文章目录
建数据表
/opt/datafiles/dept.txt
10 ACCOUNTING 1700
20 RESEARCH 1800
30 SALES 1900
40 OPERATIONS 1700
/opt/datafiles/emp.txt
7369 SMITH CLERK 7902 1980-12-17 800.00 20
7499 ALLEN SALESMAN 7698 1981-2-20 1600.00 300.00 30
7521 WARD SALESMAN 7698 1981-2-22 1250.00 500.00 30
7566 JONES MANAGER 7839 1981-4-2 2975.00 20
7654 MARTIN SALESMAN 7698 1981-9-28 1250.00 1400.00 30
7698 BLAKE MANAGER 7839 1981-5-1 2850.00 30
7782 CLARK MANAGER 7839 1981-6-9 2450.00 10
7788 SCOTT ANALYST 7566 1987-4-19 3000.00 20
7839 KING PRESIDENT 1981-11-17 5000.00 10
7844 TURNER SALESMAN 7698 1981-9-8 1500.00 0.00 30
7876 ADAMS CLERK 7788 1987-5-23 1100.00 20
7900 JAMES CLERK 7698 1981-12-3 950.00 30
7902 FORD ANALYST 7566 1981-12-3 3000.00 20
7934 MILLER CLERK 7782 1982-1-23 1300.00 10
create external table if not exists dept(
deptno int,
dname string,
loc int
)
row format delimited fields terminated by '\t';
create external table if not exists emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)
row format delimited fields terminated by '\t';
load data local inpath '/opt/datafiles/dept.txt' into table dept;
load data local inpath '/opt/datafiles/emp.txt' into table emp;
执行计划
查看语句的执行计划
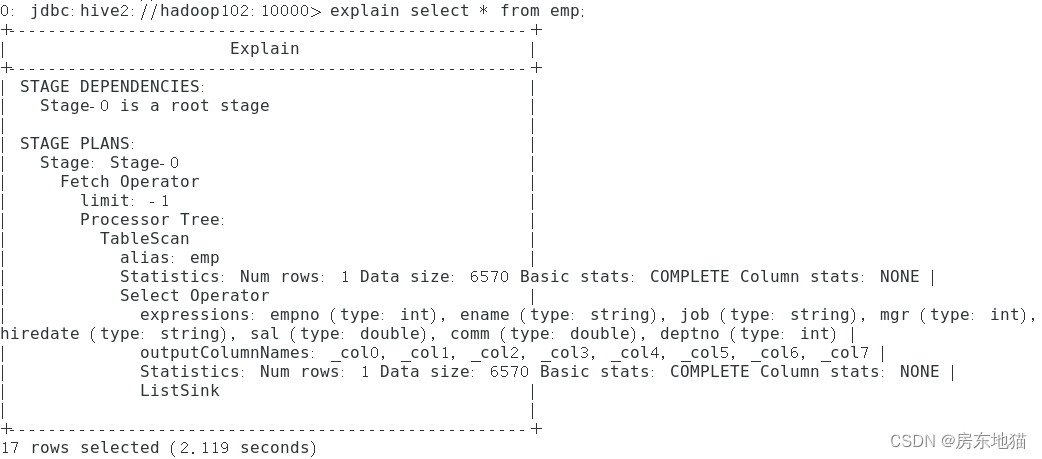
没有生成MR任务的
explain select * from emp;
有生成MR任务的
explain select deptno,avg(sal) avg_sal from emp group by deptno;

