前言 LiDAR 语义分割通过直接作用于传感器提供的原始内容来完成细粒度的场景理解而受到关注。最近的解决方案展示了如何使用不同的学习技术来提高模型的性能,而无需更改任何架构或数据集。遵循这一趋势,论文提出了一个从粗到精的设置,该设置从标准模型派生的分类错误 (LEAK) 中学习。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。

论文:https://arxiv.org/pdf/2301.11145.pdf
论文出发点
目前点云语义分割最先进的解决方案通常建立在自动编码器架构或完全卷积模型之上,其内部结构在很大程度上取决于任务和所处理数据的属性。由于点云的稀疏性和不规则分布,处理LiDAR数据进行语义分割存在一些挑战。现有的架构没有配备自我规范化的类条件策略来进一步改善模型训练,它们在没有细化的情况下学习概念。最近的工作利用身体边缘特征、自我监督的深度估计或伪标签,并且不执行任何从初步的类别条件准确性估计的自适应自我正则化。
在本文中,作者提出了LEAK(Learning from mistakes),一种新颖的从粗到细的学习策略,通过分类错误、类原型和类不平衡自动驱动的训练过程,优化语义分割网络的性能。
主要贡献
(1)本文提出了一个通用的语义分割框架,适用于不同的实验场景;
(2)通过谱聚类检查标准模型的混淆分数来识别宏类别中语义一致的类别划分;
(3)设计了一个层次感知的公平性约束来平衡分类分数,而不考虑每个类的频率或准确性;
(4)计算类条件原型,这些原型在其原型表示周围强制执行特征的正则化约束;
(5)在不同的标准点云和 RGB 语义分割数据集上对本方法进行了基准测试,其性能优于最先进的架构。
方法
整体结构
本文的整体架构如图2所示。首先谱聚类应用于从标准预训练模型推断的混淆矩阵,在类集上获得的层次划分在输出的公平性目标中使用,对由任何现成的分割模型执行的标准监督学习的结果进行分析。然后在微观和宏观层面构建原型。通过这种方式,模型通过采用语义驱动的自正则化方法从错误中学习,并获得相对于标准解决方案的整体改进。
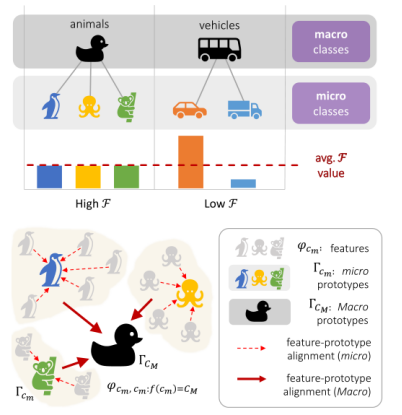
图1. 识别微类(例如,汽车和卡车)的语义宏观社区(例如,车辆),自动分析任何语义分割模型的准确性结果。

图2. LEAK整体结构。
从错误中学习
LEAK 的第一个构建块是基于从错误中学习的相互语义错误分类的自正则化策略的有效核心。采用预训练的标准分割模型来推断验证集的预测,计算类别的混淆矩阵。该矩阵 A 被视为与完整图网络 G 关联的邻接矩阵,其中将不同的类别分配给节点,条件错误概率是边权重。用{ci}, i ∈ [0, m)来标识 G 的节点,其中m是类的总数,用{di,j}, i, j ∈ [0, m),其中i , j分别表示ground truth 和predicted class index。边di,j与将真实类别ci分类到预测类别 cj 的概率相关联。使用此表示通过聚类算法绘制社区中的细分,识别M个聚类,由{Ci}, i ∈ [0, M)定义。
具体来说,这种划分是通过通常用于根据连接节点的边来识别图中节点社区的谱聚类来执行的。邻接矩阵 A 作为输入提供,由对数据集中每对点的相对相似性的定量评估组成。该算法遵循一个迭代过程,该过程利用相似性矩阵的特征值进行降维,并逐步将网络细分为两个集群,直到达到最佳社区数量。该数字是先验估计的,其中最佳簇数对应于局部最小值的数量。在此步骤中找到的社区代表类的宏观分组。图 2 左侧直观地展示了谱聚类算法对图和混淆矩阵带来的影响。
每种颜色对应于属于同一集群(即宏类)的一组节点(即微类)。图 1 左侧的树结构是用这种方法自下而上导出的,并显示了类的层次结构,具体如图3所示。

