多元统计分析及R语言建模(第五版)习题
2. 多元数据的数学表达
2.2 练习题
1)对下面的相关系数矩阵,试用R语言求其逆矩阵、特征根和特征向量。

要求写出R语言计算函数。
> #创建矩阵R
> R=matrix(c(1.00,0.80,0.26,0.67,0.34,
+ 0.80,1.00,0.33,0.59,0.34,
+ 0.26,0.33,1.00,0.37,0.21,
+ 0.67,0.59,0.37,1.00,0.35,
+ 0.34,0.34,0.21,0.35,1.00),#必要的矩阵元素
+ nrow = 5,#行数
+ ncol = 5,#列数
+ byrow = TRUE);R#控制排列元素时是否按行进行
[,1] [,2] [,3] [,4] [,5]
[1,] 1.00 0.80 0.26 0.67 0.34
[2,] 0.80 1.00 0.33 0.59 0.34
[3,] 0.26 0.33 1.00 0.37 0.21
[4,] 0.67 0.59 0.37 1.00 0.35
[5,] 0.34 0.34 0.21 0.35 1.00
> #求R的逆矩阵
> solve(R)
[,1] [,2] [,3] [,4] [,5]
[1,] 3.3881372 -2.1222233 0.23706087 -1.0684729 -0.10622799
[2,] -2.1222233 2.9421167 -0.33593309 -0.1330915 -0.16163579
[3,] 0.2370609 -0.3359331 1.20698521 -0.3763728 -0.08811984
[4,] -1.0684729 -0.1330915 -0.37637284 2.0091273 -0.21562437
[5,] -0.1062280 -0.1616358 -0.08811984 -0.2156244 1.18504738
> #求矩阵R的特征值与特征向量
> eigen(R,symmetric = T)#symmetric指定矩阵R是否为对称矩阵
eigen() decomposition
$values
[1] 2.7922569 0.8263366 0.7790638 0.4205873 0.1817554
$vectors
[,1] [,2] [,3] [,4] [,5]
[1,] -0.5255426 0.3402197 -0.1665086 0.15937771 0.74493565
[2,] -0.5186716 0.2343491 -0.1777739 0.50822995 -0.62141694
[3,] -0.3131429 -0.9030775 -0.2287038 0.14942789 0.10843643
[4,] -0.4966433 0.0386900 -0.1185744 -0.83115510 -0.21672526
[5,] -0.3317705 -0.1108387 0.9350433 0.05615655 0.013548312)某厂对50个计件工人某月份工资进行登记,获得以下原始资料(单位:元):

试按组距为300编制频数表,计算频数、频率和累积频率,并绘制直方图。
(1)写出R语言程序;
(2)用R语言进行基本统计分析;
(3)用R语言做正太概率图并分析之;
> #导入xlsx库
> library(xlsx)
> #读取E2.2.xlsx表格中的E2.2数据
> data <- read.xlsx("D:\\2022-2023春季学期课程资料\\多元统计分析与建模\\E2.2.xlsx",
+ 'E2.2')
> #进行数据绑定
> attach(data)
> #查看前6行数据
> head(data)
X
1 1465
2 1760
3 1985
4 2270
5 2980
6 1375
> #进行数据概要统计
> summary(data)
X
Min. :1000
1st Qu.:1598
Median :1872
Mean :1897
3rd Qu.:2212
Max. :2980
> #以300为组距进行计算频数
> Y = X%/%300
> fY = table(Y)
> fY
Y
3 4 5 6 7 8 9
3 7 10 15 8 5 2
> #计算频率
> pfY = prop.table(fY)*100
> pfY
Y
3 4 5 6 7 8 9
6 14 20 30 16 10 4
> #计算累加频率
> print("累加频率如下(%):")
[1] "累加频率如下(%):"
> sums = 0
> for(i in pfY){
+ sums = i+sums
+ print(sums)
+ }
[1] 6
[1] 20
