相信大家对布隆过滤器有所了解,下面我们对布隆过滤器进行通俗讲解,加深理解。
【背景:了解redis缓存穿透】
我们学过redis都知道缓存穿透,用户可能进行了一次条件错误的查询,这时候redis是不存在的,就去数据库找了。由于这是一次错误的条件查询,数据库当然也不会存在,则返回给用户一个空。
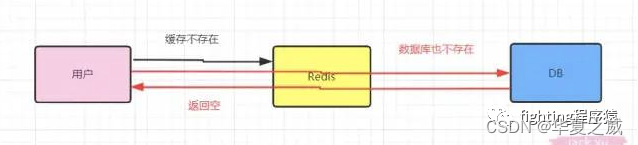
现在redis变成了形同虚设,每次还是去数据库查找了,这个就叫做缓存穿透,相当于redis不存在了,被击穿了。
对于这种情况可以这样解决,我们在redis缓存一个空字符串或者特殊字符串,比如&&,当我们去redis中查询的时候,当取到的值是空或者&&,我们就知道这个值在数据库中是没有的,就不会在去数据库中查询。
【为什么需要布隆过滤器】
对于上面例子,如果是查询错误的key是同一个可以解决,但是每次查询的key值不一样的呢?
比如我们的数据库用户id是1,2,3,4依次递增,此时别人要攻击你,故意拿-1,-3,-5这种乱七八糟的key来查询,redis和数据库这种值都是不存在的,这时候还是出现redis缓存穿透情况,数据库的压力是相当大,比上面这种情况可怕的多,怎么办呢?这时候我们今天的主角布隆过滤器就登场了。
我们总结下上面遗留的问题:我们怎么在应用访问redis和数据库之前先筛选过滤一遍数据,将不存在的元素筛选出来?
【解决问题思路】
换个说法,上面问题的本质就是:如何在海量元素中(例如 10 亿无序、不定长、不重复)快速判断一个元素是否存在?
好,我们最简单的想法就是把这么多数据放到数据结构里去,比如List、Map、Tree,一搜不就出来了吗,比如map.get()。
我们假设一个元素1个字节的字段,10亿的数据大概需要 900G 的内存空间,这个对于普通的服务器来说是承受不了的,我们肯定是要用一种好的方法,巧妙的方法来解决,这里引入一种节省空间的数据结构,位图,他是一个有序的数组,只有两个值,0 和 1。0代表不存在,1代表存在。

有了这个位图,现在我们还需要一个映射关系,将所有的数据映射到位图上面,映射后这个位图上有0也有1,1即存在某个元素。那就要用到哈希函数,用哈希函数有两个好处,第一是哈希函数无论输入值的长度是多少,得到的输出值长度是固定的,第二是他的分布是均匀的。
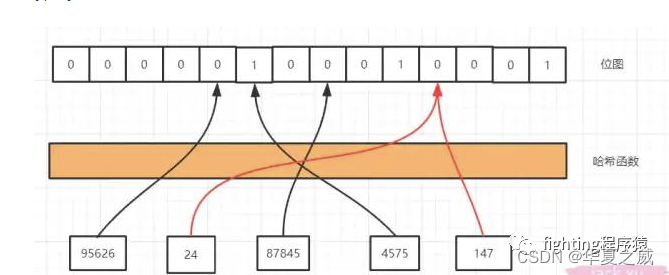
我们通过哈希函数计算以后就可以到相应的位置去找是否存在了,我们看红色的线,24和147经过哈希函数得到的哈希值是一样的,我们把这种情况叫做哈希冲突或者哈希碰撞。
哈希碰撞是不可避免的,我们能做的就是降低哈希碰撞的概率,第一种是可以扩大维数组的长度或者说位图容量,因为我们的函数是分布均匀的,所以位图容量越大,在同一个位置发生哈希碰撞的概率就越小。但是越大的位图容量,意味着越多的内存消耗。
第二种方式就是经过多几个哈希函数的计算,你想啊,24和147现在经过一次计算就碰撞了,那我经过5次,10次,100次计算还能碰撞的话那真的是缘分了,你们可以在一起了,但也不是越多次哈希函数计算越好,因为这样很快就会填满位图,而且计算也是需要消耗时间,所以我们需要在时间和空间上寻求一个平衡。
【布隆过滤器原理】
在 1970 年的时候,有一个叫做布隆的前辈对于判断海量元素中元素是否存在的问题进行了研究,也就是到底需要多大的位图容量和多少个哈希函数,它发表了一篇论文,提出的这个容器就叫做布隆过滤器。
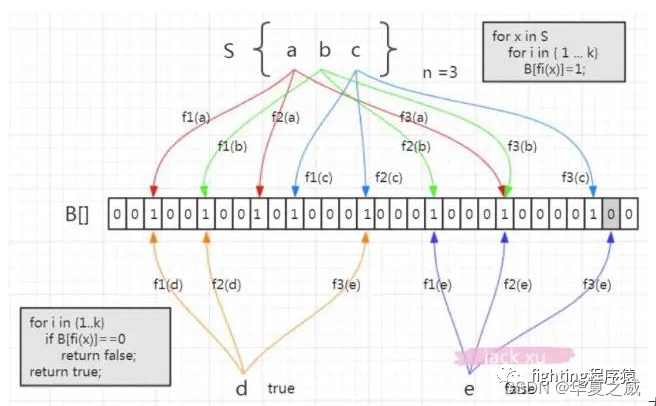
我们看集合里面3个元素,现在我们要存了,比如说a,经过f1(a),f2(a),f3(a)经过三个哈希函数的计算,在相应的位置上存入1,元素b,c也是通过这三个函数计算放入相应的位置。
当取的时候,元素a通过f1(a)函数计算,发现这个位置上是1,没问题,第二个位置也是1,第三个位置上也是 1,这时候我们说这个a在布隆过滤器中是存在的。
同理我们看下面的这个d,通过三次计算发现得到的结果也都是1,那么我们能说d在布隆过滤器中是存在的吗,显然是不行的,我们仔细看d得到的三个1其实是f1(a),f1(b),f2©存进去的,并不是d自己存进去的,这个还是哈希碰撞导致的,我们把这种本来不存在布隆过滤器中的元素误判为存在的情况叫做假阳性。
