前言
在获取视频时,有的网站是将完整的视频链接路径放在了 <vedio></vedio> 中,但是如果直接将如 mp4 文件放在网页中进行加载,如果视频由于时长、清晰度等原因致使过大,可能会导致视频加载速度很慢,所以现在大部分网站采用流媒体网络传输协议(HLS),将一个视频切成了很多个小段,这样只需要加载 m3u8 文件,根据 m3u8 里的索引进行播放,简而言之如果你拉动进度条到一个时间点,就会加载这个时间点前后的视频片段,速度就会快很多,不过对于视频的爬取也会复杂不少。
HLS 协议
HLS 即 HTTP Live Streaming 是一个由苹果公司提出的基于 HTTP 的流媒体网络传输协议,他把整个流分成一个个小的基于 HTTP 的文件来下载,每次只下载一些,在开始一个流媒体会话时,客户端会下载一个包含元数据的 extended M3U playlist 文件,用于寻找可用的媒体流,m3u8 即编码格式为 UTF-8 的 M3U 文件。
HLS 协议规定视频的封装格式是 ts,所以 m3u8 文件中,是一个 ts 的列表,也就是告诉浏览器可以播放这些 ts 文件,所以将所有的 ts 文件合并起来就可以得到一个完整的 mp4 视频文件。
ffmpeg 的安装
ffmpeg 是一套完备的多媒体支持库,它几乎实现了所有当下常见的数据封装格式、多媒体传输协议以及音视频编、解码器,这里通过他将所有的 ts 文件合并成 mp4 视频文件。
ffmpeg Github 官方下载地址:Releases · BtbN/FFmpeg-Builds · GitHub
我下载的是:ffmpeg-master-latest-win64-gpl.zip,下载之后解压即可,bin 目录以下会生成以下三个文件:

- ffmpeg.exe:音视频转码、转换器
- ffplay.exe:简单的音视频播放器
- ffprobe.exe:简单的多媒体码流分析器
以下及安装成功:
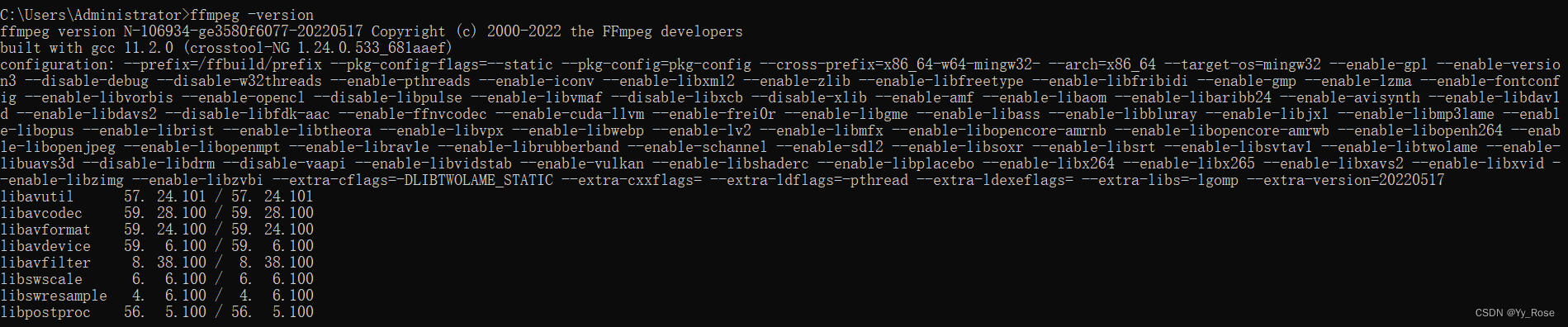
- libavcodec:包含音视频编码器和解码器
- libavutil:包含多媒体应用常用的简化编程的工具,如随机数生成器、数据结构、数学函数等功能
- libavformat:包含多种多媒体容器格式的封装、解封装工具
- libavfilter:包含多媒体处理常用的滤镜功能
- libavdevice:用于音视频数据采集和渲染等功能的设备相关
- libswscale:用于图像缩放和色彩空间和像素格式转换功能
- libswresample:用于音频重采样和格式转换等功能
获取视频
页面分析
视频网页链接:http://www.meijutt.org/fzls/yueyudiyiji/0-1.html

