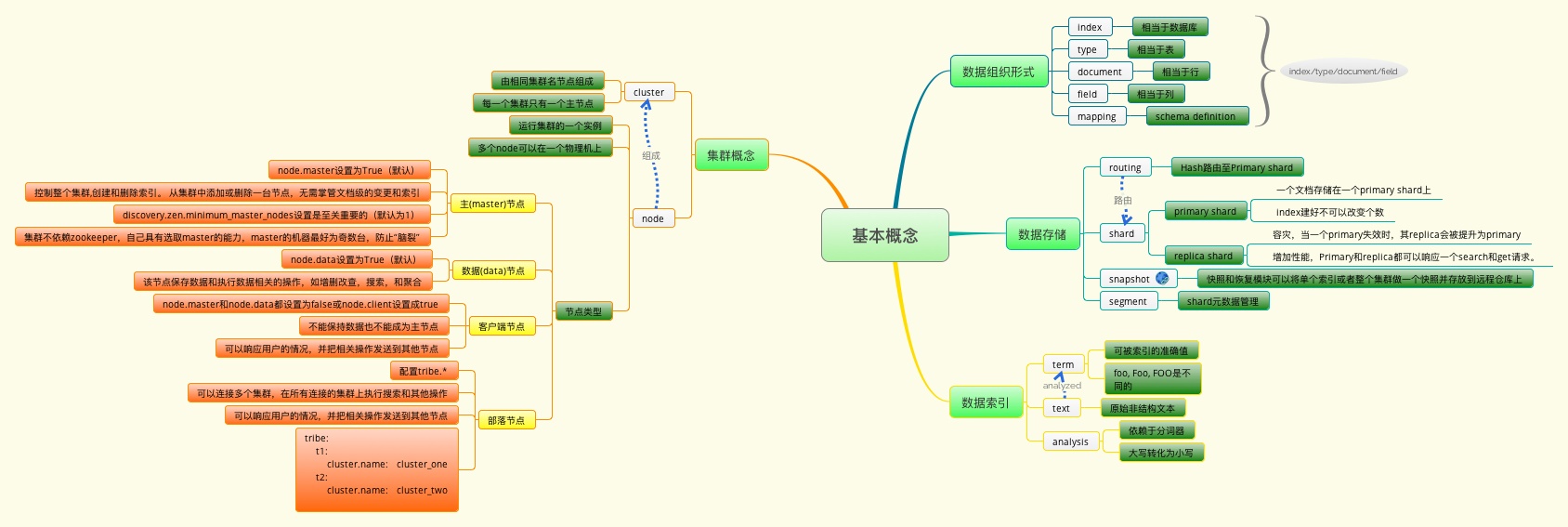
集群,一个ES集群由一个或多个节点(Node)组成,每个集群都有一个cluster name作为标识
------------------------------------------------
【node】
节点,一个ES实例就是一个node,一个机器可以有多个实例,所以并不能说一台机器就是一个node,大多数情况下每个node运行在一个独立的环境或虚拟机上。
------------------------------------------------
【index】
索引,即一系列documents的集合
------------------------------------------------
【shard】
1.分片,ES是分布式搜索引擎,每个索引有一个或多个分片,索引的数据被分配到各个分片上,相当于一桶水用了N个杯子装
2.分片有助于横向扩展,N个分片会被尽可能平均地(rebalance)分配在不同的节点上(例如你有2个节点,4个主分片(不考虑备份),那么每个节点会分到2个分片,后来你增加了2个节点,那么你这4个节点上都会有1个分片,这个过程叫relocation,ES感知后自动完成)
3.分片是独立的,对于一个Search Request的行为,每个分片都会执行这个Request.另外
4.每个分片都是一个Lucene Index,所以一个分片只能存放 Integer.MAX_VALUE - 128 = 2,147,483,519 个docs。
------------------------------------------------【replica】
1.复制,可以理解为备份分片,相应地有primary shard(主分片)
2.主分片和备分片不会出现在同一个节点上(防止单点故障),默认情况下一个索引创建5个分片一个备份(即5primary+5replica=10个分片)
3.如果你只有一个节点,那么5个replica都无法分配(unassigned),此时cluster status会变成Yellow。replica的作用主要包括:
ES集群的三种状态:
1)Green: 所有主分片和备份分片都准备就绪,分配成功, 即使有一台机器挂了(假设一台机器实例),数据都不会丢失,但是会变成yellow状态.
