#练习题目–裂缝识别
1、数据集准备
数据集为混凝土照片,共分为两类,存在裂缝的图片和不存在裂缝的图片。整个数据集分为训练集、验证集、测试集三部分,其比例可以不同,不同的比例可能造成不同的训练效果,这里练习过程中采用训练集、验证集、测试集:3:1:1。;注意:所有图片的尺寸需要保持一致,这里是128×128的图片,可以根据实际情况自己选择,图像越大运算速度越慢。下图是存在裂缝的照片
2、数据读取及处理准备工作
(1)算法库导入
from keras.layers import Conv2D,MaxPooling2D,Dropout,Dense,Flatten,Activation
import numpy as np
from keras.layers.normalization import BatchNormalization
import cv2
from keras.preprocessing.image import ImageDataGenerator
import matplotlib.pyplot as plt
from keras.utils import plot_model
from keras import optimizers
import os
from keras.utils.vis_utils import plot_model
import keras
from keras import regularizers
from keras.callbacks import Callback
from keras.models import Sequential
from keras.callbacks import ModelCheckpoint,EarlyStopping#检查点
(2)读取图片数据
这里是二分类,类别设置为2、每次对128张图片进行批量训练,
num_classes = 2 #类别
batch_size =128 #批量大小
epochs =50#训练次数
#读取图片数据
file1=os.listdir('F:/BankCardOCR/dataset/digit_dataSet/train(128^2)/1')
file2=os.listdir('F:/BankCardOCR/dataset/digit_dataSet/train(128^2)/0')
file3=os.listdir('F:/BankCardOCR/dataset/digit_dataSet/validation128^2/1')
file4=os.listdir('F:/BankCardOCR/dataset/digit_dataSet/validation128^2/0')
m=len(file1)+len(file2)#训练集图片数量
m2=len(file3)+len(file4)#验证集图片数量
(3)处理工作
def changeDim(img):#扩展维度变4维
img=np.expand_dims(img,axis=2)#
return img
def Generator(path, batch_size):
data = []
label = []
while True:
file=os.listdir(path)
i=0
img1=[]
img2=[]
imgname1=os.listdir(path + '/' + file[0])
imgname2 = os.listdir(path + '/' + file[1])
for name1 in imgname1:
img1.append(path + '/' + file[0]+'/'+name1)
for name2 in imgname2:
img2.append(path + '/' + file[1] + '/'+name2)
imgname=img1+img2######横向连接
# print(imgname)
print((len(imgname)))
np.random.shuffle(imgname)
#读取图像,根据文件名制作标签
for finame in imgname:
im = cv2.imread(finame,0)
label_a=finame.split('/')[-2]
im=changeDim(im)
data.append(im)
label.append(label_a)
if (len(label) == batch_size ):
data = np.array(data)
data=data.astype('float32')
data/=255.0#归一化
label = keras.utils.to_categorical(label, 2)#标签热码
yield data, label
data = []
label = []
i+=1
3、网络结构设计
一般卷积神经网络结构包含卷积层、池化层(最大池化、平均池化),全连接层,正则化层、丢弃层。下面代码是常用的一种算法结构,采用Sequential(),可以不断的添加层,一般卷积层越多识别越好,但是,越多或导致训练参数量过大,过拟合等问题。卷积层的卷积核、卷积尺寸、卷积层数据也是可以根据识别目标而选择的。越简单的识别对象,对卷积神经网络的能力要求越低。所以,相对多分类识别,二分类任务是非常简单的。所以模型可以不断轻量化。下面为实现裂缝识别的一个demo。效果不好勿喷
model = createModel(num_classes)
def createModel(num_classes):
model = Sequential() # 顺序模型
model.add(
Conv2D(16, (3, 3), strides=(1, 1), padding="same", input_shape=(128, 128, 1), data_format='channels_last',
