monai——transform变换
本文对于已有数据进行monai中transform的使用,若无数据,可以下载医学全能十项的数据来用
1.数据准备
上文提到的加载数据,可以加载自己的,也可用monai下载方法进行下载,若有自己数据,忽略。
resource = "https://msd-for-monai.s3-us-west-2.amazonaws.com/Task09_Spleen.tar"
md5 = "410d4a301da4e5b2f6f86ec3ddba524e"
# root_dir: 存储地址
root_dir = '.data/'
compressed_file = os.path.join(root_dir, "Task09_Spleen.tar")
data_dir = os.path.join(root_dir, "Task09_Spleen")
if not os.path.exists(data_dir):
download_and_extract(resource, compressed_file, root_dir, md5)
有数据后,先把image和label的地址加载到data_dict中,便于后续做处理。
import glob
import os
data_dir = '/home/qiaoqiang/nnUNetFrame/DATASET/nnUNet_raw/nnUNet_raw_data/Task012_Naoxue_t2/'
train_images = sorted(glob.glob(os.path.join(data_dir,"imagesTr","*.nii.gz")))
train_labels = sorted(glob.glob(os.path.join(data_dir,"labelsTr","*.nii.gz")))
data_dict = [
{'image': image, 'label': label}
for image, label in zip(train_images, train_labels)]
train_data_dicts ,val_data_dicts = data_dict[:-9] , data_dict[-9:]
print(train_data_dicts[0])
{'image': '/home/qiaoqiang/nnUNetFrame/DATASET/nnUNet_raw/nnUNet_raw_data/Task012_Naoxue_t2/imagesTr/002chenxiaojiao_t2_0000.nii.gz',
'label': '/home/qiaoqiang/nnUNetFrame/DATASET/nnUNet_raw/nnUNet_raw_data/Task012_Naoxue_t2/labelsTr/002chenxiaojiao_t2.nii.gz'}
2.加载NIfTI 格式的文件【 LoadImage/ LoadImaged】
例如,LoadImage类是底层Nibabel映像加载器的简单可调用包装器。在使用一些必要的系统参数构造加载程序之后,使用NIfTI文件名调用加载程序实例将返回图像数据数组以及元数据,例如仿射信息和体素大小。简单说就是,如果是nii.gz格式的文件,调用LoadImage,它会自动调用Nibabel来打开数据。在python中,nii.gz一般都是通过Nibabel来打开的。
LoadImage/ LoadImaged在使用时会有细小的差别,通过举例来说明。
如果变换不在Compose中组合用,需要实例化对象。
from monai.transforms import LoadImage
import numpy as np
loader = LoadImage(dtype=np.float32) # 实例化
image, metadata = loader(train_data_dicts[0]["image"]) # 把image的地址传给loader
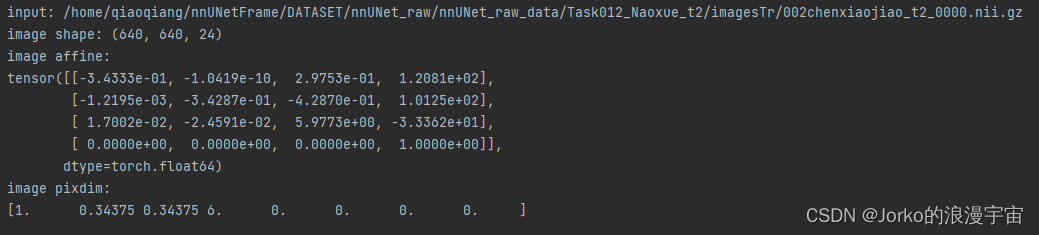
print(f"input: {train_data_dicts[0]['image']}")
print(f"image shape: {image.shape}")
print(f"image affine:\n{metadata['affine']}")
print(f"image pixdim:\n{metadata['pixdim']}")
2.1 LoadImage
LoadImage会加载元数据,那么元数据中有哪些信息呢?
使用metadata.keys()来查看其中的内容,内容如下,看不清图看文字,其中信息pixdim是体素大小,还有维度信息dim_info、空间形状spatial_shape、图像文件路径filename_or_obj
dict_keys(['sizeof_hdr', 'extents', 'session_error', 'dim_info', 'dim', 'intent_p1', 'intent_p2', 'intent_p3', 'intent_code', 'datatype', 'bitpix', 'slice_start', 'pixdim', 'vox_offset', 'scl_slope', 'scl_inter', 'slice_end', 'slice_code', 'xyzt_units', 'cal_max', 'cal_min', 'slice_duration', 'toffset', 'glmax', 'glmin', 'qform_code', 'sform_code', 'quatern_b', 'quatern_c', 'quatern_d', 'qoffset_x', 'qoffset_y', 'qoffset_z', 'srow_x', 'srow_y', 'srow_z', affine, original_affine, 'as_closest_canonical', spatial_shape, space, original_channel_dim, 'filename_or_obj'])

