一:Pattern-Exploiting Training(PET)
它通过人工构建的模版与BERT的MLM模型结合,能够起到非常好的零样本、小样本乃至半监督学习效果,而且该思路比较优雅漂亮,因为它将预训练任务和下游任务统一起来了。
然而,人工构建这样的模版有时候也是比较困难的,而且不同的模版效果差别也很大,如果能够通过少量样本来自动构建模版,也是非常有价值的。
主要的思想是借助由自然语言构成的模版(英文常称Pattern或Prompt),将下游任务也转化为一个完形填空任务,这样就可以用BERT的MLM模型来进行预测了

二:P-tuning
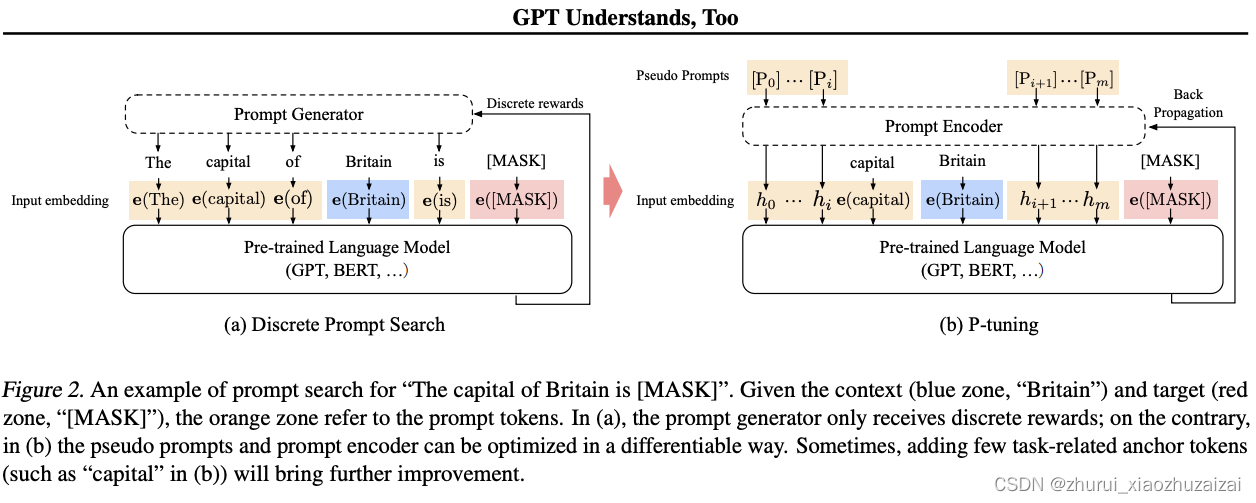
Arxiv上的论文《GPT Understands, Too》提出了名为P-tuning的方法,成功地实现了模版的自动构建。不仅如此,借助P-tuning,GPT在SuperGLUE上的成绩首次超过了同等级别的BERT模型,这颠覆了一直以来“GPT不擅长NLU”的结论,也是该论文命名的缘由。
这里的[u1]~[u6],代表BERT词表里边的[unused1]~[unused6],也就是用几个从未见过的token来构成模板,这里的token数目是一个超参数,放在前面还是后面也可以调整。
增强相关性 #
在原论文中,P-tuning并不是随机初始化几个新token然后直接训练的,而是通过一个小型的LSTM模型把这几个Embedding算出来,并且将这个LSTM模型设为可学习的。这样多绕了一步有什么好处呢?原论文大概的意思是:**LSTM出现的token表示相关性更强,某种程度上来说更像“自然语言”(因为自然语言的token之间不是独立的),此外还能防止局部最优。**有人在Github上进一步向作者确认了一下(参考这里),效果上的差别是通过LSTM多绕一步的方法可以使得模型收敛更快、效果更优。
然而,这样多了一个LSTM,总感觉有些别扭,而且实现上也略微有点麻烦。按照作者的意思,LSTM是为了帮助模版的几个token(某种程度上)更贴近自然语言,但这并不一定要用LSTM生成,而且就算用LSTM生成也不一定达到这一点。笔者认为,更自然的方法是在训练下游任务的时候,不仅仅预测下游任务的目标token(前面例子中的“很”、“新闻”),还应该同时做其他token的预测。