kernel_initializer='uniform', activation="relu"))
# model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
# model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3), strides=(1, 1), activation="relu"))
# model.add(BatchNormalization())
# model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
model.add(Conv2D(64, (3, 3), activation="relu"))
model.add(Conv2D(128, (3, 3), activation="relu"))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2), name="pool5"))
model.add(Conv2D(256, (1, 1)))
model.add(Conv2D(256, (2, 2)))
model.add(Conv2D(256, (2, 2), activation="relu"))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2), name="pool1"))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(256))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(BatchNormalization())
model.add(Dropout(0.5))
model.add(Dense(num_classes))
model.add(BatchNormalization())
model.add(Activation("softmax"))
model.summary()
return model
4、运行
网络结构构建后,还需要确定超参数,这里超参数包括学习次数、学习率。这里没有设置学习率。采用的adam自带的学习率,当然也可以设置。
这里‘’batch_size‘’参数也是一个重要的参数,一般选用2的倍数,数值越小训练越慢,且训练效果不好,所以一般选择4、8、16等,当然这也和你的电脑配置有关系,你要是设置为32或64或更大,可能无法运行不了,因此需要慎重选了。
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])#此处二分类选用'binary_crossentropy'损失函数
# 设置检查点
checkpointer = ModelCheckpoint(filepath='./checkpoint/weights(s128).hdf5', monitor='val_loss',verbose=1, save_best_only=True)
#训练集图片路径
trainpath='F:/BankCardOCR/dataset/digit_dataSet/train(128^2)'
#测试集图片路径
testpath='F:/BankCardOCR/dataset/digit_dataSet/validation128^2'
history=model.fit_generator(Generator(trainpath, batch_size),
steps_per_epoch=int(m) // batch_size,
epochs=epochs,
verbose=1,
validation_data=Generator(testpath, batch_size),
validation_steps=int(m2) // batch_size,
shuffle=True,
callbacks=[checkpointer])
# 保存训练模型
model.save('./checkpoint/model(s128).h5')
通过测试集进行验证
score = model.evaluate_generator(Generator(testpath,batch_size),steps=int(m) // batch_size)
print('validation loss:', score[0])
print('validation accuracy:', score[1])
print(history.history.keys())
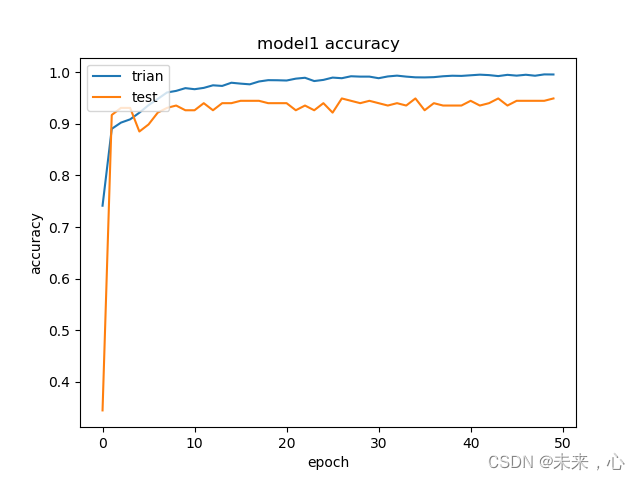
5、模型训练结果
训练结果
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.title('model1 accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['trian','test'],loc='upper left')
plt.show()
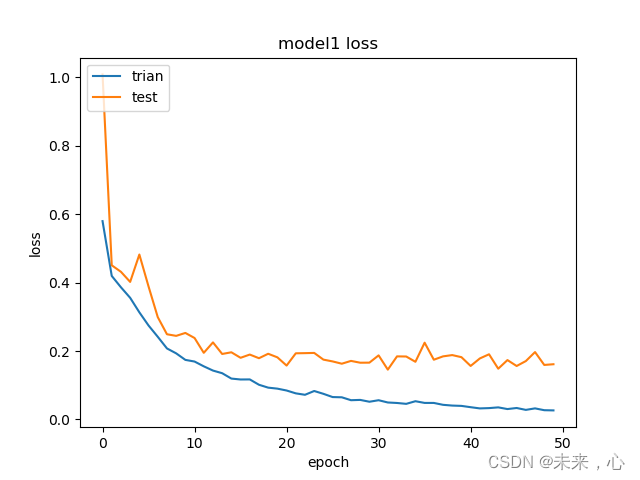
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model1 loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['trian','test'],loc='upper left')
plt.show()
下面是训练效果图,当然判断模型好坏是存在常用的几个指标的,准确率、召回率、F1综合评价参数,均有对应的计算公式,这里就不再讲了,后续会单独分享受。
这个数据集是本人花费大量时间整理的,如果需要有偿,谢谢。