.
if (not set alloc_oom_handler)
throw bad_alloc();
*/
for (;;) {
__my_malloc_handler = __malloc_alloc_oom_handler;
if (0 == __my_malloc_handler) { __THROW_BAD_ALLOC; }
(*__my_malloc_handler)();
__result = malloc(__n);
if (__result) return(__result);
}
}其实刨析一个函数足以, Allocator 一级空间配置器相较于全局 operator new 的优势所在...
-
上述优势依然明了, 就是可以在系统内存不足OOM的 情况下询问是否设置了内存释放的callback. 此callback必须保证能够释放出有效内存. 也就是我们确保为整个程序的正常运行设置的预留可free 内存. 否则恐存在陷入无穷无尽死循环的风险.
二级空间配置器

抓主干, 先看懂重要的成员函数 + 数据成员
#if ! (defined(__SUNPRO_CC) || defined(__GNUC__))
enum {_ALIGN = 8};
enum {_MAX_BYTES = 128};
enum {_NFREELISTS = 16}; // _MAX_BYTES/_ALIGN
???? 啥意思??? 三个enum给我甩出来了
-
ALIGN: 对齐, 排齐, 排列的意思. 其实就是对齐字节数. 所分配的内存一定是ALIGN的整数倍. 内存分配按照ALIGN对齐
-
—MAX_BYTES最大字节数, 可分配的最大字节数. 内存池上限
-
NFREELISTS = (MAX_BYTES / _ALIGN) 自由链表个数后序细说含义
union _Obj {
union _Obj* _M_free_list_link;
char _M_client_data[1]; /* The client sees this.*/
};
//静态数据成员, _S_free_list
static _Obj* __STL_VOLATILE _S_free_list[_NFREELISTS];
要理解上述元素结构定义+成员定义. 我们必须对于union联合体有着一定的认知
-
union: 一段内存, 在不同的场景有着不同的含义, 存储不同的身份. 但是公用一块内存空间. 有点像人格分裂. 在不同的特殊场景下采用不同的人格, 但是本质上都是一个存储空间.
-
上述的_Obj定义非常之巧妙. 占 4 byte空间大小. 充当不同身份. 内存池中充当自由链表头部list_link. 在分配出去的时候充当client_data. 数据空间
-
下面这副图基本就是整个SGI STL内存池的核心所在. 后序会更加细节讲述为啥要这样设计, 为啥一定要采用free_list, 而不是直接用动态链表. 而且SGI STL牛逼之处还远不止下面这一点

//上调取ALIGN整数倍函数
static size_t
_S_round_up(size_t __bytes)
{ return (((__bytes) + (size_t) _ALIGN-1) & ~((size_t) _ALIGN - 1)); }
//Obj* 数组下标定位函数
static size_t _S_freelist_index(size_t __bytes) {
return (((__bytes) + (size_t)_ALIGN-1)/(size_t)_ALIGN - 1);
}-
如何理解上述两个函数, 可谓是经常在源代码中见到. 特别是round_up. 用于字节对齐, 特常见.
-
(size_t) 是强制转换为4 bytes.
-
((size_t)_ALIGN - 1) 8 - 1 = 7 = 0000 0000 0000 0000 0000 0000 0000 0111
-
~((size_t)_ALIGN - 1) = 1111 1111 1111 1111 1111 1111 1111 1000
-
any number & ~((size_t)_ALIGN - 1) 必然只剩下了 _ALIGN二进制整数倍位之前的位了. 后面的非整数倍低位全部&0 = 0 了
-
eg:8 & ~((size_t)ALIGN - 1) = 8 11 & ~((size_t)ALIGN - 1) = 8 16 & ~((size_t)_ALIGN - 1) = 16
-
我们还需要round_up向上取整数倍. 所以左边仍需要 (__bytes) + (size_t) _ALIGN-1操作
上述思路同理可以推到index函数
static char* _S_start_free; //当前空闲内存起点
static char* _S_end_free; //空闲内存末尾
static size_t _S_heap_size; //已利用内存, 用于make free_list的内存
//上述静态成员数据的初始化
template <bool __threads, int __inst>
char* __default_alloc_template<__threads, __inst>::_S_start_free = 0;
template <bool __threads, int __inst>
char* __default_alloc_template<__threads, __inst>::_S_end_free = 0;
template <bool __threads, int __inst>
size_t __default_alloc_template<__threads, __inst>::_S_heap_size = 0;allocate(int size); 内存分配函数
/* __n must be > 0 */
static void* allocate(size_t __n)
{
void* __ret = 0;
if (__n > (size_t) _MAX_BYTES) { //超过内存池最大限制
__ret = malloc_alloc::allocate(__n);//采取malloc
}
else {//从内存池中获取内存
_Obj* volatile* __my_free_list
= _S_free_list + _S_freelist_index(__n); //指向对应chunk块所在自由链表表头
# ifndef _NOTHREADS
_Lock __lock_instance; //智能锁. 线程安全, 操作内存池(全局资源, 多线程共享)
# endif
//尝试获取头部chunk块
_Obj* __RESTRICT __result = *__my_free_list;//拿取头部
if (__result == 0)
__ret = _S_refill(_S_round_up(__n));//填充chunk块free_list并return head chunk块
else {//chunk块free_list not null 拿走头部chunk块, 并且进行pop_front
*__my_free_list = __result -> _M_free_list_link;
__ret = __result;
}
}
return __ret;
};在此之前, 先来点指针级别基础, 不然怕理解不了.
