Grep
过滤来自一个文件或标准输入匹配模式内容。
除了grep外,还有egrep、fgrep。egrep是grep的扩展,相当于grep -E。fgrep相当于grep -f,用的少。
Usage: grep [OPTION]… PATTERN [FILE]…
| 支持的正则 |
描述 |
| -E,–extended-regexp |
模式是扩展正则表达式(ERE) |
| -P,–perl-regexp |
模式是Perl正则表达式 |
| -e,–regexp=PATTERN |
使用模式匹配,可指定多个模式匹配 |
| -f,–file=FILE |
从文件每一行获取匹配模式 |
| -i,–ignore-case |
忽略大小写 |
| -w,–word-regexp |
模式匹配整个单词 |
| -x,–line-regexp |
模式匹配整行 |
| -v,–invert-match |
打印不匹配的行 |
| 输出控制 |
描述 |
| -m,–max-count=NUM |
输出匹配的结果num数 |
| -n,–line-number |
打印行号 |
| -H,–with-filename |
打印每个匹配的文件名 |
| -h,–no-filename |
不输出文件名 |
| -o,–only-matching |
只打印匹配的内容 |
| -q,–quiet |
不输出正常信息 |
| -s, --no-messages |
不输出错误信息 |
| -r,–recursive |
递归目录 |
| -c,–count |
只打印每个文件匹配的行数 |
| –include=FILE_PATTERN |
只检索匹配的文件 |
| –exclude=FILE_PATTERN |
跳过匹配的文件 |
| –exclude-from=FILE |
跳过匹配的文件,来自文件模式 |
| –exclude-dir=PATTERN |
跳过匹配的目录 |
| 内容行控制 |
描述 |
| -B,–before-context=NUM |
打印匹配的前几行 |
| -A,–after-context=NUM |
打印匹配的后几行 |
| -C,–context=NUM |
打印匹配的前后几行 |
| –color[=WHEN] |
匹配的字体颜色 |
sed
流编辑器,过滤和替换文本。
工作原理:sed命令将当前处理的行读入模式空间进行处理,处理完把结果输出,并清空模式空间。然后再将下一行读入模式空间进行处理输出,以此类推,直到最后一行。还有一个空间叫保持空间,又称暂存空间,可以暂时存放一些处理的数据,但不能直接输出,只能放到模式空间输出。
这两个空间其实就是在内存中初始化的一个内存区域,存放正在处理的数据和临时存放的数据
Usage:
sed [OPTION]… {script-only-if-no-other-script} [input-file]…
sed [选项] ‘地址 命令’ file
| 选项 |
描述 |
| -n |
不打印模式空间 |
| -e |
执行脚本、表达式来处理 |
| -f |
执行动作从文件读取执行 |
| -i |
修改原文件 |
| -r |
使用扩展正则表达式 |
| 命令 |
描述 |
| s/regexp/replacement/ |
替换字符串 |
| p |
打印当前模式空间 |
| P |
打印模式空间的第一行 |
| d |
删除模式空间,开始下一个循环 |
| D |
删除模式空间的第一行,开始下一个循环 |
| = |
打印当前行号 |
| a \text |
当前行追加文本 |
| i \text |
当前行上面插入文本 |
| c \text |
所选行替换新文本 |
| q |
立即退出sed脚本 |
| r |
追加文本来自文件 |
| : label |
label为b和t命令 |
| b label |