2)Yellow: 所有主分片准备就绪,但至少一个主分片(假设是A)对应的备份分片没有就绪,此时集群处于告警状态,意味着高可用和容灾能力下降.如果刚好A所在的机器挂了,并且你只设置了一个备份(已处于未继续状态), 那么A的数据就会丢失(查询不完整),此时集群处于Red状态.
3)Red:至少有一个主分片没有就绪(直接原因是找不到对应的备份分片成为新的主分片),此时查询的结果会出现数据丢失(不完整).
1.容灾:primary分片丢失,replica分片就会被顶上去成为新的主分片,同时根据这个新的主分片创建新的replica,集群数据安然无恙
2.提高查询性能:replica和primary分片的数据是相同的,所以对于一个query既可以查主分片也可以查备分片,在合适的范围内多个replica性能会更优(但要考虑资源占用也会提升[cpu/disk/heap]),另外index request只能发生在主分片上,replica不能执行index request。
3.对于一个索引,除非重建索引否则不能调整分片的数目(主分片数, number_of_shards),但可以随时调整replica数(number_of_replicas)。
集群,一个ES集群由一个或多个节点(Node)组成,每个集群都有一个cluster name作为标识
------------------------------------------------
【node】
节点,一个ES实例就是一个node,一个机器可以有多个实例,所以并不能说一台机器就是一个node,大多数情况下每个node运行在一个独立的环境或虚拟机上。
------------------------------------------------
【index】
索引,即一系列documents的集合
------------------------------------------------
【shard】
1.分片,ES是分布式搜索引擎,每个索引有一个或多个分片,索引的数据被分配到各个分片上,相当于一桶水用了N个杯子装
2.分片有助于横向扩展,N个分片会被尽可能平均地(rebalance)分配在不同的节点上(例如你有2个节点,4个主分片(不考虑备份),那么每个节点会分到2个分片,后来你增加了2个节点,那么你这4个节点上都会有1个分片,这个过程叫relocation,ES感知后自动完成)
3.分片是独立的,对于一个Search Request的行为,每个分片都会执行这个Request.另外
4.每个分片都是一个Lucene Index,所以一个分片只能存放 Integer.MAX_VALUE - 128 = 2,147,483,519 个docs。
------------------------------------------------【replica】
1.复制,可以理解为备份分片,相应地有primary shard(主分片)
2.主分片和备分片不会出现在同一个节点上(防止单点故障),默认情况下一个索引创建5个分片一个备份(即5primary+5replica=10个分片)
3.如果你只有一个节点,那么5个replica都无法分配(unassigned),此时cluster status会变成Yellow。replica的作用主要包括:
ES集群的三种状态:
1)Green: 所有主分片和备份分片都准备就绪,分配成功, 即使有一台机器挂了(假设一台机器实例),数据都不会丢失,但是会变成yellow状态.
2)Yellow: 所有主分片准备就绪,但至少一个主分片(假设是A)对应的备份分片没有就绪,此时集群处于告警状态,意味着高可用和容灾能力下降.如果刚好A所在的机器挂了,并且你只设置了一个备份(已处于未继续状态), 那么A的数据就会丢失(查询不完整),此时集群处于Red状态.
3)Red:至少有一个主分片没有就绪(直接原因是找不到对应的备份分片成为新的主分片),此时查询的结果会出现数据丢失(不完整).
1.容灾:primary分片丢失,replica分片就会被顶上去成为新的主分片,同时根据这个新的主分片创建新的replica,集群数据安然无恙
2.提高查询性能:replica和primary分片的数据是相同的,所以对于一个query既可以查主分片也可以查备分片,在合适的范围内多个replica性能会更优(但要考虑资源占用也会提升[cpu/disk/heap]),另外index request只能发生在主分片上,replica不能执行index request。
3.对于一个索引,除非重建索引否则不能调整分片的数目(主分片数, number_of_shards),但可以随时调整replica数(number_of_replicas)。