一、 前言
2021年底,领导给了个tof模块,要求基于此开发一个演示程序,实现3D人脸识别的功能。当时听他说出3D人脸识别就有点头疼,第一是想自己之前没接触这样的项目;第二是在想3D人脸数据相比于2D人脸数据,恐怕没后者那么多。基于快速开发出产品以及自身能力的想法,向领导建议使用2D+技术路线,即采用rgb图做人脸识别,采用深度图做真假脸识别,领导同意了。
rgb图用到的就是些网上开源、成熟的模型,如retinaface、mobileface,这部分不是今天的主题,也没什么好说的,网上博客大把。主要说说深度图吧,简单把过程记录一下,方便自己且抛砖引玉,如果有错漏之处,还请指出,谢谢!
二、 过程
(一)图片预处理过程
先给大伙看看tof保存的深度图,16 bit png格式,每个像素值的实际物理意义是距离,单位是mm。

我没有上传错,原图就是这样,看起来乌漆嘛黑的。因为它是16 bit,像素值范围是[0, 65536),下面给它映射到[0, 256),再给它像素反转一下。
import cv2
import numpy as np
def u16_to_u8(depth_image):
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(depth_image)
alpha = 255 / (max_val - min_val)
beta = -min_val
result = ((depth_image + beta) * alpha).astype(np.uint8)
return result
depth_image = cv2.imread(r"test.png", cv2.IMREAD_ANYDEPTH)
depth_image = u16_to_u8(depth_image)
depth_image = 255 - depth_image
cv2.imshow('depth_image', depth_image)
key = cv2.waitKey(0)
显示结果如下
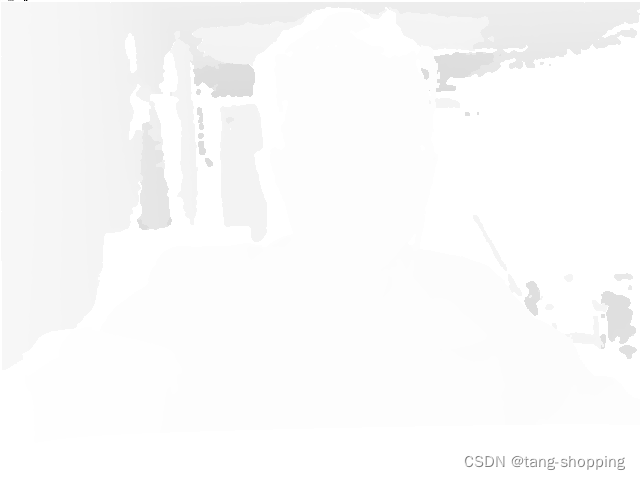
可以看见也没什么卵区别,都是一片糊。如果要根据深度图来做分类,区分真假脸,这样的数据恐怕不好做,所以需要再做进一步处理,比如直方图均衡。先试试opencv自带的直方图均衡函数。
depth_image = cv2.imread(r"test.png", cv2.IMREAD_ANYDEPTH)
depth_image = u16_to_u8(depth_image)
cv_he = cv2.equalizeHist(depth_image)
cv2.imwrite(r"t1.png", cv_he)

看起来效果好了点,但还是有点不够。下面试试openni的直方图均衡函数。
def get_his_img(img, his_size = 65536):
if len(img.shape) == 2:
img = img[np.newaxis, :]
_, h, w = img.shape
hist = cv2.calcHist(img, [0], None, [his_size - 1], [1, his_size])
num = np.sum(hist)
hist = np.cumsum(hist.squeeze())
for s in range(0, his_size - 1):
hist[s, ] = int((1.0 - (hist[s, ] / num)) * his_size)
for ii in range(h):
for jj in range(w):
if img[:, ii, jj] > 0:
img[:, ii, jj] = hist[img[:, ii, jj], ]
if len(img.shape) == 3:
img = img.squeeze()
return img
depth_image = cv2.imread(r"test.png", cv2.IMREAD_ANYDEPTH)
my_he = get_his_img(depth_image, his_size = 65536)
my_he = u16_to_u8(my_he)
cv2.imwrite(r"t1.png", my_he)

这样才算好,脸部轮廓明显,估计用个逻辑回归都可以很好拟合。仔细看代码,可以看见openni对原先像素值为0的像素是不做处理,它的处理对象是像素值为[1, 256)的像素。当然你们做个筛选,把近距离与远距离的像素值都置为0,再用opencv api来做,估计效果也不错。
(二)真假脸分类算法开发
先给大家看看真假脸的图片,看完会有更深的认识。出于减少运算量与降噪需要,我们取出face roi。下面分别是真人脸、图片脸、电子屏幕脸,根据需要缩放到112x112大小(使用letterbox方式)。