分支到脚本中带有标签的位置,如果分支不存在则分支到脚本的末尾 |
| t label |
如果s///是一个成功的替换,才跳转到标签 |
| h H |
复制/追加模式空间到保持空间 |
| g G |
复制/追加保持空间到模式空间 |
| x |
交换模式空间和保持空间内容 |
| l |
打印模式空间的行,并显示控制字符$ |
| n N |
读取/追加下一行输入到模式空间 |
| w filename |
写入当前模式空间到文件 |
| ! |
取反、否定 |
| & |
引用已匹配字符串 |
| 地址 |
描述 |
| first~step |
步长,每step行,从第first开始 |
| $ |
匹配最后一行 |
| /regexp/ |
正则表达式匹配行 |
| number |
只匹配指定行 |
| addr1,addr2 |
开始匹配addr1行开始,直接addr2行结束 |
| addr1,+N |
从addr1行开始,向后的N行 |
| addr1,~N |
从addr1行开始,到N行结束 |
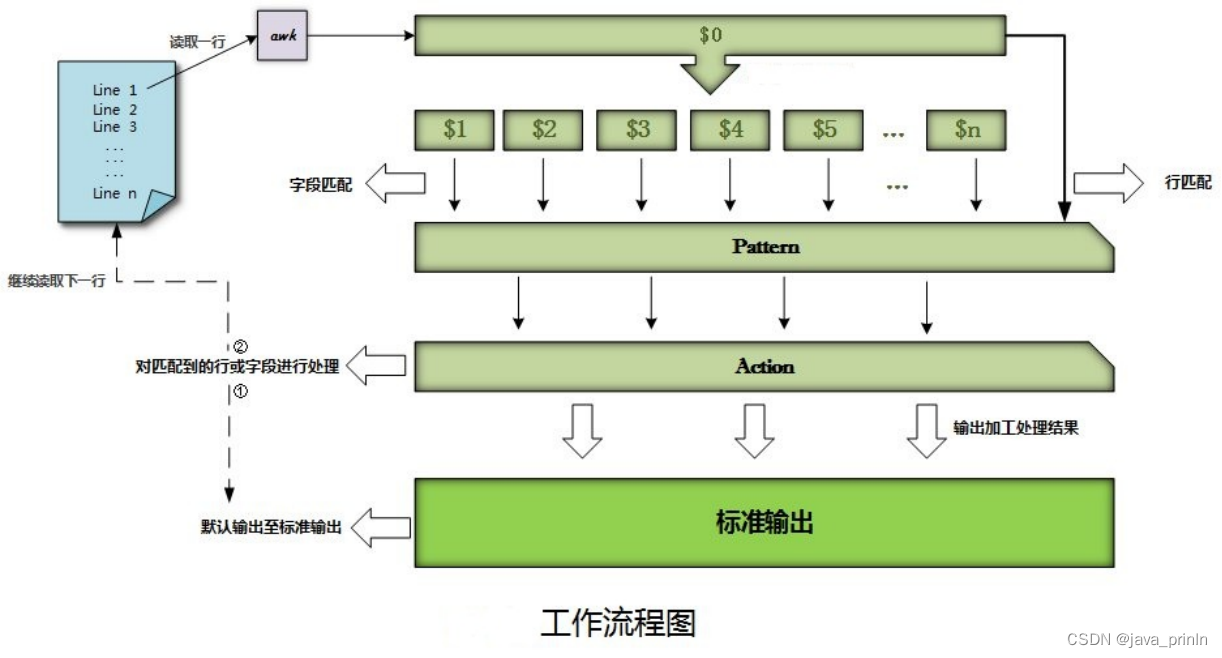
awk
awk是一个处理文本的编程语言工具,能用简短的程序处理标准输入或文件、数据排序、计算以及生成报表等等。
在Linux系统下默认awk是gawk,它是awk的GNU版本。可以通过命令查看应用的版本:ls -l /bin/awk
基本的命令语法:awk option ‘pattern {action}’ file
其中pattern表示AWK在数据中查找的内容,而action是在找到匹配内容时所执行的一系列命令。花括号用于根据特定的模式对一系列指令进行分组。
awk处理的工作方式与数据库类似,支持对记录和字段处理,这也是grep和sed不能实现的。
在awk中,缺省的情况下将文本文件中的一行视为一个记录,逐行放到内存中处理,而将一行中的某一部分作为记录中的一个字段。用1,2,3…数字的方式顺序的表示行(记录)中的不同字段。用$后跟数字,引用对应的字段,以逗号分隔,0表示整个行。
| Pattern |
Description |
| BEGIN{ } |
给程序赋予初始状态,先执行的工作 |
| END{ } |
程序结束之后执行的一些扫尾工作 |
| /regular expression/ |
为每个输入记录匹配正则表达式 |
| pattern && pattern |
逻辑and,满足两个模式 |
| pattern |
|
| ! pattern |
逻辑not,不满足模式 |
| pattern1, pattern2 |
范围模式,匹配所有模式1的记录,直到匹配到模式2 |
find
功能:目录层次结构中搜索文件
格式:find path -option actions
常用选项:
-name 文件名,支持(‘*’, ‘?’)
-type 文件类型,d目录,f常规文件等
-perm 符合权限的文件,比如755
-atime -/+n 在n天以内/过去n天被访问过
-ctime -/+n 在n天以内/过去n天被修改过
-amin -/+n 在n天以内/过去n分钟被访问过
-cmin -/+n 在n天以内/过去n分钟被修改过
-size -/+n 文件大小小于/大于,b、k、M、G
-maxdepth levels 目录层次显示的最大深度
-regex pattern 文件名匹配正则表达式模式
-inum 通过inode编号查找文件
动作:
-detele 删除文件
-exec command {} ; 执行命令,花括号代表当前文件
-ls 列出当前文件,ls -dils格式
-print 完整的文件名并添加一个回车换行符
-print0 打印完整的文件名并不添加一个回车换行符
-printf format 打印格式
其他字符:
! 取反
-or/-o 逻辑或
-and 逻辑和