-
_Obj* 作为数组元素, 相当于数组中元素是一级指针类型
-
所以遍历数组的指针应该是指向_Obj*类型的指针, 也就应该是 _Obj** 类型的指针
-
上述还不好理解的话,想一想int 数组遍历的指针为int* . int* 数组的遍历指针肯定应该是int **. so 上述同理。
-
Obj** 的指针进行解引用, 其中存储的就是 _Obj* 也就是第一个chunk块. _free_list的 head node
-
volatile 禁止编译器优化.
简单画图理解一下下.
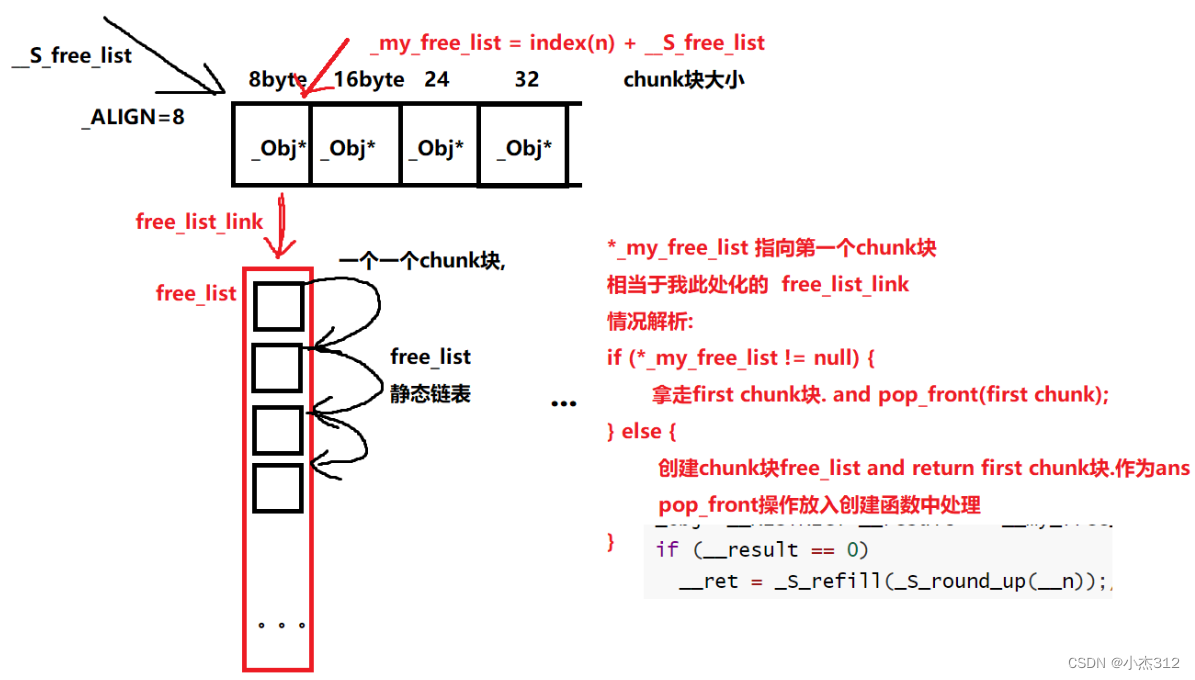
接下来看的就是_S_refill() 究竟是如何创建并且填充 chunk_free_list的
template <bool __threads, int __inst>
void*
__default_alloc_template<__threads, __inst>::_S_refill(size_t __n)
{
int __nobjs = 20; //数目. chunk块数目
char* __chunk = _S_chunk_alloc(__n, __nobjs);//alloc 先分配内存. 貌似就是一维数组
_Obj* volatile* __my_free_list;
_Obj* __result;
_Obj* __current_obj; //当前对象, 也就是记录当前chunk块
_Obj* __next_obj; //下一个chunk块
int __i;
if (1 == __nobjs) return(__chunk);//只有一个chunk块, 直接return
/*
往下必然是超过一个chunk块了, 干啥??? 不可以直接return ???