右键点击查看网页源代码,Ctrl + F 检索关键词 <vedio 或者 vedio 会发现检索不到,这里基本可以推测视频是由 m3u8 文件加载出来的,接着 F12 打开开发者人员工具,在 network 中点击 Fetch/XHR 查看网络请求,可以找到 m3u8 文件:

点击打开 m3u8 文件:

- #EXTM3U:每个 M3U 文件第一行必须是这个 tag,提供标示作用
- #EXT-X-VERSION:用以标示协议版本,这里是3, 那么这里用的就是HLS协议第三个版本,此标签只能有0或1个,不写代表使用版本1
- #EXT-X-MEDIA-SEQUENCE:切片的开始序号。每一个切片都有唯一的序号,相邻之间序号 +1。这个编号会继续增长,保证流的连续性,一个 media URI 并不是必须要包含的,如果没有,默认为 0
- #EXT-X-ALLOW-CACHE:是否允许做 cache,这个可以在 PlayList 文件中任意地方出现,并且最多出现一次,作用效果是所有的媒体段
- #EXT-X-TARGETDURATION:指定最大的媒体段(切片)时间长(秒)。所以 #EXTINF 中指定的时间长度必须小于或是等于这个最大,有些 Apple 设备这个参数不正确会无法播放
- #EXTINF: 代表这个 ts 文件的切片时长,一般不超过 10s
- #EXT-X-ENDLIST:表示 PlayList 的末尾了,文件结束符号,表示不再向播放列表文件添加媒体文件,它可以在 PlayList 中任意位置出现,但是只能出现一个
- #EXT-X-PLAYLIST-TYPE:类型,vod 表示点播,live 表示直播
- #EXT-X-KEY:加密
更多 m3u8 参数可参考:m3u8文件参数详解
视频直播与视频点播:视频直播和点播的主要区别
Ctrl + F 检索 m3u8 可以看到 m3u8 文件的路径,并发现其放在 iframe 中,即页面层级嵌套了两个子页面,我们需要的 m3u8 文件路径就放在第二个子页面中,我们需要获取 m3u8 文件的路径然后下载其中的 ts 文件并进行合并,但直接获取网页代码是抓取不到这些内容的,因为直接通过 requests 请求拿到的页面源代码是没经过渲染的,所以拿不到 iframe 里面的内容,这里采用 selenium 提取相关信息:
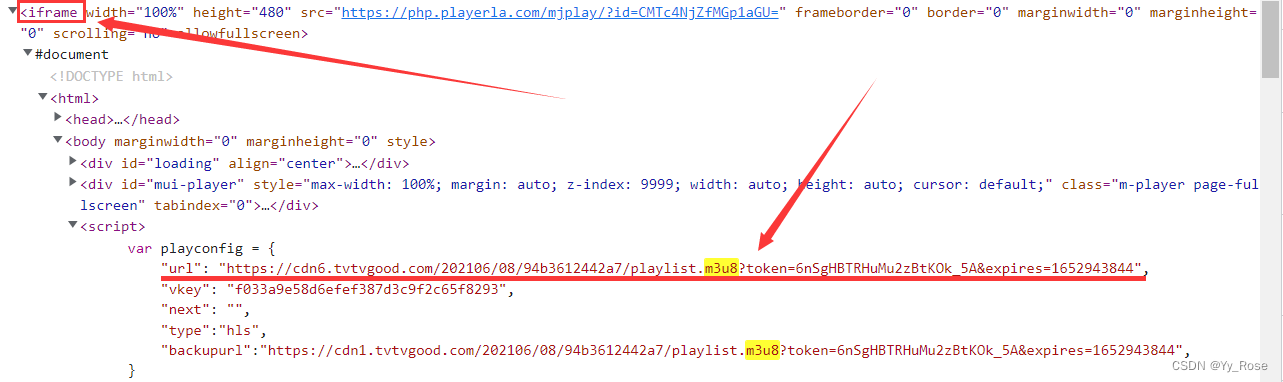
iframe 相关内容可参考:https://blog.csdn.net/Yy_Rose/article/details/121682665
所以基本流程就是:
- 获取 iframe 中源码内容
- 获取 m3u8 地址
