文章目录
Evaluation Metrics
1. Model Metrics
-
Supervised learning : 使用训练误差作为一个简单地评估标准
-
other metrics:
- model specific : e.g. accuracy for classification ,mAP (分类的精度、召回)
- buisness specific : e.g. revenue,inference latency(商业例子中需要很多的评估指标,进行不同的综合)
2. Metrics for Classification
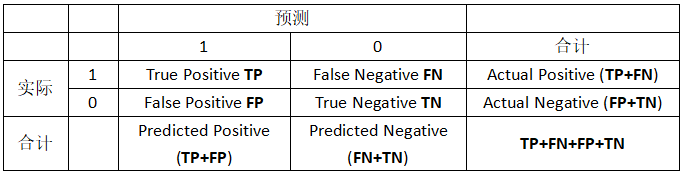
说明:P/N 表示监测到的样本的样本状态,T/F表示监测是否有错误:
- 以FP为例 :监测样本为Positive正样本,检查结果错误,因此此样本实际是negtive样本。
评估指标:
- 精度: correct predictions / examples
A c c u r a c y = T P + T N T P + F N + F P + T N Accuracy = \frac{TP + TN}{TP+FN+FP+TN} Accuracy=TP+FN+FP+TNTP+TN
sum(y == y_hat) / y.size
- 准确率 : correctly predicted as class i /predicted as class i
P r e c i s i o n = T P T P + F P Precision = \frac{TP}{TP+FP} Precision=TP+FPTP
sum((y_hat == 1) & (y==1)) / sum(y_hat == 1)
- 召回率 : correctly predicted as class i / examples in class i
R e c a l l = T P T P + F N Recall = \frac{TP}{TP+FN} Recall=TP+FNTP
sum((y_hat == 1) & (y==1)) / sum(y == 1)
- F1 : balance precision and recall,the harmonic mean of precision and recall:
F 1 − s c o r e = 2 p r / ( p + r ) F1-score = 2pr/(p+r) F1−score=2pr/(p+r)
3. AUC & ROC
AUC : ROC曲线下面的面积

TPR(真阳性率/召回/敏感度):
T P R / R e c a l l / S e n s i t i v i t y = T P T P + F N TPR/Recall/Sensitivity = \frac{TP}{TP+FN} TPR/Recall/Sensitivity=TP+FNTP
特异性:
S p e c i f i c i t y = T N T N + F P Specificity = \frac{TN}{TN+FP} Specificity=TN+FPTN
FPR(假阳性率):
F P R = 1 − S p e c i f i c i t y = F P T N + F P FPR = 1-Specificity = \frac{FP}{TN+FP} FPR=1−Specificity=TN+FPFP

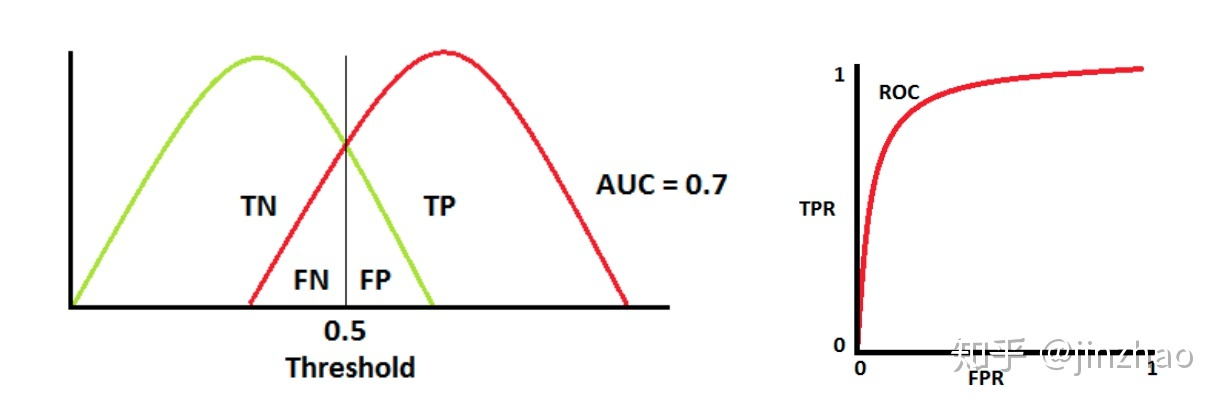
ROC是概率曲线,分别绘制TN、TP的概率曲线如下,通过调整threshold θ \theta θ可以达到最佳地区分正负两类
-
理想情况下,两条曲线完全不重叠时,模型可以将正类和负类别完全分开