如果不需要metadata的话,可以这样加载
loader = LoadImage(image_only=True, dtype=np.float32) # 表示只需要图像值
image = loader(train_data_dicts[0]["image"])
2.2 LoadImaged
需要注意在字典中加载/处理数据,需要指定作用对象,参数”keys“是你在data_dicts中设置的keys。表示要对image做变换还是label做变换。如果都做,就都写。比如
keys=[“image”, “label”], keys = ‘image’, keys = ‘label’
loader = LoadImaged(keys=("image", "label"))
data_dict = loader(train_data_dicts[0])
print(f"input:, {train_data_dicts[0]}")
print(f"image shape: {data_dict['image'].shape}")
print(f"label shape: {data_dict['label'].shape}")
print(f"image pixdim:\n{data_dict['image_meta_dict']['pixdim']}")
3.添加通道 [EnsureChannelFirstd]
使用monai的模型时,默认是通道优先的格式。要求数据尺寸为:[num_channels, spatial_dim_1, spatial_dim_2, … ,spatial_dim_n]。如上,我们的数据尺寸为[640, 640, 24], 需要在前面一维通道。变成[1,640, 640, 24],新版本使用EnsureChannelFirstd代替之前的AddChanneld,可以添加维度,并且将通道数置于首位。
from monai.transforms import EnsureChannelFirstd
add_channel_first = EnsureChannelFirstd(keys=("image", "label"))
data_dict_addc = add_channel_first(data_dict)
print(f"AddChanneld after image shape: {data_dict_addc['image'].shape}")
输出结果
AddChanneld after image shape: (1, 640, 640, 24)
需要注意的是:改变换应该用在加载数据LoadImaged后面。
4.强度变换 [NormalizeIntensityd / ScaleIntensityRanged]
这两种都是对图像值强度进行变换的,像CT和MRI的值都是从-1000—+3000多的不等,通常需要进行归一化,查看目前第一个数据的强度值范围
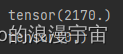
print(data_dict_addc['image'].max())
print(data_dict_addc['image'].min())
可以发现是从0-2170的,所以需要进行强度归一化
4.1 NormalizeIntensityd
因为一般用基于字典的数据处理,但我们先看基于数组的,他的介绍比较详细
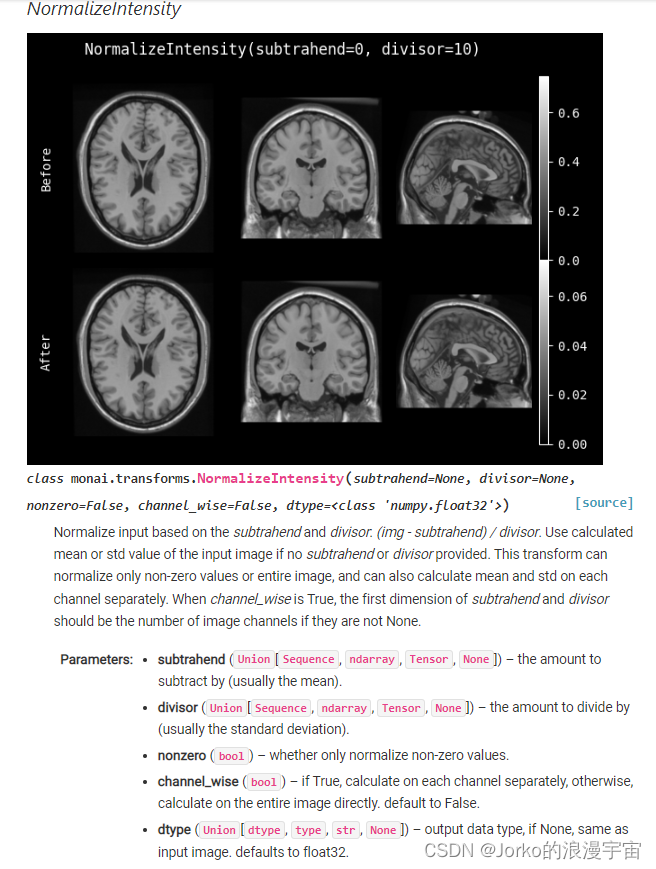
该函数使用的归一化方法是 img-subtrahend/divisor
参 数 介 绍
subtrahend:被减数, 可以自己指定,默认为整个图像的均值。
divisor: 除数, 可以自己指定,默认为整个图像的方差。
nonzero: 布尔值。等于True,表示只对图像的非0区域做归一化。
channel_wise: 布尔值。为True, 表示在每个通道上进行计算均值和方差,若为False,则在整个图像上计算均值和方差,当不指定subtrahend和divisor,默认为False
接下来是 NormalizeIntensityd,对于字典中图像和标签都可以进行处理,但是因为标签就是1 2 3 这些数,不需要处理,仅对图像进行处理即可
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZB4q74kD-1667309959679)(C:\Users\qiaoqiang\AppData\Roaming\marktext\images\2022-11-01-09-43-28-image.png)]](https://img-blog.csdnimg.cn/e66b9b148a104467ab6c9c6eab5474f5.png)
from monai.transforms import NormalizeIntensityd
import numpy as np
norm = NormalizeIntensityd(keys='image', nonzero=False, dtype=np.float32)
data_dict_addc_norm = norm(data_dict_addc)
print(data_dict_addc_norm['image'].max())
print(data_dict_addc_norm['image'].min())
结果为 ![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SeeGFhbg-1667309959679)(C:\Users\qiaoqiang\AppData\Roaming\marktext\images\2022-11-01-10-01-23-image.png)]](https://img-blog.csdnimg.cn/acaf2f732dff476aa109fc1120c5f147.png)
4.2 ScaleIntensityRanged