- 获取 m3u8 内容
- 下载 ts 文件
- 合并视频文件
获取 iframe 中源码内容
import requests
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver import ChromeOptions
import time
# 浏览器配置
option = ChromeOptions()
option.add_argument("--headless") # 指定无头模式
driver = webdriver.Chrome(options=option)
driver.get(url)
# driver.implicitly_wait(10)
# 等待,避免网页数据没加载完全以至于获取不到
time.sleep(5)
iframe = driver.find_elements(By.TAG_NAME, "iframe")[1]
driver.switch_to.frame(iframe)
time.sleep(5)
# 获取 iframe 中内容
ifm_html = driver.page_source
获取 m3u8 地址
检索 "url":,只匹配到一个数据,即可通过正则对此进行匹配:
re_url = re.compile(r'"url": "(.*?)"', re.S)
# 获取 m3u8 的地址链接
m3u8_url = re_url.findall(ifm_html)[0]
print(f"m3u8 的地址为:{m3u8_url}")获取 m3u8 内容
通过获取到的 m3u8 地址,下载保存其中内容:
# 将 m3u8 写入文件
m3u8_file = requests.get(m3u8_url, headers=headers)
with open('越狱.m3u8', mode='wb') as f:
f.write(m3u8_file.content)
print("m3u8 文件下载完毕")
下载 ts 文件
m3u8 文件中前面不带 # 的为 ts 文件路径,总共有 525 个 ts 文件,由于 ts 文件过多,同步一条条下载会导致速度过慢,这里采用异步下载:
async def download_ts(url, name, session):
async with session.get(url) as resp:
# 创建一个新文件夹 movie_ts 并设置为 excluded,下载过程将不占用 pycharm 缓存
async with aiofiles.open(f'movie_ts/{name}.ts', mode='wb') as file:
# 将下载到的内容写入到文件中
await file.write(await resp.content.read())
print(f"{name} 下载完毕")
async def download_movie():
tasks = []
# 从 m3u8 文件中获取每个 ts 文件的下载地址
async with aiohttp.ClientSession() as session:
async with aiofiles.open('越狱.m3u8', mode='r', encoding='utf-8') as f:
async for line in f:
# 去掉前面带 # 的非 ts 数据
if line.startswith('#'):
continue
# 去掉空格和换行
ts_url = line.strip()
# https://pic.url.cn/qqgameedu/0/d54180feb8f34f6f3eba5cebe6b66107_0/0
# 每个 ts 文件以 d54180feb8f34f6f3eba5cebe6b66107_ 命名
domain = "https://pic.url.cn/qqgameedu/0/"
name = ts_url.strip(domain)
# 创建异步任务
task = asyncio.create_task(download_ts(ts_url, name, session))
tasks.append(task)
# 等待任务结束
await asyncio.wait(tasks)
合并视频文件
ffmpeg 可以将一个 mp4 格式的视频分解成 ts 文件,并生成一个 m3u8 文件:
ffmpeg -y -i movie.mp4 -vcodec copy -acodec copy -vbsf h264_mp4toannexb movie.ts
ffmpeg -i movie.ts -c copy -map 0 -f segment -segment_list movie.m3u8 -segment_time 5 test-%03d.ts
- segment_time: 切片时间,上面设置的每个切片时间为 5 秒
- test-:切片的前缀
- -acodec:使用 codec 编、解码
- -map file:stream:设置输入流映射
- -vcodec codec:强制使用 codec 编、解码方式,如果用 copy 表示原始编解码数据必须被拷贝
- input_streams:记录输入流的信息,在 open_input_file 时初始化里面的部分数据
