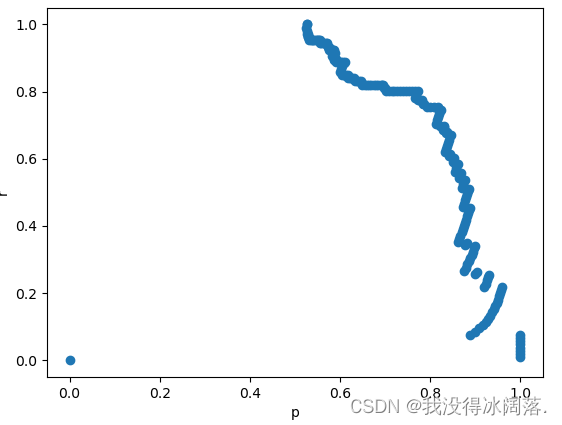
P-R曲线就是精确率precision vs 召回率recall 曲线,以recall作为横坐标轴,precision作为纵坐标轴。首先解释一下精确率和召回率。解释精确率和召回率之前,先来看下混淆矩阵:

把正例正确分类为正例,表示为TP(true positive),把正例错误分类为负例,表示为FN(false negative),
把负例正确分类为负例,表示为TN(true negative), 把负例错误分类为正例,表示为FP(false positive)
通过统计我们获得TP、TN、FP、FN的数目,然后利用下式来计算Precision值与Recall值。
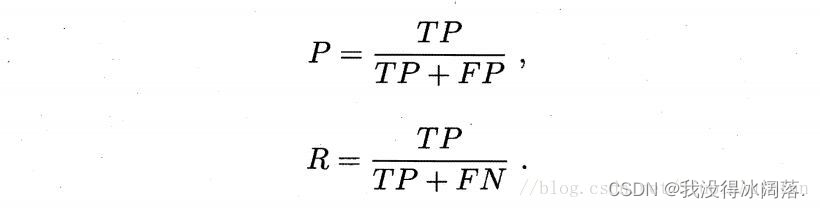
那么P-R曲线是怎么来的呢?
算法对样本进行分类时,都会有置信度,即表示该样本是正样本的概率,比如99%的概率认为样本A是正例,1%的概率认为样本B是正例。通过选择合适的阈值,比如50%,对样本进行划分,概率大于50%的就认为是正例,小于50%的就是负例。
通过置信度就可以对所有样本进行排序,再逐个样本的选择阈值,在该样本之前的都属于正例,该样本之后的都属于负例。每一个样本作为划分阈值时,都可以计算对应的precision和recall,那么就可以以此绘制曲线。
生成假数据
数据:label,score
假数据中 score大于0.5,则label以70%取‘t’,以此类推
import random
from matplotlib import pyplot as plt
data = []
for i in range(200):
score = random.random()
if score > 0.5:
if random.random() > 0.3:
label = 't'
else:
label = 'f'
else:
if random.random() > 0.7:
label = 't'
else:
label = 'f'
data.append([label, score])
data.sort(key=lambda x:x[1])
for label, score in data:
print(f'label: {
label}, score: {
score:.2f}')
PR计算
def pr_eavl(data, score):
data.sort()
tp = len([i for i in data if i[0]=='t' and i[1]>score])
fp = len([i for i in data if i[0]=='f' and i[1]>score])
tn = len([i for i in data if i[0]=='f' and i[1]<score])
fn = len([i for i in data if i[0]=='t' and i[1]<score])
p = tp / (tp + fp)
r = tp / (tp + fn)
return p, r
绘图
p_list = []
r_list = []
for i in data:
p, r = pr_eavl(data, i[1])
p_list.append(p)
r_list.append(r)
plt.scatter(p_list, r_list)
plt.xlabel('p')
plt.ylabel('r')
plt.show()
绘制效果