ScaleIntensityRanged和NormalizeIntensityd不同之处在于, ScaleIntensityRanged可以指定把哪些范围值缩放到那个区间。比如对于脾脏分割中感兴趣的CT值范围(假设在-300到300之间),而骨头等高强度信号(大于2000),如果直接归一化后,脾脏内部的值范围就很小,差异也就不明显,我们就可以仅把[-300,300]强度归一化到[0,1],而此外的强度值都变为0,很多论文都是这样处理,所以可以借鉴。
参 数 介 绍
a_min:float,强度原始范围最小值。可以理解为需要被归一化的最小值,如我们这个例子中的-300(需要写成小数,-300.0)
a_max: float, 强度原始范围最大值。可以理解为需要被归一化的最大值,如我们这个例子中的300(需要写成小数,300.0)
b_min: float, 强度目标范围最小值。可以理解为归一化后的最小值,通常设置为0.0
b_max: float, 强度目标范围最大值。可以理解为归一化后的最大值,通常设置为1.0
clip: 布尔值。设置为True, 才会把[-300,+300]之外的值都设置为0.通常为True
示例演示:
scale = ScaleIntensityRanged(keys='image', a_min=0.0, a_max=600.0, b_min=0.0, b_max=1.0, clip=True)
# 由于上面我们把datac_dict归一化了,因此,我们要重新制造一个datac_dict
data_dict = loader(train_data_dicts[2])
datac_dict = add_channel(data_dict)
data_scale = scale(datac_dict)
print('original max value', datac_dict['image'].max())
print('original min value', datac_dict['image'].min())
print('target max value', data_scale['image'].max())
print('target min value', data_scale['image'].min())