- output_streams:记录输出流的信息,当 ffmpeg 选项为 -c copy 时,会在 init_output_stream_streamcopy 函数中将输入流的编解码信息拷贝给输出流
ffmpeg 可以分解 mp4 文件为一个个 ts 文件,自然也可以使用它将 ts 切片合并成一个完整的 mp4 文件:
将 ts 文件路径写入 txt 文档中,格式例如:
file G:/Python/m3u8/merge/1a0de66077eab0eea7aa9251a9deded4_.tswith open("越狱.m3u8", mode='r', encoding='utf-8') as f:
with open("file.txt", mode='w', encoding='utf-8') as file:
for line in f:
if line.startswith('#'):
continue
line_ts = line.strip()
domain = "https://pic.url.cn/qqgameedu/0/"
ts_name = line_ts.strip(domain)
# 更改路径
ts_path = f"file G:/Python/m3u8/merge/{ts_name}.ts"
file.write(ts_path + "\n")
file.close()
print("保存完毕!")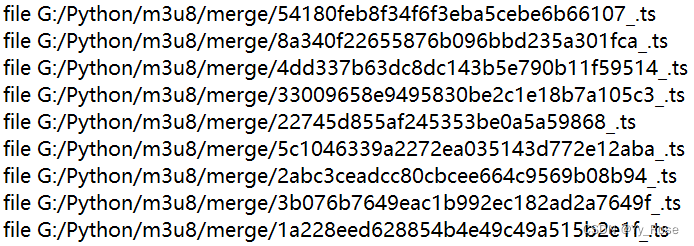
# -safe 0: 防止 Operation not permitted
ffmpeg -y -f concat -safe 0 -i file.txt -strict -2 prison.mp4
ffmpeg -y -f concat -safe 0 -i file.txt -c copy prison.mp4
# 网上还有不少拼接方法 - -f:输出格式
- -y:覆盖输出文件,即如果 prison.mp4 文件已经存在的话,直接覆盖掉
- -i::输入文件的名字
- concat:合并视频
报错解决:
[concat @ 000001935d022e80] Unsafe file name 'G:/XX/XX/XX/X.ts'
file.txt: Operation not permitted
解决办法:加上 -safe 0
[mp4 @ 0000022fe210adc0] Could not find tag for XXX in stream #0, codec not currently supported in container
Could not write header for output file #0 (incorrect codec parameters ?): Invalid argument
