目录
1、k-means聚类的两个问题
k-means聚类有两个重要的问题:
1、如何表示样本与样本之间的距离,常见的欧氏距离 。
欧式距离是欧几里得空间中两点间“普通”(即直线)距离,二维空间计算公式为:
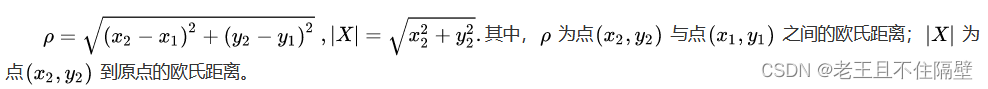
2、分为几个类
这个问题暂时没有很好的见解,通过SSE手肘法和看轮廓系数来分析数据,大致判断聚类数目,可以参考博主lzzzzzzm对这一块的分析。
2、算法流程
1 、手动设定簇的个数k,假设k=9。
2 、在所有样本中随机选取k个样本作为簇的初始中心。
3 、计算每个样本离每个簇中心的距离(这里以欧式距离为例),然后将样本划分到离它最近的簇中。
4、 更新簇的中心,计算每个簇中所有样本的均值(方法不唯一)作为新的簇中心。
5 、重复第3步到第4步直到簇中心不在变化或者簇中心变化很小满足给定终止条件,最终聚类结果。
2.1、VOC数据集格式
代码中只用到了VOC文件中的Annotation文件夹下的xml文件(就是我们自己用工具给图片画框的信息)
即按如下方式创建文件夹保存xml文件:
VOCdevkit:
--VOC2012
--Annotation(该文件夹下存在自己的xml文件)
代码中调用的k-means好像是k-means++算法,两者算法流程大致相同,k-means++在开始时的处理有改动,可自行百度。
聚类自己的数据集要注意两点:
1、将数据集(你自己的数据xml文件)和代码文件(将下面代码复制在pycharm新建py文件)放在同一目录下。
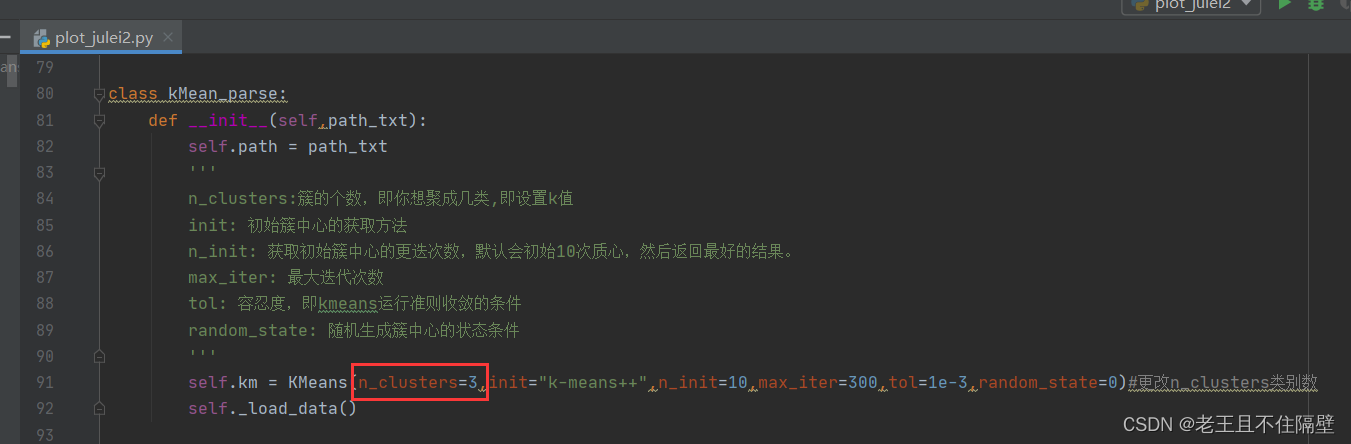
2、修改聚类个数参数n_clusters(可以在pycharm中ctrl +f,输入n_clusters快速找到参数的位置)修改xml文件的路径,在代码最末尾。
这两处修改点如下图:

2.2、代码
代码如下:(如果有报模块错误,就pip install 模块名字 安装一下相应的环境,下面用numpy,lxml, matplotlib等库)
#!/usr/bin/env python
# -*- coding: utf8 -*-
import sys
from xml.etree import ElementTree
from xml.etree.ElementTree import Element, SubElement
from lxml import etree
import numpy as np
import os
import sys
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
XML_EXT = '.xml'
ENCODE_METHOD = 'utf-8'
#pascalVocReader readers the voc xml files parse it
class PascalVocReader:
"""
this class will be used to get transfered width and height from voc xml files
"""
def __init__(self, filepath,width,height):
# shapes type:
# [labbel, [(x1,y1), (x2,y2), (x3,y3), (x4,y4)], color, color, difficult]
self.shapes = []
self.filepath = filepath
self.verified = False
self.width=width
self.height=height
try:
self.parseXML()
except:
pass
def getShapes(self):
return self.shapes
def addShape(self, bndbox, width,height):
xmin = int(bndbox.find('xmin').text)
ymin = int(bndbox.find('ymin').text)
xmax = int(bndbox.find('xmax').text)
ymax = int(bndbox.find('ymax').text)
width_trans = (xmax - xmin)/width*self.width
height_trans = (ymax-ymin)/height *self.height
points = [width_trans,height_trans]
self.shapes.append((points))
def parseXML(self):
assert self.filepath.endswith(XML_EXT), "Unsupport file format"
parser = etree.XMLParser(encoding=ENCODE_METHOD)
xmltree = ElementTree.parse(self.filepath, parser=parser).getroot()
pic_size = xmltree.find('size')
size = (int(pic_size.find('width').text),int(pic_size.find('height').text))
for object_iter in xmltree.findall('object'):
bndbox = object_iter.find("bndbox")
self.addShape(bndbox, *size)
return True