变换后图像为

5.空间变换 [Rotate90d / Resized]
5.1 RandRotate90d
输入数组在由spatial_axes指定的平面中旋转90度

参 数 介 绍
prob: float, 旋转的概率,默认为0.1, 也就是10%的概率被旋转
max_k: int, 旋转90度的次数,默认为3
spatial_axes: 元组(int,int)。指定围绕哪个面旋转,默认为(0,1),即按前两个轴旋转。
from monai.transforms import RandRotate90d
rotate = RandRotate90d(keys=['image', 'label'], prob=0.5, max_k=1, spatial_axes=(2,1))
data_rotate = rotate(data_scale)
print(data_rotate['image'].shape)
print(data_rotate['label'].shape)
结果将 图像的y维度和z维度换了一下,结果如下:
(1, 512, 24, 512) (1, 512, 24, 512)
在分割任务中,如果使用旋转,尤其是随机旋转的时候一定要注意,image和label应当一同旋转,并且旋转方式要一模一样。
5.2 Resized

spatial_size: 序列[int, int,], 期大小调整操作之后的空间尺寸的形状
size_mode: 应该是"all "或"longest “,如果” all “,将使用spatial_size对所有的空间维度处理,如果” longest ",重新缩放图像,使只有最长的边等于指定的spatial_size,在这种情况下,spatial_size必须是一个int数,保持初始图像的纵横比。
mode: resize使用的插值方式,默认为”area“可以选择"nearest", "linear", "bilinear", "bicubic", "trilinear"
from monai.transforms import Resized
resize = Resized(keys=['image', 'label'], spatial_size=(256, 256, 256))
data_resize = resize(data_rotate)
print(data_resize['image'].shape)
import matplotlib.pyplot as plt
plt.figure("image", (18, 6))
plt.subplot(1, 2, 1)
plt.title("image")
plt.imshow(data_resize['image'][0, :, :, 100].detach().cpu(), cmap="gray")
plt.subplot(1, 2, 2)
plt.title("label")
plt.imshow(data_resize['label'][0, :, :,100].detach().cpu())
plt.show()
输出结果为:
(1, 256, 256, 256)

6.裁剪
【SpatialCropd, CenterSpatialCropd, CropForegroundd, RandCropByPosNegLabeld】
对于CT或者MRI图像来讲,图像是非常大的,又是一个三维图像,不可能全部输入网络中训练。要么把图像直接Resize到固定的尺寸,要么就是裁剪图像。monai提供了非常多的裁剪模式,包括中心裁剪,前景裁剪和随机裁剪等等,同时图像不够大的话,也可以进行填充。本文介绍几种经常用到的裁剪方式。
注意事项,这些裁剪方式都要求数据格式为通道优先格式(必须有通道维度),也就是说要放在EnsureChannelFirstd后面使用
6.1 SpatialCropd

这个函数是根据提供的空间中心和大小裁剪图像,或者,如果未提供中心和大小,则必须提供ROI的开始和结束坐标来裁剪图像。
参 数 介 绍
roi_center: int, ROI的中心体素坐标,如果是二维图像,则坐标是(x, y), 如果是三维,则坐标是(x, y, z)
roi_size: int, ROI的大小。很好理解,有了中心,再加上大小就可以裁减ROI了
roi_start / roi_end, int, 如果不提供上述两个参数,还可以自己指定ROI的开始结束坐标
from monai.transforms import LoadImaged,EnsureChannelFirstd,SpatialCropD
import numpy as np
loader = LoadImaged(keys=["image", "label"], dtype=np.float32)
add_channel = EnsureChannelFirstd(keys=["image", "label"])
# 重新加载一个图像
data_dict = loader(data_dicts[4])
print(data_dict['image'].shape)
datac_dict = add_channel(data_dict) # (1, 512, 512, 23)
crop0 = SpatialCropD(keys=["image", "label"], roi_center=(256, 256, 11), roi_size=(256, 256, 11))
# # 中心坐标为图像的中点(256,256,11), 大小也是(256,256,11)
#
data_crop = crop0(datac_dict)
print(data_crop['image'].shape) # (1, 256, 256, 11)
从中心进行裁剪,将原图的23个z切片裁剪为11个,周围的12个裁没了,两边目前只剩11个,原图的前六张和后六张被裁没了,原图数组第6个(实际第七个)对应当前数组第0个(实际第1个),因为下标从0开始,所以原图的第12张切片,对应目前的第6张;原图的第13张,对于目前的第7张切片,如图展示了裁剪后的第7张图像