比如,如果是MLM模型,那么也随机mask掉其他的一些token来预测;如果是LM模型,则预测完整的序列,而不单单是目标词。这样做的理由是:因为我们的MLM/LM都是经过自然语言预训练的,所以我们(迷之自信地)认为能够很好完成重构的序列必然也是接近于自然语言的,因此这样增加训练目标,也能起到让模型更贴近自然语言的效果。经过笔者的测试,加上这样辅助目标,相比单纯优化下游任务的目标,确实提升了效果。

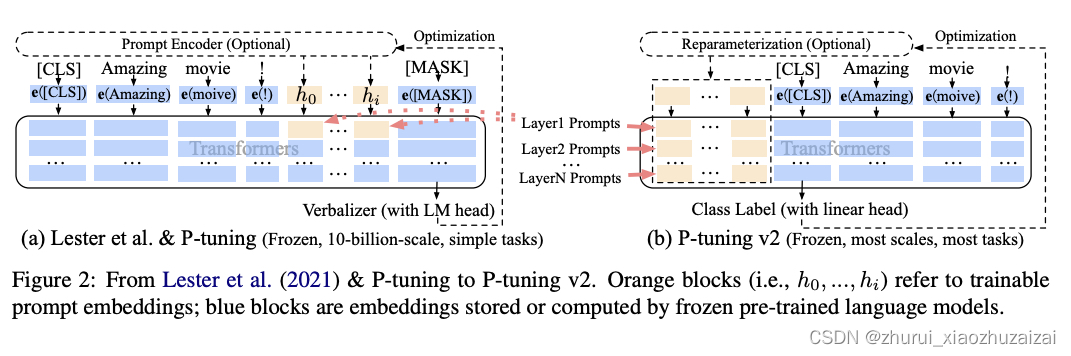
P-tuning-v1
P-tuning-v2
将prompt信息作为前缀加入;
其次是一个深层的前缀,即在模型的每一层前面都添加上前缀,以尽可能挖掘信息并且额外添加的参数并不会很大。
另外,作者去除了之前的重参数化方法;并且引入了多任务学习,比如说,在 NER 中,可以同时训练多个数据集,不同数据集使用不同的顶层 classifer,但是 prefix continuous prompt 是共享的;
最后就是删除了之前的verbalizer。因为并不是每一个任务都需要有意义的标签,因此作者为了更为通用的框架,回归到最初的CLS+MLP头的范式。,
du
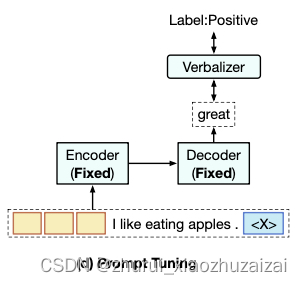
三:PPT(pretrained prompt tuning)
保持模型fixed. 只训练prompt.
四:prompt tuning的应用
1 Prompt tuning用于迁移学习
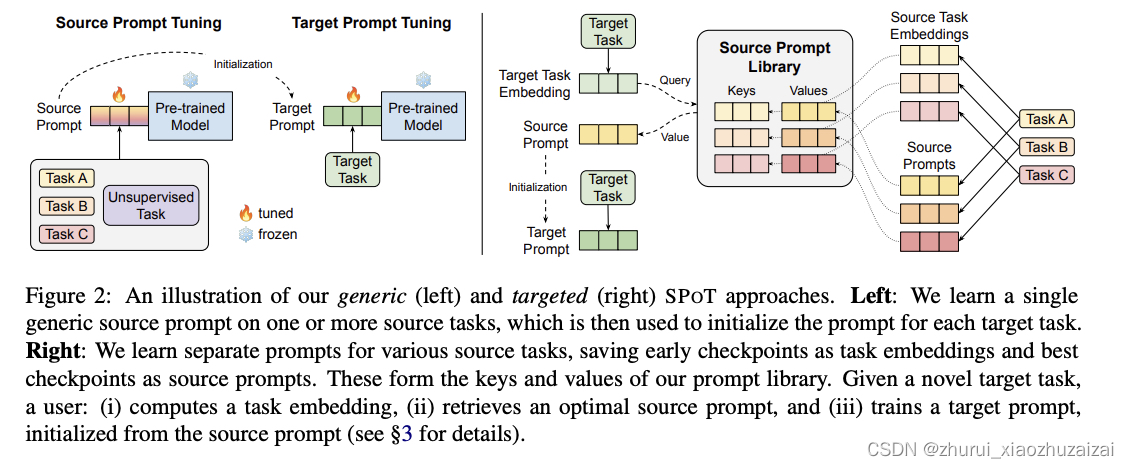
《SPoT: Better Frozen Model Adaptation through Soft Prompt Transfer》摘要:随着预训练的语言模型越来越大,人们对将这些模型应用于下游任务的参数高效方法的兴趣也越来越大。 在之前P-tuning方法的基础上,作者提出了一种基于提示的迁移学习方法,称为SPOT:软提示转移。
