一、背景:
搞了elasticsearch和kibana的安装和配置,在进行分词的时候没有达到自己预想的效果,于是写一下elasticsearch的ik分词器的安装和配置(自定义分词)。
二、解决方式:
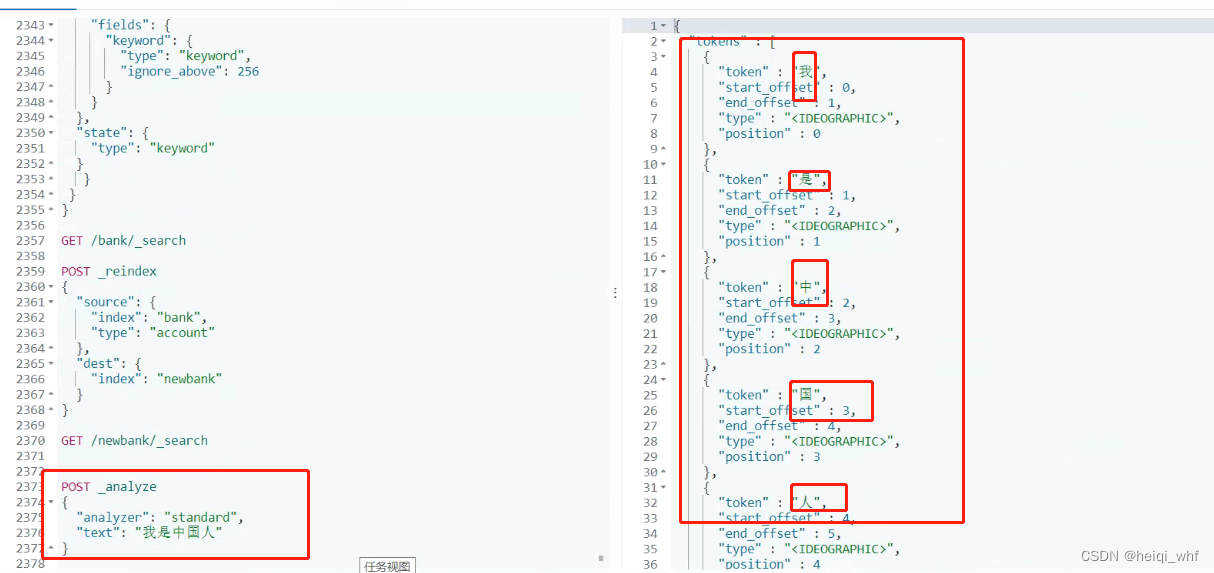
1:首先看看没有加ik分词器的效果。
POST _analyze
{
"analyzer": "standard",
"text": "我是中国人"
}
2:下载ik软件包。
https://github.com/medcl/elasticsearch-analysis-ik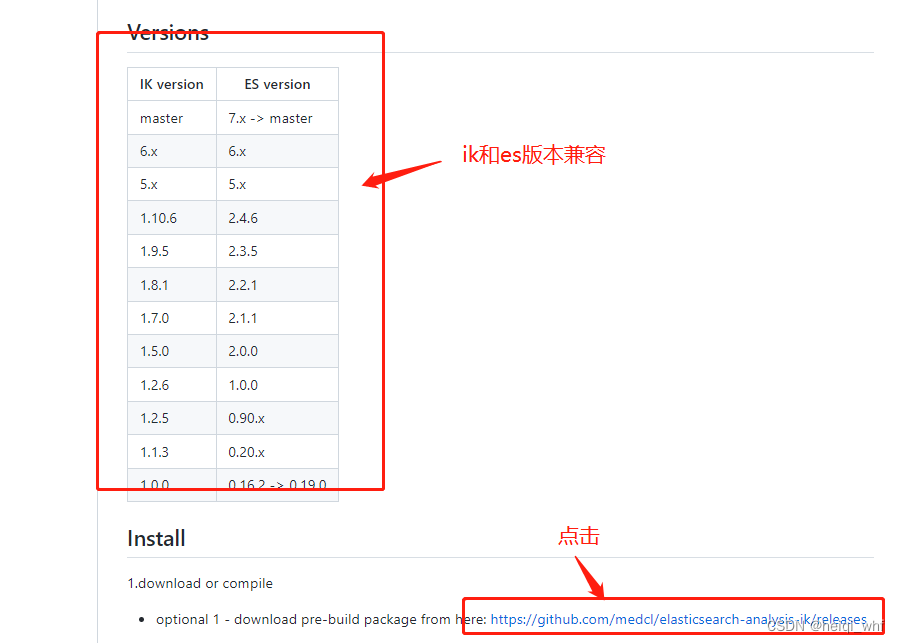
3:选择自己响应版本。

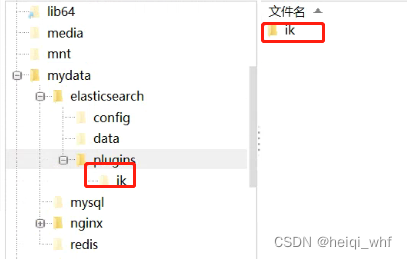
4:将下载好的文件上传到我们elasticsearch文件夹的plugins下。
5: 重启elasticsearch ,测试。
docker restart es的名称或者ip
POST _analyze
{
"analyzer": "ik_smart",
"text": "我是炎黄子孙"
}
POST _analyze
{
"analyzer": "ik_max_word",
"text": "我是中国人"
}
6:上面已经安装好了ik分词器,但也不是我们想要的结果,"炎黄子孙"怎么能拆分成二个"炎黄"
"子孙",我们要自定义词库,创建nginx等文件夹。
mkdir nginx下载nginx 镜像
docker run -p 80:80 --name nginx -d nginx:1.10
7:将容器内的配置文件拷贝到当前目录。
docker container cp nginx:/etc/nginx .
注意:别忘了后面的点8:修改文件名称:
mv nginx conf9:将conf 移动到/mydata/nginx 下
mv conf nginx/10:终止原容器。
docker stop nginx11:执行命令删除原容器。
docker rm $ContainerId12:创建新的 nginx,执行下面的命令。
docker run -p 80:80 --name nginx \
-v /mydata/nginx/html:/usr/share/nginx/html \
-v /mydata/nginx/logs:/var/log/nginx \
-v /mydata/nginx/conf:/etc/nginx \
-d nginx:1.10
13:在nginx 下的html文件夹下创建index.html。


14:在html文件夹下创建es文件夹。
mkdir es
15:进入es,创建fenci.txt文件
vi fenci.txt
16:自定义我们的词。
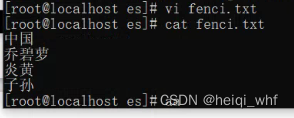
输入:http://192.168.56.10/es/fenci.txt

17: 修改/usr/share/elasticsearch/plugins/ik/config/中的 IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict"></entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<entry key="remote_ext_dict">http://192.168.56.10/es/fenci.txt</entry>
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties18:重启es。
![]()
19:验证效果。

三、总结:
送人玫瑰 手有余香