class create_w_h_txt:
def __init__(self,vocxml_path,txt_path):
self.voc_path = vocxml_path
self.txt_path = txt_path
def _gether_w_h(self):
pass
def _write_to_txt(self):
pass
def process_file(self):
file_w = open(self.txt_path,'w')
# print (self.txt_path)
for file in os.listdir(self.voc_path):
file_path = os.path.join(self.voc_path, file)
xml_parse = PascalVocReader(file_path,416,416)#设置图片归一化大小
data = xml_parse.getShapes()
for w,h in data :
txtstr = str(w)+' '+str(h)+'\n'
#print (txtstr)
file_w.write(txtstr)
file_w.close()
class kMean_parse:
def __init__(self,path_txt):
self.path = path_txt
'''
n_clusters:簇的个数,即你想聚成几类,即设置k值
init: 初始簇中心的获取方法
n_init: 获取初始簇中心的更迭次数,默认会初始10次质心,然后返回最好的结果。
max_iter: 最大迭代次数
tol: 容忍度,即kmeans运行准则收敛的条件
random_state: 随机生成簇中心的状态条件
'''
self.km = KMeans(n_clusters=3,init="k-means++",n_init=10,max_iter=300,tol=1e-3,random_state=0)#更改n_clusters类别数
self._load_data()
def _load_data (self):
self.data = np.loadtxt(self.path)
def parse_data (self):
self.y_k = self.km.fit_predict(self.data)
print(self.km.cluster_centers_)
def plot_data (self):
plt.scatter(self.data[self.y_k == 0, 0], self.data[self.y_k == 0, 1], s=15, c="orange", marker="o")
plt.scatter(self.data[self.y_k == 1, 0], self.data[self.y_k == 1, 1], s=15, c="green", marker="o")
plt.scatter(self.data[self.y_k == 2, 0], self.data[self.y_k == 2, 1], s=15, c="blue", marker="o")
plt.scatter(self.data[self.y_k == 3, 0], self.data[self.y_k == 3, 1], s=15, c="red", marker="o")
plt.scatter(self.data[self.y_k == 4, 0], self.data[self.y_k == 4, 1], s=15, c="yellow", marker="o")
plt.scatter(self.data[self.y_k == 5, 0], self.data[self.y_k == 5, 1], s=15, c="black", marker="o")
plt.scatter(self.data[self.y_k == 6, 0], self.data[self.y_k == 6, 1], s=15, c="gray", marker="o")
plt.scatter(self.data[self.y_k == 7, 0], self.data[self.y_k == 7, 1], s=15 ,c="pink", marker="o")
plt.scatter(self.data[self.y_k == 8, 0], self.data[self.y_k == 8, 1], s=15, c="purple", marker="o")
# draw the centers
plt.scatter(self.km.cluster_centers_[:, 0], self.km.cluster_centers_[:, 1], s=50, marker="*", c="gold")#五角星大小颜色设置
plt.legend()
plt.grid()
plt.show()
if __name__ == '__main__':
whtxt = create_w_h_txt("./VOCdevkit/VOC2012/Annotation" , "./data1.txt") #指定为voc中xml文件夹路径;data1.txt保存迭代过程点集
whtxt.process_file()
kmean_parse = kMean_parse("./data1.txt")#路径和生成文件相同。
kmean_parse.parse_data()
kmean_parse.plot_data()
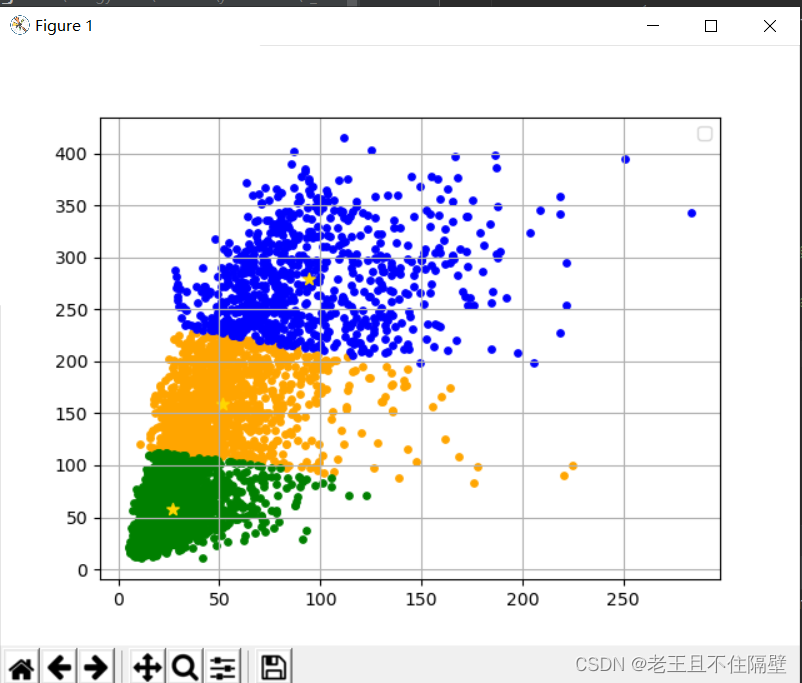
效果图大致如下:(设置的聚类3个)