SPOT首先学习一个或多个源任务的提示,然后用它来初始化目标任务的提示。
作者表明,SPOT显著地提高了PROMPT-TUNING在许多任务中的性能。
更重要的是,SPOT与模型fine-tuning效果可比,甚至优于fine-tuning,而参数效率更高(最多可减少27,000倍的特定任务参数)。
作者进一步对26个NLP任务和160个源-目标任务的组合进行了大规模的任务转移性研究,并证明了任务往往可以通过及时转移而相互受益。最后,作者提出了一个简单而高效的检索方法,该方法将任务提示作为任务嵌入来识别任务之间的相似性,并预测一个给定的新目标任务的最可转移的源任务。研究问题:作者上面已经提到了主要的思路,就是通过上游任务学习到的prompt来初始化下游的任务prompt。因此这里产生了两个问题:
对于一个给定的目标任务,什么时候应该将学习到的prompt用于目标任务
能否通过学到的prompt,更为准确的为目标任务选择最合适的源任务扫描二维码关注公众号,回复: 14839776 查看本文章
为了提高P-tuning的性能,SPOT引入了源提示调整,这是一个介于语言模型预训练和目标提示调整之间的中间训练阶段(上图,左),在一个或多个源任务的学习一个提示(同时仍然保持基本模型的冻结),然后用于初始化目标任务的提示。 作者的方法保留了P-tuning的所有计算优势,也就是说,对于每个目标任务,它只需要重新存储一个小的特定任务的提示,同时可以为所有任务重复使用一个冻结的预训练模型。(这里用来验证对于不同任务是否prompt迁移是否都有效)
但是什么源任务最适合目标任务迁移呢?作者基于prompt设计了一种新的任务相似度关系计算。如上图右所示,先得到目标任务的embedding,同时,已经在上游的n个任务上得到了n*k个prompt;每个任务结合prompt得到其任务表示,再与目标任务进行相似度计算,最终相似度最高的k个作为相关性最大的源任务,并将这些任务的prompt加权初始化目标任务的prompt;然后再在目标任务上进行P-tuning,得到新的prompt.
2 Prompt-tuning鲁棒性研究
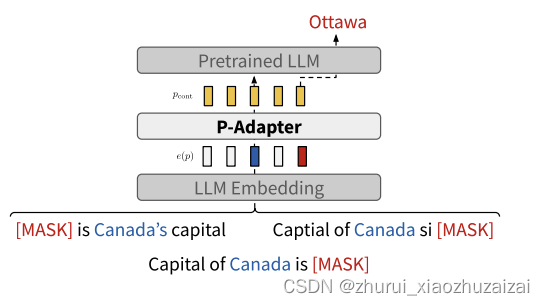