一开始想无脑直接上机器学习,但是公司服务器没有,办公的PC太辣鸡(呵呵),不想用,所以想着用传统机器视觉来做。
1. 普通直方图比较
准备一张真人脸(随机抽取的一张正面人脸)与测试人脸(无论真假脸,预处理一致)做比较,看代码吧,一目了然。
def compare_img(true_face, fake_face):
true_face = cv2.resize(true_face, (112, 112)).astype(np.float32)
fake_face = cv2.resize(fake_face, (112, 112)).astype(np.float32)
true_hist = cv2.calcHist([true_face], [0], None, [256], [0, 256])
fake_hist = cv2.calcHist([fake_face], [0], None, [256], [0, 256])
match1 = cv2.compareHist(true_hist, fake_hist, cv2.HISTCMP_BHATTACHARYYA)
match1 = 1 - match1
if (match1 < 0.75): # 阈值是根据我的数据集统计而来,下同
print(0)
match2 = cv2.compareHist(true_hist, fake_hist, cv2.HISTCMP_CORREL)
if (match2 < 0.965):
print(1)
match3 = cv2.compareHist(true_hist, fake_hist, cv2.HISTCMP_CHISQR)
if (match3 > 8000):
print(2)
print("巴氏距离:%f, 相关性:%f, 卡方:%f\n" %(match1, match2, match3))
img_dir = r"C:\Users\Horizon-Robotics\Pictures"
fake_face_path = os.path.join(img_dir, "test.png")
true_face_path = os.path.join(img_dir, "H5.png")
print(os.path.basename(true_face_path), " vs ", os.path.basename(fake_face_path))
true_face = cv2.imread(true_face_path, cv2.IMREAD_ANYDEPTH)
fake_face = cv2.imread(fake_face_path, cv2.IMREAD_ANYDEPTH)
compare_img(true_face, fake_face)
该方法性能不够,后来采集了个小数据集(真假人脸各130张图片),利用该算法一测试,结果惨不忍睹。想了一下,失败的原因如下(自己瞎想的,如有大神有心得,还望不吝赐教)。
(1)人脸是随机抽取的,不具有代表性;
(2)该算法得到的直方图,只是对图片做了个总体地、粗略的估计。而在全局上,真假人脸可能具有相似的直方图分布。所以我们应该关注局部的特征?
2. LBP-直方图比较
出于更多关注局部特征,引入了LBP算法,正如它的介绍所说:“用于纹理特征提取,提取的特征是图像的局部的纹理特征。LBP就是一种局部信息,它反应的内容是每个像素与周围像素的关系。”

做了lbp的图片直方图如上,可以看见二者区别还是有的,而且很明显。后来跑了下上面的小数据集,结果准确率是100%,与上面方法相比,该方法是可行的。此处还有个考量:是否统计一下数据集里所有真人脸的lbp直方图,然后得到一张平均的人脸,之后拿这张平均人脸去做计算,防止其过拟合。代码如下:
def my_LBP(img):
dst = np.zeros(img.shape, dtype=img.dtype)
h, w = img.shape # 参数-1为按原通道读入,不写的话默认读入三通道图片,这里获取高度和宽度。
#print("h, w",h,w) #
"""
对于每个cell中的一个像素,将相邻的8个像素的灰度值与其进行比较,
若周围像素值大于中心像素值,则该想点的位置被标记为1,否则标记为0.
"""
for i in range(1, h - 1):
for j in range(1, w - 1):
center = img[i][j]
code = 0
# 邻域灰度值比较
# code |= (img[i - 1][j - 1] >= center) << (np.uint8)(7)
# print(code)
code |= (img[i - 1][j - 1] >= center) << (np.uint8)(7) # 首先对左上角的数进行0|1的判断,然后将其结果存入二进制数的第7位。
code |= (img[i - 1][j] >= center) << (np.uint8)(6)
code |= (img[i - 1][j + 1] >= center) << (np.uint8)(5)
code |= (img[i][j + 1] >= center) << (np.uint8)(4)
code |= (img[i + 1][j + 1] >= center) << (np.uint8)(3)
code |= (img[i + 1][j] >= center) << (np.uint8)(2)
code |= (img[i + 1][j - 1] >= center) << (np.uint8)(1)
code |= (img[i][j - 1] >= center) << (np.uint8)(0)
dst[i - 1][j - 1] = code
#print("dst[i - 1][j - 1]",i,j,dst[i - 1][j - 1])
return dst
fake_img = cv2.imread(r'D:\AOBI\0\0_26.png', cv2.IMREAD_GRAYSCALE)
true_img = cv2.imread(r'D:\AOBI\1\1_0.png', cv2.IMREAD_GRAYSCALE)
fake_img = my_LBP(fake_img)
true_img = my_LBP(true_img)
#cv2.imshow('fake_img', fake_img)
#cv2.imshow('true_img', true_img)
#key = cv2.waitKey(0)
plt.subplot(2,1,1)
plt.hist(fake_img.ravel(), 256, [0,256], facecolor='g', label = "fake")
plt.subplot(2,1,2)
plt.hist(true_img.ravel(), 256, [0,256], facecolor='r', label = "true")
plt.show()
3. 逻辑回归
在方法1遇挫后,还是真香定律地试了下逻辑回归。大致流程就是将face roi做直方图均衡预处理,再缩放至32x32,之后reshape成向量,喂入逻辑回归模型。最后的测试结果98.4%准确率。但是它有个问题就是,类间距离不够大,即预测的结果有一些在阈值0.5附近。还有就是那些错分样本的输出概率值都蛮离谱的。放张错分的假人脸图片,给大伙看下。

可以看见还是比较像人脸的,难怪会分类错误。对于这样的问题,想了下,可能是模型的拟合能力不够,对于一些类人脸的假脸图片就有点力不从心。
4. LBP-逻辑回归
对于方法3的问题,无脑的上CNN是我不想的,所以我选择提升输入图片的质量。刚好上面用了LBP,就显示看了下。
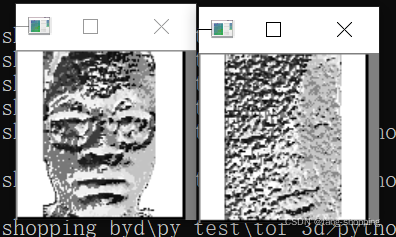
可以看出,对于真人脸,LBP处理后人脸轮廓还是有的。但对于假人脸,即使其本来像真人脸,但是已经不那么明显了。于是将其输入逻辑回归模型训练,最后测试结果的准确率是100%。
三、 后语
近几年的感受就是,深度学习里要好好结合传统视觉,能取得让人惊喜的效果。以及多总结,多记录,多分享。