按中心裁剪比较复杂,而对于要得到边缘部分的数据,不太方便,可以手动输入起始点坐标
crop1 = SpatialCropD(keys=["image", "label"], roi_start=(128,128,20), roi_end=(480,480,23))
data_crop = crop1(datac_dict)
print(data_crop['image'].shape) # (1, 256, 256, 20)
image, label = datac_dict["image"][0], datac_dict["label"][0]
imagecrop, labelcrop = data_crop["image"][0], data_crop["label"][0]
plt.figure("visualize", (8, 8))
plt.subplot(2, 2, 1)
plt.title("image")
plt.imshow(image[:, :, 20], cmap="gray")
plt.subplot(2, 2, 2)
plt.title("label")
plt.imshow(label[:, :, 20])
plt.subplot(2, 2, 3)
plt.title("croped image")
plt.imshow(imagecrop[:, :, 0], cmap="gray")
plt.subplot(2, 2, 4)
plt.title("croped label")
plt.imshow(labelcrop[:, :, 0])
plt.show()

其实后面的各种裁剪都是会在内部调用SpatialCropd的,只是坐标的获取方式不一样。
6.2 CenterSpatialCropd

这种裁剪方式,只需要提到ROI大小,会自动找到中心给你裁剪,不需要像SpatialCropd中手动提供中心坐标。
from monai.transforms import CenterSpatialCropd
crop2 = CenterSpatialCropd(keys=['image', 'label'], roi_size=(256,256,20))
data_crop = crop2(datac_dict)
print(data_crop['image'].shape) # (1, 256, 256, 20)
6.3 CropForegroundd

使用边框裁剪图像。通过在使用select_fn选择前景来生成边界框。在边框的每个空间尺寸中添加边距。如果整个医学图像中的有效部分很小,通常用于帮助训练和验证。
简单讲,可以自己定义裁剪的方式,比如按图像值>0的裁剪,按 label 中>0的裁剪等等。反正找出图像中有效的部分用于训练。
注意:CropForegroundd和CropForeground会有些区别,CropForeground不会有label,所以不可能按label的值去选择图像。所以分割的话,建议用字典形式,就可以裁剪出有阳性值的部分。
参数量比较多,举出常见的几个参数
source_key: str, 按image还是label裁剪图像.这里的key, 就是keys=[‘image’, ‘label’]中的key。
select_fn: 按照什么原则选择前景。默认为选择大于0的值作为前景。比如,如果source_key=“image”, 则选择的是image>0的部分作为前景
channel_indices: 选择特定的通道
margin: int, 边缘填充的个数。通常用原来的值进行填充。默认为0,则不填充。
start_coord_key/end_coord_key:str, 应该是记录获取到的前景空间边界框的起始/结束坐标值
举个例子,直接裁剪得到图片中大于等于1区域的部分
from monai.transforms import CropForeground
import numpy as np
image = np.array(
[[[0, 0, 0, 0, 0],
[0, 1, 2, 1, 0],
[0, 1, 3, 2, 0],
[0, 1, 2, 1, 0],
[0, 0, 0, 0, 0]]]) # 1x5x5, single channel 5x5 image
cropper = CropForeground(select_fn=lambda x: x >= 1, margin=0, return_coords=False)
print(cropper(image))

我们可以使用margin来对结果进行padding,进行边缘扩充

对真实图像进行操作,对图像大于300像素的值进行裁剪
from monai.transforms import CropForegroundd
crop3 = CropForegroundd(keys=['image', 'label'], source_key='image', select_fn=lambda x: x > 300, margin=2)
# 裁剪原则为: image中大于300的像素点,边缘扩充2个像素点
data_crop = crop3(datac_dict)
print(data_crop['image'].shape) # (1, 369, 422, 23)

观察到这种方法,边缘还是有像素值为0的,没有裁剪掉,我们可以裁剪label中大于0的像素点,并扩充2个像素点
crop3 = CropForegroundd(keys=['image', 'label'], source_key='label', select_fn=lambda x: x > 0, margin=2)
# 裁剪原则为: label中大于0的像素点,边缘扩充2个像素点
data_crop = crop3(datac_dict)
print(data_crop['image'].shape) # (1, 123, 116, 11)
结果很明显,将标签ROI部分变得很大,可以看出,使用了label来裁剪图像,可以精准定位目标。