上述仅仅create memory了. 我们需要的是链表, _free_list. so: 必然是分割memory为chunk块并且link起来
*/
__my_free_list = _S_free_list + _S_freelist_index(__n);//拿到对应chunk块head node
/* Build free list in chunk */
__result = (_Obj*)__chunk;// get ans chunk
*__my_free_list = __next_obj = (_Obj*)(__chunk + __n);//pop_front
for (__i = 1; ; __i++) {//link 操作n 个node link n-1次 + pop_front, so link objs-2次
__current_obj = __next_obj;
__next_obj = (_Obj*)((char*)__next_obj + __n);
if (__nobjs - 1 == __i) {
__current_obj -> _M_free_list_link = 0;
break;
} else {
__current_obj -> _M_free_list_link = __next_obj;
}
}
return(__result);
}/*
按照我上面这样的分析策略, 我猜,接下来你肯定能知道我要分析哪一个函数了. 对的没错,就是它:
chunk_alloc. chunk_list的内存究竟如何分配的. 如何能做到内存的最大利用, 最少的碎片。 精华在此处
*/
/*我滴妈呀. 真的好大. 有这么麻烦么?? 直接分配objs个chunk块 return 不就OK了么, 错,那是我们这种寻常人的想法, 但是写库的能是凡人嘛. 采取一种每次申请2倍甚至更多的memory. 申请的memory size 随着我们已经申请的memory数目变大而变大
好处何在?
竟然已经申请的内存越来越大,说明向内存池申请内存太频繁了. 我们就一次给多一点, 避免不停的需要chunk_alloc
*/
template <bool __threads, int __inst>
char*
__default_alloc_template<__threads, __inst>::_S_chunk_alloc(size_t __size,
int& __nobjs)
{
char* __result;
size_t __total_bytes = __size * __nobjs;//需要申请的总内存量
size_t __bytes_left = _S_end_free - _S_start_free;//剩余空闲内存量
if (__bytes_left >= __total_bytes) {
__result = _S_start_free;
_S_start_free += __total_bytes;
return(__result);
} else if (__bytes_left >= __size) {
__nobjs = (int)(__bytes_left/__size);
__total_bytes = __size * __nobjs;
__result = _S_start_free;
_S_start_free += __total_bytes;
return(__result);
} else {
/*
各位大爷, 我们先不看上面那两种特殊情况, 那也不是人想出来的.
我们先看下面正常情况. 正常来讲肯定是内存不足. bytes_left < _total_bytes.
我们才走到了再次alloc的情景下. 只要有内存,谁没事去alloc, 系统调用不要钱是吧
*/
size_t __bytes_to_get =
2 * __total_bytes + _S_round_up(_S_heap_size >> 4);
// Try to make use of the left-over piece.
if (__bytes_left > 0) {
_Obj* __STL_VOLATILE* __my_free_list =
_S_free_list + _S_freelist_index(__bytes_left);
((_Obj*)_S_start_free) -> _M_free_list_link = *__my_free_list;
*__my_free_list = (_Obj*)_S_start_free;
}
_S_start_free = (char*)malloc(__bytes_to_get);
if (0 == _S_start_free) {
size_t __i;
_Obj* __STL_VOLATILE* __my_free_list;
_Obj* __p;
// Try to make do with what we have. That can't
// hurt. We do not try smaller requests, since that tends
// to result in disaster on multi-process machines.
for (__i = __size;
__i <= (size_t) _MAX_BYTES;
__i += (size_t) _ALIGN) {
__my_free_list = _S_free_list + _S_freelist_index(__i);
__p = *__my_free_list;
if (0 != __p) {
*__my_free_list = __p -> _M_free_list_link;
_S_start_free = (char*)__p;
_S_end_free = _S_start_free + __i;
return(_S_chunk_alloc(__size, __nobjs));
// Any leftover piece will eventually make it to the
// right free list.
}
}
_S_end_free = 0; // In case of exception.
_S_start_free = (char*)malloc_alloc::allocate(__bytes_to_get);
// This should either throw an
// exception or remedy the situation. Thus we assume it
// succeeded.
}
_S_heap_size += __bytes_to_get;
_S_end_free = _S_start_free + __bytes_to_get;
return(_S_chunk_alloc(__size, __nobjs));
}
}如下才是真正需要从系统malloc的主干code. if (malloc()==0)的特殊处理, 暂时被移除出去了, 先研究正常的逻辑, 先抓住功能核心. 再到细节.
