Stream特性
1)不存储元素:元素通过Spliterator来遍历获取
2)不改变源对象:返回持有结果新的Stream
3)操作延迟执行:在需要结果的时候执行
Stream生命周期
Stream的生命周期:创建-->中间操作-->终端操作(终止操作)

1)创建
集合获取:Collection.stream()
数组创建:Arrays.stream(new String[2])
数值创建:Stream.of(1,2,3)
生成:Stream.generate(Supplier<T> s),属于无限流,需设定停止条件
迭代:Stream.iterate(final T seed, final UnaryOperator<T> f),属于无限流,需设定停止条件。UnaryOperator继承Function,输入和输出属同类型,输入是前一个的输出。
连接:Stream.concat(Stream<? extents T> a, Stream<? extents T> b),两个Stream连接一起生成新的Stream。
Stream也提供了Builder方式创建,如:Stream.builder().add(1).add(2).build()
2)中间操作
中间操作分为两大类:无状态操作(StatelessOp)、有状态操作(StatefulOp)
StatelessOp:filter\map\mapToInt\mapToLong\mapToDouble
\flatMap\flatMapToInt\flatMapToLong\flatMapToDouble\peek
StatefulOp:distinct\sorted\limit\skip

3)终端操作
终端操作有:ForEachOp、MatchOp、FindOp、ReduceOp和toArray\collect\count
ForEachOp:forEach\forEachOrdered
MatchOp:anyMatch\allMatch\noneMatch
FindOp:findFirst\findAny
ReduceOp:reduce\min\max

Stream执行
1) 顺序流
同步执行,在当前线程执行,不做线程转换
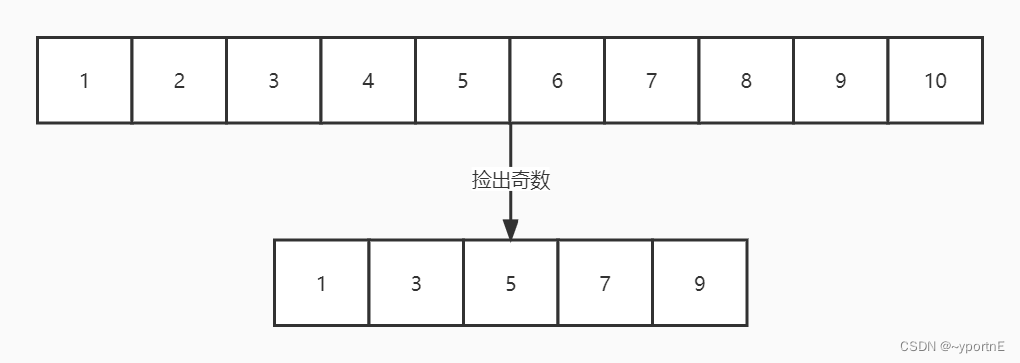
2) 并行流
异步执行,Fork多个线程执行,例如Collection的Spliterator中的trySplit的单个线程执行数量是1<<10个,小于1<<10就在同一个线程执行。