Error initializing output stream 0:0 --
解决办法:加上 -strict -2 或者 -acodec aac,表示 aac 音频编码
ts 文件被混淆为图片
但我这里 XXX 处显示为 codec bmp,bmp 为位图(点阵图),证明视频被 ffmpeg 解析为了图片,ffmpeg 无法进行拼接,用以上解决方法可以拼接出 mp4 视频文件,但无法播放,所以可以看出 ts 文件后缀被批量修改为 bmp 了,这应该就是为什么将文件后缀改为 ts 可以播放视频,但是无法使用 ffmpeg 进行拼接的原因,文件路径用 Chrome 打开也显示为图片样式:
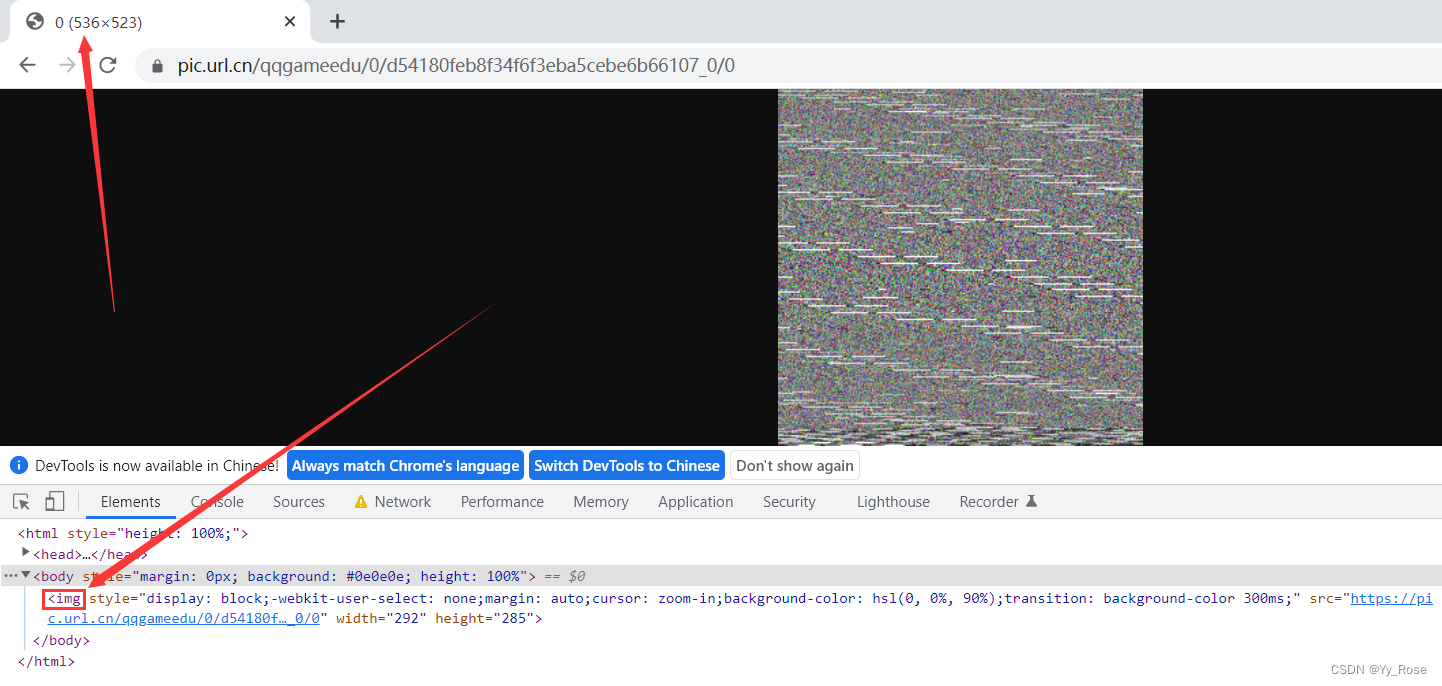
每个 0 即为 ts 片段,content-type:image/bmp,即证明观点,为 bmp(BitMap)格式图片文件:

BMP、PNG、JPG 格式图片的区别:BMP GIF PNG JPG等图片格式的区别和适用情况
- BMP:文件体积大,较老的图片格式
- PNG:文件体积小,较新的图片格式
二进制文件通过 Notepad++ 的 Hex-Editer 插件可以看到,42 4d 表示为 BM,正常的 ts 文件是以红圈位置为开头的:
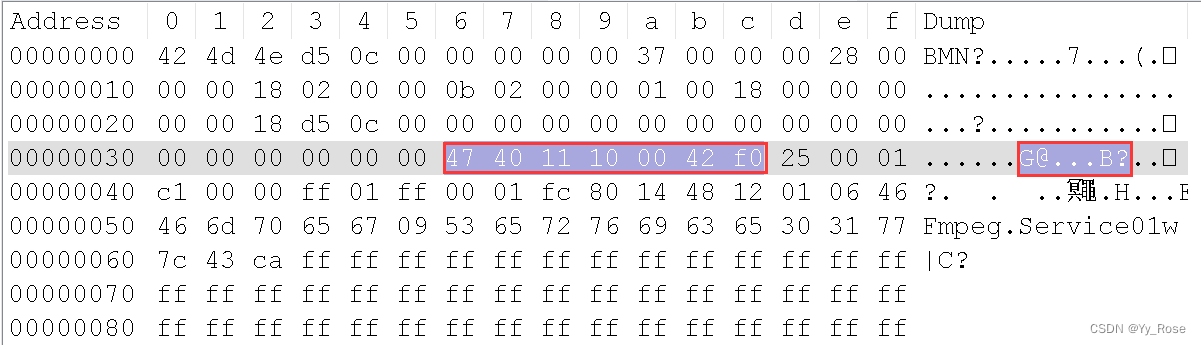
所以将其之前的 delete 后保存即可,或者只删掉 42 4d,再用以下命令即可成功将 ts 合成为 mp4 视频:
ffmpeg -y -f concat -safe 0 -i file.txt -c copy prison.mp4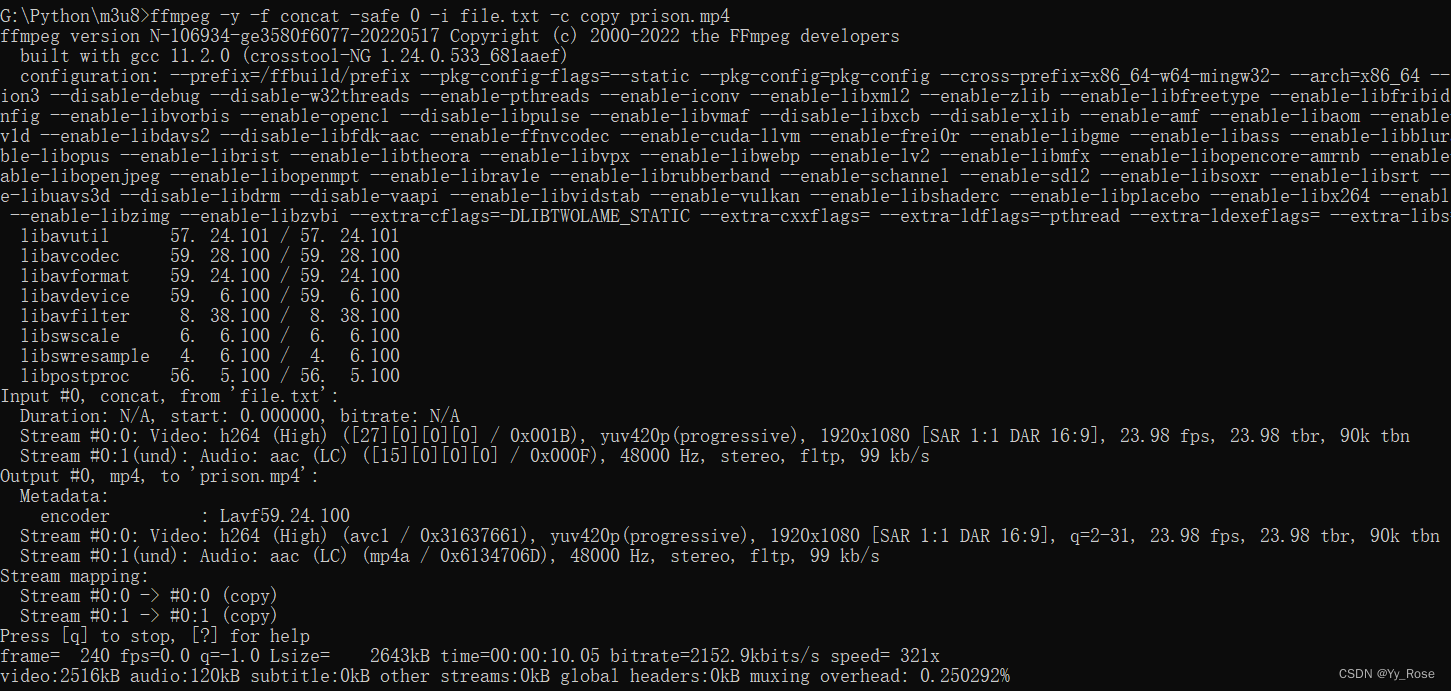
用了两个 ts 片段进行测试,没报错,合并成功,并且能够正常播放视频!!!
ffmpeg 使用可参考:https://blog.csdn.net/matthew0618band/article/details/9830681
总结
以上是对 m3u8 视频文件获取的实战归纳总结,以及 ts 被混淆为图片的解决办法,PNG 格式图片与上述 BMP 格式图片处理方法基本一致,如有见解欢迎评论区或私信指正交流~
参考资料:
https://blog.csdn.net/davidullua/article/details/120562737
https://blog.csdn.net/weixin_43841155/article/details/122229315
https://blog.csdn.net/qq_33697094/article/details/112718101