[1] 40
[1] 70
[1] 86
[1] 96
[1] 100> #绘制概率密度直方图
> hist (X, freq = FALSE,
+ breaks = seq(0, 3000, by = 300),
+ main = "工人工资概率密度直方图",
+ col = 1:7,
+ border = "red")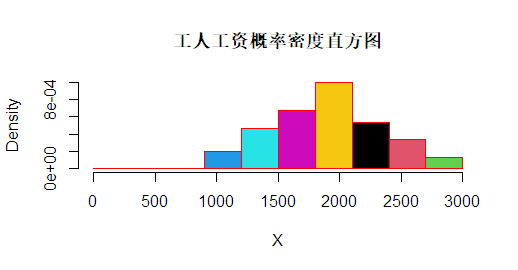
> #绘制频数直方图
> hist (X, freq = TRUE,
+ breaks = seq(0, 3000, by = 300),
+ main = "工人工资频数直方图",
+ col = 1:7,
+ border = "red")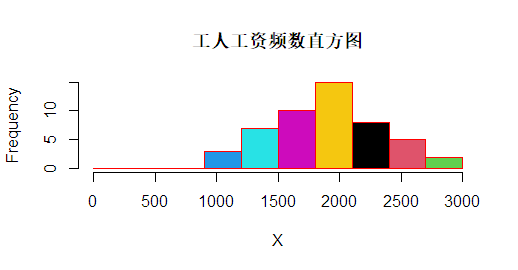
> #绘制正态概率图
> gz <- data$X
> qqnorm(gz);qqline(gz)
> #car包qqPlot函数
> library(car)
#载入需要的程辑包:carData
> qqPlot(gz, col = "blue", col.lines = "red")
[1] 5 15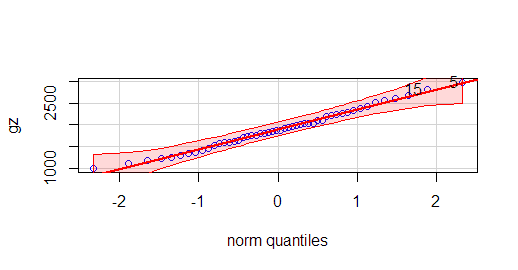
> #解除数据绑定
> detach(data)3)一份调查关于学生是否抽烟与每天学习时间关系的问题,具体数据见表2–5。
表2–5 部分学生抽烟与每天的学习时间调查表
编号 |
是否抽烟 |
每天学习时间 |
1 |
是 |
少于5小时 |
2 |
否 |
5-10小时 |
3 |
否 |
5-10小时 |
4 |
是 |
超过10小时 |
5 |
否 |
超过10小时 |
6 |
是 |
少于5小时 |
7 |
是 |
5-10小时 |
8 |
是 |
少于5小时 |
9 |
否 |
超过10小时 |
10 |
是 |
5-10小时 |
试用R语言对其做基本统计分析。
> #导入xlsx库
> library(xlsx)
> #读取E2.3.xlsx表格中的E2.3数据
> e2.3 <- read.xlsx('D:\\2022-2023春季学期课程资料\\多元统计分析与建模\\E2.3.xlsx',
+ 'E2.3')
> #绑定数据
> attach(e2.3)
> #进行数据概要统计
> summary(e2.3)
编号 是否抽烟 每天学习时间 NA.
Min. : 1.00 Length:30 Length:30 Mode:logical
1st Qu.: 3.25 Class :character Class :character NA's:30
Median : 5.50 Mode :character Mode :character
Mean : 5.50
3rd Qu.: 7.75
Max. :10.00
NA's :20 > #定量分析
> t1 = table(是否抽烟);t1
是否抽烟
否 是
4 6
> par(mfrow = c(1,2))
> #绘制直方图
> barplot(t1,col = 1:2)
> #绘制饼图
> pie(t1,col=1:2)
> t2 = table(每天学习时间);t2
每天学习时间
5-10小时 超过10小时 少于5小时
4 3 3
> par(mfrow = c(1,2))
> barplot(t2,col = 1:3)
> pie(t2,col=1:3)
> #二维列联表分析
> t3 = table(是否抽烟,每天学习时间);t3
每天学习时间
是否抽烟 5-10小时 超过10小时 少于5小时
否 2 2 0
是 2 1 3
> barplot(t3,legend = row.names(table(是否抽烟)),
+ args.legend=list(x=6,y=4,ncol=2,cex=0.7,box.col ="grey80"),
+ beside = T,col=1:2)
> t4 = table(每天学习时间,是否抽烟);t4
是否抽烟
每天学习时间 否 是
5-10小时 2 2
超过10小时 2 1
少于5小时 0 3
> barplot(t4,legend = row.names(table(每天学习时间)),
+ args.legend=list(x=6.5,y=4,ncol=3,cex=0.7,box.col ="grey80"),
+ beside = T,col=1:3)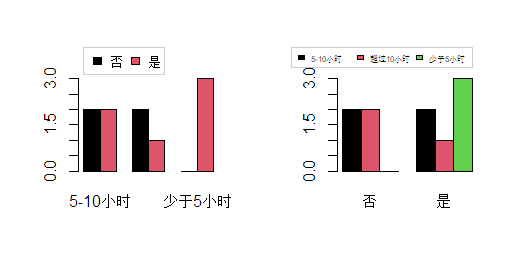
> #解除数据绑定
> detach(data)本文参考资料为多元统计分析及R语言建模/王斌会编著。 --5版. --北京:高等教育出版社,2020.1
ISBN 978-7-04-050916-8