size_t __bytes_to_get = //need malloc(__bytes_to_get) 用于 make _memory_free_list
2 * __total_bytes + _S_round_up(_S_heap_size >> 4);
//之前剩余的空闲内存__bytes_left > 0. 我们扔掉? NO 想办法利用起来
if (__bytes_left > 0) {
_Obj* volatile* __my_free_list =
_S_free_list + _S_freelist_index(__bytes_left);
//头部插入到可以插入的小chunk块. 将剩余的small memory利用起来
((_Obj*)_S_start_free) -> _M_free_list_link = *__my_free_list;
*__my_free_list = (_Obj*)_S_start_free;
}
//为内存池扩充内存. 产生 _chunk_free_list to provide chunk for user
_S_start_free = (char*)malloc(__bytes_to_get);
_S_heap_size += __bytes_to_get;//已利用的内存增加,制作成chunk_free_list的内存部分
_S_end_free = _S_start_free + __bytes_to_get;//跳过已用于制作chunk_free_list内存
return(_S_chunk_alloc(__size, __nobjs));//递归调用, 精髓在于前面的两个if//分析一下if(malloc()==0)的处理模块
if (0 == _S_start_free) {
size_t __i;
_Obj* volatile* __my_free_list;
_Obj* __p;
/*
如下做出的努力是什么嘛, 说白了,malloc失败, 应该是oof了. 系统内存不足. 所以如下做出的努力是在其他的_chunk_free_list寻找希望. 希望找这些已利用内存,哥们. 我实在坚持不住了, 你看看能借我一个chunk块不. 但是这个借了,我也没能力偿还. 相当于强者拉一把弱者
*/
for (__i = __size;//从need one chunk memory size 之后的_chunk_free_list做出努力
__i <= (size_t) _MAX_BYTES;
__i += (size_t) _ALIGN) {
__my_free_list = _S_free_list + _S_freelist_index(__i);
__p = *__my_free_list;
if (0 != __p) {
*__my_free_list = __p -> _M_free_list_link;
_S_start_free = (char*)__p;
_S_end_free = _S_start_free + __i;
return(_S_chunk_alloc(__size, __nobjs));
}
}
//走到此处. 真的是弹尽粮绝了, 兄弟们都饿呀.
//你还是再去系统仓库撞撞运气吧.
_S_end_free = 0; // In case of exception.
_S_start_free = (char*)malloc_alloc::allocate(__bytes_to_get);
}
至于此处, 我们在研究研究前面两个if究竟是干嘛的
//内存够了, 咋可能突然足够make chunk_free_list,
//必然是之前走了malloc. 对内存池扩充了可用内存
if (__bytes_left >= __total_bytes) {
__result = _S_start_free;
_S_start_free += __total_bytes;
return(__result);//真正的return memory逻辑. 将搞内存和return 内存分开
}
//下面这个是个狠人逻辑. 虽然不足以整个__total_bytes 的分配, 但是我暂时还不想去malloc. 内存物尽其用. 能分配几个chunk块, 就利用起来产生几个chunk块咯. 总不能丢掉这点直接去从新malloc内存池吧.
//牛逼之处, 真的做到了一丁点不浪费, 边角料大不了少做几个
else if (__bytes_left >= __size) {
__nobjs = (int)(__bytes_left/__size);
__total_bytes = __size * __nobjs;
__result = _S_start_free;
_S_start_free += __total_bytes;
return(__result);
}eg: 上述逻辑是分析完了, 但是貌似都是写干说, 真正要想理解深刻其实还是画图借助思考
-
eg:我首先申请第一个7 bytes 内存.
-
然后申请15 bytes内存

基本剧终了
-
另外一个比较重要的函数就是deallocate. 但是我觉得至此,聪明的各位绝对知晓了,deallocate该干啥, 没错就是将用完的chunk块归还到chunk_free_list待其他人使用
-
你可能想说,还有这么多加锁,确实,对于内存池整个全局资源的操作可能是多线程的, 所以需要加上一个局部对象的智能锁, 他这里写的牛逼, 其实本质还是RAII技术
static void deallocate(void* __p, size_t __n)
{
if (__n > (size_t) _MAX_BYTES)
malloc_alloc::deallocate(__p, __n);
else {
_Obj* volatile* __my_free_list
= _S_free_list + _S_freelist_index(__n);
_Obj* __q = (_Obj*)__p;
// acquire lock
# ifndef _NOTHREADS
/*REFERENCED*/
_Lock __lock_instance;
# endif /* _NOTHREADS */
__q -> _M_free_list_link = *__my_free_list;
*__my_free_list = __q;
// lock is released here
}
}-
至此,小杰仅以粗俗己见, 跟大家分享一些技术上学习的技巧, 从主干到细节, 从框架到细节, 一定要真的抓住框架, 少一些跟着别人写. 不然那样自己会成长的很慢
-
重要的小模块也要多写, 我们cpp程序员确实少不了造轮子的命, 这多少枯燥了些, 但是想想以后一个好的工作, 生活的压力少一些还是好的. 单独的轮子都会造之后,最好的多看看一些框架, github上的一些知名项目. 虽然这样看,短期貌似你的代码量提升不大, 但是长期来看,这样是真正对自己整体实力提升最大的