-
两个部分重叠时,根据阈值,可以最大化和最小化概率,当AUC=0.7时,表示模型有70%的概率能够区分negtive和positive类别
-
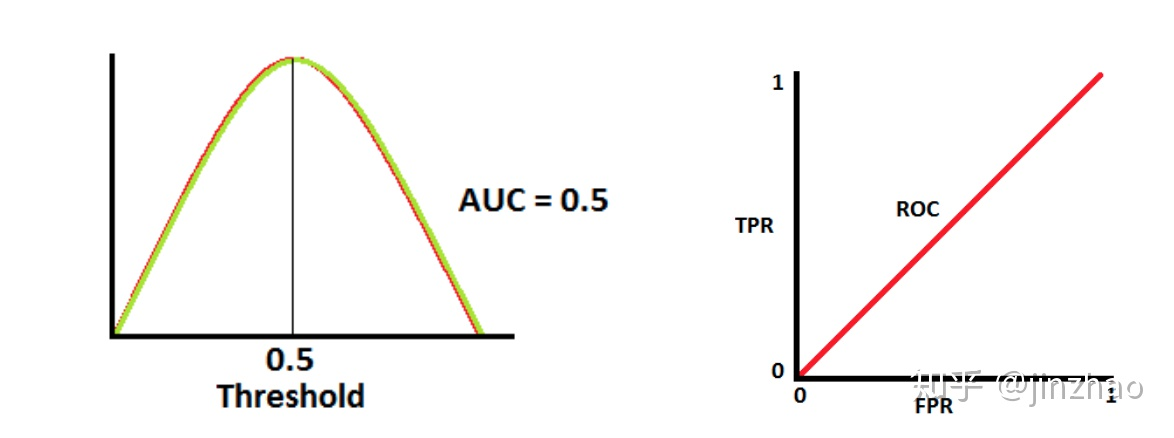
当AUC =0.5 时,表示模型将判断negtive 类和positive的概率相等
-
当AUC =0 时,表示模型将negtive 类预测为positive,反之亦然。(并非坏事)

什么时候使用ROC-AUC
- 关心的是对于排名的预测,而不需要输出经过良好校准的概率。
- 样本不均衡
- 同样关心Positive samples 和 Negative samples
underfiting & overfiting
1. Training and generalization errors
- training error:模型在训练数据上的误差
- generalization error:在新的数据上的误差

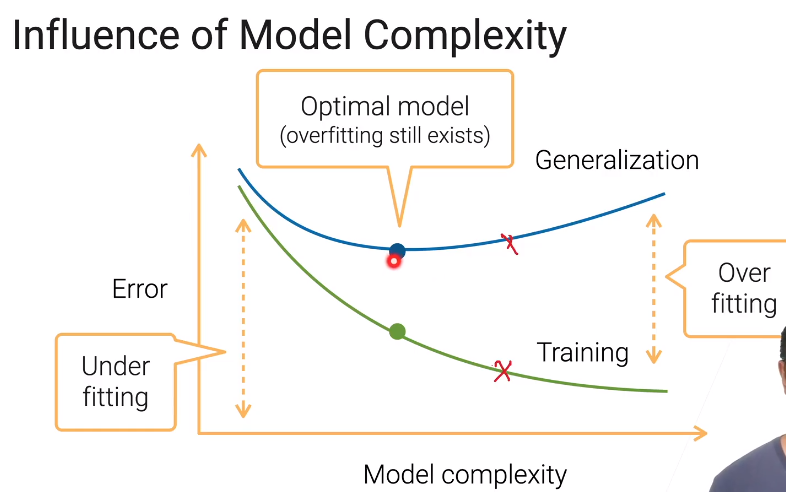
2. Model complexity
-
the ability to fit variety of functions:预测函数的复杂性
-
it’s hard to compare between very different algorithms :不同算法的复杂度很难对比
-
in an algorithm family. two factors matter : 参数量和每一个参数的取值范围
3. Data complexity
-
Multiple factors matters (实例、每个实例中的特征、时间空间结构、数据多样性)
-
Again,hard to compare among each dataset(无法对比不同的数据之间的复杂度)
Model Validation
1. Estimate Generalization Error
-
approximated by the error on a test dataset,which can be only use once(test 数据集是只能使用一次的)
-
validation dataset : data can be used multiple times(Valid验证数据集可以反复重复使用)
2. Hold out validation
-
split your data into “train” and “valid” set (将数据集划分为训练和验证)
-
often randomly select %n examples as the valid dataset(随机划分数据集)
-
random splitting may not work when:(一些不能随机划分的情况)
- sequential data
- examples belongs to group
- in-balanced data
3. K-fold cross validation
- useful when not sufficient data
- algorithm :
- partition the training data into K part
- for i = 1:k
- use the i-th part as the validation set,the rest for training
- report the averaged the K validation errors
- popular choices : k = 5 /10
4. Common Mistakes
contaminated valid set (验证数据被污染了,就是过度地参与训练)
-
valid set has examples from train set(原始样本中有重复的数据,Valid和train数据集中有相同数据)
-
information leaking(信息泄漏)