《P-ADAPTERS: Robustly Extracting Factual Information from Language Models with Diverse Prompts》摘要:最近的工作发现,从大型语言模型 (LLM) 中提取的事实信息的质量取决于用于查询它们的提示。这种不一致是有问题的,因为不同的用户会使用不同的措辞查询 LLM 以获得相同的信息,但无论如何都应该收到相同、准确的响应。在这项工作中,作者将通过引入 P-Adapters(位于 LLM 的嵌入层和第一注意层之间的轻量级模型) 来解决这个缺点。他们将 LLM 嵌入作为输入和输出用于查询 LLM 的连续提示。此外,作者研究了学习一组连续提示(“专家”)并选择一个来查询 LLM 的专家混合 (MoE) 模型。它们需要一个在人工标注数据上训练的单独分类器,以将自然语言提示映射到连续的提示。 P-Adapters 在从 BERT 和 RoBERTa 提取事实信息方面与更复杂的 MoE 模型相当,同时消除了对额外注释的需要。与仅使用自然语言查询的基线相比,P-Adapters 的精度绝对提高了 12-26%,一致性绝对提高了 36-50%。最后,作者探索了 P-Adapter 成功的原因,并得出结论,访问 LLM 的原始自然语言提示的嵌入,特别是所询问的实体对的主题,是一个重要因素。
研究问题:基于prompt的方法存在鲁棒性较差的问题,即对于prompt的使用非常敏感,相同语义但是不同表示的prompt也有可能产生不同的结果。因此作者想增强P-tuning的鲁棒性,并从大规模预训练模型中抽取出尽可能多的事实信息。
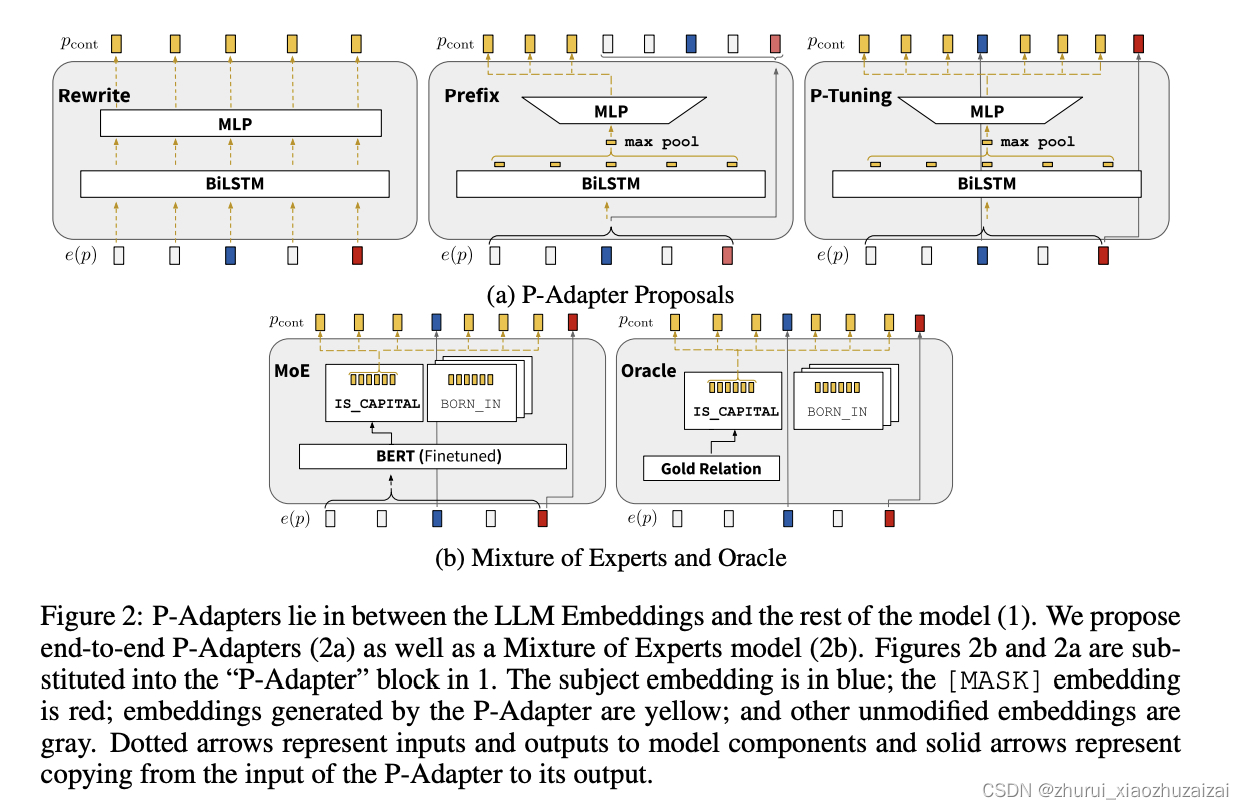
从这个模型图我们可以看出,P-Adapter处于输入的embedding层和LLM之间的一个独立模块,主要就是将输入的原始embedding再映射一下,变成新的连续的embedding,再输入预训练模型进行预测,而具体的P-Adapter的结构可以参见下面的图:
评估指标:
P@1:衡量一个提示是否能提取出事实;
consistency:衡量使用不同的prompt输入是否能得到一致的结果(不一定是正确的结果)