查看详细执行计划
explain extended select * from emp;
explain extended select deptno,avg(sal) avg_sal from emp group by deptno;
Fetch抓取
Fetch抓取是指,Hive中对某些情况的查询可以不必使用MapReduce计算。例如:SELECT * FROM employees;在这种情况下,Hive可以简单地读取employee对应的存储目录下的文件,然后输出查询结果到控制台。
在hive-default.xml.template文件中hive.fetch.task.conversion默认是more,老版本hive默认是minimal,该属性修改为more以后,在全局查找、字段查找、limit查找等都不走mapreduce。
应用
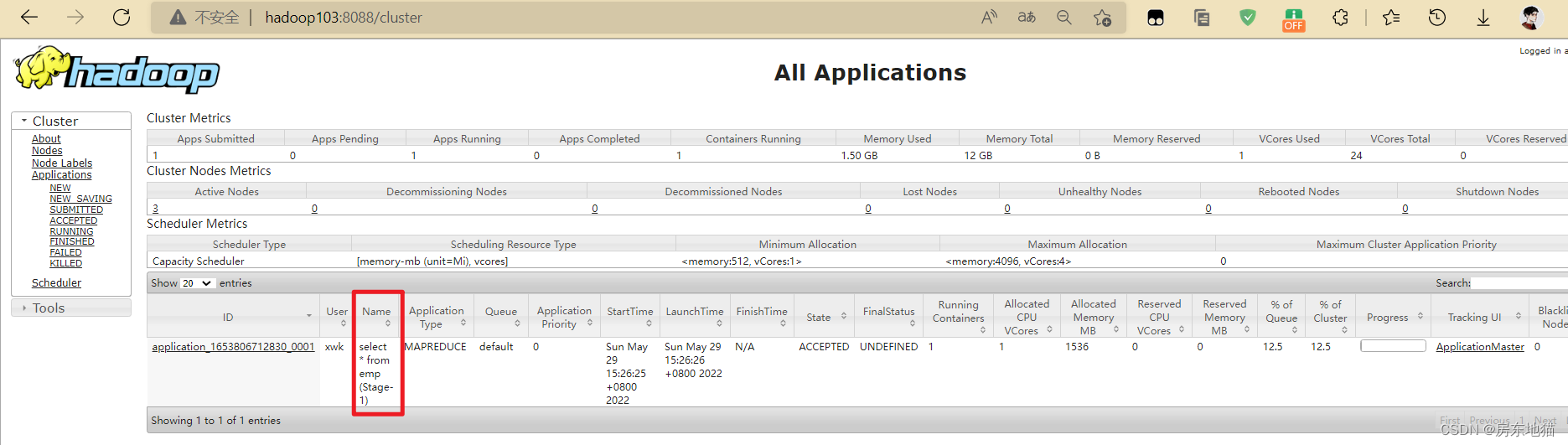
(1)把hive.fetch.task.conversion设置成none,然后执行查询语句,都会执行mapreduce程序。
set hive.fetch.task.conversion=none;
select * from emp;

select ename from emp;
select ename from emp limit 3;
都会执行mapreduce程序。
(2)把hive.fetch.task.conversion设置成more,然后执行查询语句,如下查询方式都不会执行mapreduce程序。
set hive.fetch.task.conversion=more;
select * from emp;
select ename from emp;
select ename from emp limit 3;
都不会执行mapreduce程序。
本地模式
大多数的Hadoop Job是需要Hadoop提供的完整的可扩展性来处理大数据集的。不过,有时Hive的输入数据量是非常小的。在这种情况下,为查询触发执行任务消耗的时间可能会比实际job的执行时间要多的多。对于大多数这种情况,Hive可以通过本地模式在单台机器上处理所有的任务。对于小数据集,执行时间可以明显被缩短。
用户可以通过设置hive.exec.mode.local.auto的值为true,来让Hive在适当的时候自动启动这个优化。
(1)开启本地模式,并执行查询语句
set hive.exec.mode.local.auto=true;
select * from emp cluster by deptno;
14 rows selected (8.13 seconds)
(2)关闭本地模式,并执行查询语句
set hive.exec.mode.local.auto=false;
select * from emp cluster by deptno;
14 rows selected (38.737 seconds)
可以看到耗时差距是很明显的
表的优化
(待完善)