6.4 RandCropByPosNegLabeld
按阴性阳性比裁剪

如果你一幅图像很大,需要裁剪成多个子图,那这个方法就再合适不过了。像是腹部CT这种很大的三维图像,通常都会使用这个方法,按照阴性阳性比裁剪成4个子图。
参 数 介 绍
label_key: str, 又是一个需要提供key的参数。代表label的键(我们的例子中就是"label"),用于查找前景和背景
spatial_size: [int, int], ROI的大小
pos: float, 与neg一起用于计算将前景体素而不是背景体素选为中心的概率的比率. 选中阳性值的概率为:pos / (pos + neg)
neg: float, 与pos同理。
num_samples: int, 返回多少个子图
image_key: str, 如果提供了image key, 就会使用label==0, 并且image>image_threshold (阈值)的部分作为阴性样本,所以裁剪中心将仅存在于有效图像区域上。
image_threshold: float, 如果使用了image_key, 则提供阈值
fd_indices_key: str, 根据提供的前景索引来裁剪图像,将忽略image_key和 image_threshold
bg_indices_key:str, 需要同fd_indices_key一起提供。典型的是通过FgBgToIndicesd获取索引并缓存结果。
从原图像中裁剪4个大小为(256,256,10)的子图,并且阳性比率为1/2
crop4 = RandCropByPosNegLabeld(keys=["image", "label"], label_key='label', spatial_size=(256, 256, 10),
pos=1.0, neg=1.0, num_samples=4, image_key='image', image_threshold=200.0)
data_crop = crop4(datac_dict)
print(f'there are {len(data_crop)} croped images')
print('the croped image shape is ', {data_crop[0]['image'].shape}) # 这里返回了4幅图像,所以需要索引

从图中可以看出,通过label来裁剪图像,每幅图像的差异不是很大。想要阳性更多,加大阳性的比例,想要阴性更多,加大阴性的比例,其中阳性比率指的是前景体素选为中心的概率的比率
7.填充
7.1 SpatialPadd

参 数 介 绍
spatial_size: [int, int], 填充后的空间大小
method: str, 填充的方法, 有两种。“symmetric”(对称填充)(默认方式), “end”(仅在末端填充)
mode: str, 填充值的获取方式,如"constant"(填充0, “edge”(用边缘值填充),
用填充0来演示
from monai.transforms import SpatialPadD
pad = SpatialPadD(keys=["image", "label"], spatial_size=(512, 512, 32), method='symmetric', mode='constant')
data_pad = pad(data_crop[2]) # 把刚才裁剪的图像放大
print(data_pad['image'].shape) # (1, 512, 512, 32)
# 看边缘填充的什么
print(data_pad['image'][0, 0, 0, 0]) # 填充的是0
image, label = data_crop[2]["image"][0], data_crop[2]["label"][0]
imagepad, labelpad = data_pad["image"][0], data_pad["label"][0]
plt.figure("visualize", (8, 8))
plt.subplot(2, 2, 1)
plt.title("image")
plt.imshow(image[:, :, 16], cmap="gray")
plt.subplot(2, 2, 2)
plt.title("label")
plt.imshow(label[:, :, 16])
plt.subplot(2, 2, 3)
plt.title("pad image")
plt.imshow(imagepad[:, :, 20], cmap="gray")
plt.subplot(2, 2, 4)
plt.title("pad label")
plt.imshow(labelpad[:, :, 20])
plt.show()
查看结果

填充边缘
pad = SpatialPadD(keys=["image", "label"], spatial_size=(512, 512, 32), method='symmetric', mode='edge')

这种边缘填充方式适合于放大的小一点的情况,如果太大,就会出现这种情况。transform中还有很多其他方式,比如:放射变换(RandAffined),方向变换(Orientationd),分辨率变换(Spacingd),高斯模糊(RandGuassianNoised)等…
参考内容
- Monai文档:https://docs.monai.io/en/latest/transforms.html
- Tina姐博客:https://blog.csdn.net/BXD1314/article/details/119929011