FunctionalInterface
Function接口,数学表达就是 y = f(x),x:输入值 f:操作 y:输出结果,输入值通过操作输出1个结果。其它的FuncationalInterface都是Function接口的变形,方面使用。
例如:
输入为null,就是Supplier,数学表达就是 y = f()
输出为null,就是Consumer,数学表达就是 f(x)
输出为boolean,就是Predicate,数学表达就是 boolean = f(x)
再如:
输入值变成两个,就是Bi**类接口
输入x或输出y变成某种特定类型就是**To或者To**或者**To**等类型
举例:Comparator就是 int = f(x,y),输入x,y两个值,输出1个int类型结果
返回值>0则x>y 返回值==0则x==y 返回值<0则x<y
FuncationalInterface特点就是接口中只有1个为实现方法,可以有多个方法,除了未实现的方法,其它的都必须有default修饰。目的就是结合lambda来使用,写出简洁的语句。
Collector
1)归集
Collectors.toCollection:Stream转成指定类型的集合
ArrayList<String> result = Stream
.of("1","2","3","4","5","6","7","8","9")
.collect(Collectors.toCollection(ArrayList::new));Collectors.toConcurrentMap:Stream转成ConcurrentMap,是ConcurrentHashMap
ConcurrentMap<String, String> result1 = Stream
.of("1","2","3","4","5","6","7","8","9")
.collect(Collectors.toConcurrentMap(key -> "key_" + key, value -> "value_" + value));
Collectors.toList:Stream转成List,是ArrayList
List<String> result2 = Stream
.of("1","2","3","4","5","6","7","8","9")
.collect(Collectors.toList());Collectors.toMap:Stream转成Map,是HashMap
Map<String, String> result3 = Stream
.of("1","2","3","4","5","6","7","8","9")
.collect(Collectors.toMap(key -> "key_" + key, value -> "value_" + value));Collectors.toSet:Stream转成Set,是HashSet
Set<String> result4 = Stream
.of("1","2","3","4","5","6","7","8","9")
.collect(Collectors.toSet());2)统计
Collectors.summarizingDouble:Stream转成DoubleSummaryStatistics
Collectors.summarizingInt:Stream转成IntSummaryStatistics
Collectors.summarzingLong:Stream转成LongSummaryStatistics
计算:均值、个数、最大值、最小值、总和等
IntSummaryStatistics result5 = Stream
.of("1","2","3","4","5","6","7","8","9")
.collect(Collectors.summarizingInt(Integer::valueOf));
result5.getAverage();
result5.getCount();
result5.getMax();
result5.getMin();
result5.getSum();Collectors.summingDouble:Stream转成double,计算总和
Collectors.summingInt:Stream转成int,计算总和
Collectors.summingLong:Stream转成long,计算总和
int result6 = Stream
.of("1","2","3","4","5","6","7","8","9")
.collect(Collectors.summingInt(Integer::valueOf));Collectors.averagingDouble:Stream转成double,计算均值
Collectors.averagingInt:Stream转成double,计算均值
Collectors.averagingLong:Stream转成double,计算均值
double result7 = Stream
.of("1","2","3","4","5","6","7","8","9")
.collect(Collectors.averagingInt(Integer::valueOf));Collectors.counting:Stream转成long,计算个数
long result8 = Stream
.of("1","2","3","4","5","6","7","8","9")
.collect(Collectors.counting());Collectors.maxBy:Stream转成Optional,包含最大值
Collectors.minBy:Stream转成Optional,包含最小值
Optional<String> result9 = Stream
.of("1", "2", "3", "4", "5", "6", "7", "8", "9")
.collect(Collectors.minBy(Comparator.comparingInt(Integer::parseInt)));
3)分组\分区
Collectors.groupingBy:Stream转成Map,是HashMap,Key计算结果,Value是根据计算结果分组
Collectors.groupingByConcurrent:Stream转成ConcurrentMap,是ConcurrentHashMap
Collectors.partitioningBy:Stream转成Map,是Partition,Key是true和false,Value是根据断言结果分区
Map<String, List<String>> result10 = Stream
.of("1", "2", "3", "4", "5", "6", "7", "8", "9")
.collect(Collectors.groupingBy(value -> value));4)接合
Collectors.joining:Stream转成String,数据中间按给定符号隔开,前后可加不同符号
String result11 = Stream
.of("1", "2", "3", "4", "5", "6", "7", "8", "9")
.collect(Collectors.joining("-", "前", "后"));5)归约
Collectors.reducing:Stream转成相应类型
String result12 = Stream
.of("1", "2", "3", "4", "5", "6", "7", "8", "9")
.collect(Collectors.reducing("0", (s, s2) -> s + s2));6)映射
Collectors.mapping:Stream转成另一个类型,可再次做处理
List<String> result13 = Stream
.of("1", "2", "3", "4", "5", "6", "7", "8", "9")
.collect(Collectors.mapping(value -> value + "_mapping", Collectors.toList()));
7)收集再处理
Collectors.collectingAndThen:可多次处理数据
List<String> result14 = Stream
.of("1", "2", "3", "4", "5", "6", "7", "8", "9")
.collect(Collectors.collectingAndThen(Collectors.toList(), strings -> {
strings.forEach(System.out::print);
return Arrays.asList("aa", "bb", "cc");
}));
result14.forEach(System.out::print);