我们再来看另一个元素,e 元素。我们要判断它在容器里面是否存在,一样地要用这三个函数去计算。第一个位置是 1,第二个位置是 1,第三个位置是 0。那么e元素能不能判断是否在布隆过滤器中?答案是肯定的,e一定不存在。你想啊,如果e存在的话,他存进去的时候这三个位置都置为1,现在查出来有一个位置是0,证明他没存进去。
由上面我们得出两个重要的结论:
从容器的角度来说:
(1)、如果布隆过滤器判断元素在集合中存在,不一定存在
(2)、如果布隆过滤器判断不存在,一定不存在
从元素的角度来说:
(1)、如果元素实际存在,布隆过滤器一定判断存在
(2)、如果元素实际不存在,布隆过滤器可能判断存在
【布隆过滤器demo】
下面通过代码方式演示下布隆过滤器:
package com.jd.demo.test;
import java.util.Arrays;
import java.util.BitSet;
import java.util.concurrent.atomic.AtomicBoolean;
public class MyBloomFilter {
//你的布隆过滤器容量
private static final int DEFAULT_SIZE = 2 << 28;
//bit数组,用来存放结果
private static BitSet bitSet = new BitSet(DEFAULT_SIZE);
//后面hash函数会用到,用来生成不同的hash值,可随意设置
private static final int[] ints = {
1, 6, 16, 38, 58, 68};
//add方法,计算出key的hash值,并将对应下标置为true
public void add(Object key) {
Arrays.stream(ints).forEach(i -> bitSet.set(hash(key, i)));
}
//判断key是否存在,true不一定说明key存在,但是false一定说明不存在
public boolean isContain(Object key) {
AtomicBoolean result = new AtomicBoolean(true);
Arrays.stream(ints).forEach(i -> result.set(bitSet.get(hash(key, i))));
return result.get();
}
//hash函数,借鉴了hashmap的扰动算法
private int hash(Object key, int i) {
int h;
return key == null ? 0 : (i * (DEFAULT_SIZE - 1) & ((h = key.hashCode()) ^ (h >>> 16)));
}
}
调用返回结果如下:
public static void main(String[] args) {
MyNewBloomFilter myNewBloomFilter = new MyNewBloomFilter();
myNewBloomFilter.add("张学友");
myNewBloomFilter.add("郭德纲");
myNewBloomFilter.add(666);
System.out.println(myNewBloomFilter.isContain("张学友"));//true
System.out.println(myNewBloomFilter.isContain("张学友 "));//false
System.out.println(myNewBloomFilter.isContain("张学友1"));//false
System.out.println(myNewBloomFilter.isContain("郭德纲"));//true
System.out.println(myNewBloomFilter.isContain(666));//true
System.out.println(myNewBloomFilter.isContain(888));//false
}