图3. SemanticKITTI 中类的分层后验类。
功能原型对齐
原型(即类质心)是特征空间中不可学习的向量,代表数据集中出现的每个语义类别,并在监督下的每个训练步骤更新运行平均值。在训练步骤t中,批次B的B个总样本,原型被更新为通用类 c 为:
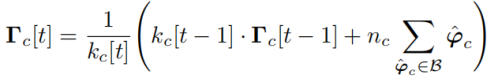
其中^ϕc为当前 batch B中对应c类的特征向量,kc[t]为之前所有batch中遇到的c类对应的特征向量个数,nc 为当前 batch 中对应c类的特征向量个数批次B。因此,kc[t] = kc[t − 1] + nc 其中 kc[0] = 0。
然后,聚合具有相同语义类c的特征以帮助构建原型Γc。类原型被初始化为Γc[0] = 0 ∀c ∈ [0, m)。使用 l1 范数 || · ||1 作为公制距离。损失函数定义为:
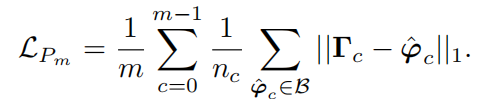
公平加权
为了加强特征原型对齐的正则化效果,引入了一种细心的每类加权方案。该约束源自实验观察,即每个类的点数对该类的分类精度有显着影响。在许多实际应用中,出现频率最低的类别是最关键的类别(例如,汽车场景中的人)。本文提出了一个源自Jain’s fairness指数F的正则化目标,以提供平衡的每类权重。换句话说,这解决了每个宏类中的资源分配问题,考虑属于同一宏类的微类与共享相同资源的用户:
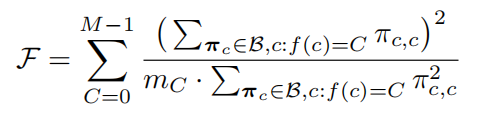
其中 mC是宏类C中(微)类的数量,πc,c表示向量πc中的第c个元素,πc 是类c的平均预测向量,获得如下:

其中 pc是具有真实类别c的通用预测向量,¯nc是当前批次B中标记为c的点数。高公平值表示实体之间的资源分配真正平衡,而低公平值表示资源分配不平衡(图 1 上部)。因此,为了保持类间精度的同质性,设计了一个基于公平性的损失函数,如下所示:
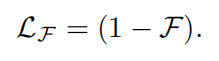
目标函数
训练目标由每个架构(L0)的基本损失函数与LEAK组件给出的附加目标的组合给出。基本损失函数取决于所选架构。它对应于RandLA-Net和RangeNet++的具有逆类权重的标准交叉熵损失,对应于体素特征的 Lovaszsoftmax损失加上点特征的逆类权重的交叉熵损失Cylinder3D中的细化,以及 DeepLabV3的普通交叉熵损失。
LEAK 组件由微观级别 (LPm) 和宏观级别 (LPM) 特征原型对齐目标以及类注意权重约束 (LF) 给出。然后将完整目标计算为:
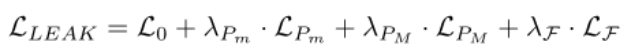
实验及结果
本文使用三个点云数据集和一个图像数据集对公开可用的基准进行实验,分别是SemanticKITTI、S3DIS、Semantic3D和PascalVOC2012数据集。
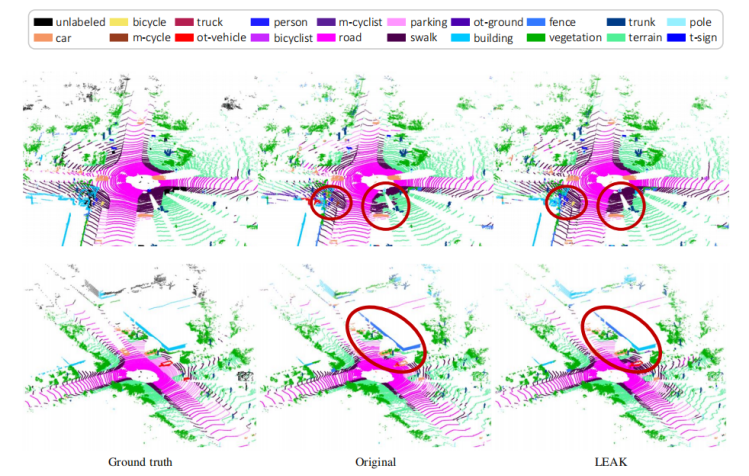
图4. 使用或不使用LEAK训练的RandLA-Net的定性结果(最相关的改进用红色圆圈突出显示)。
表1. SemanticKITTI数据集上的每类 IoU。†:为了公平比较,从官方代码库重新训练的模型。粗体表示与基线相比最佳。
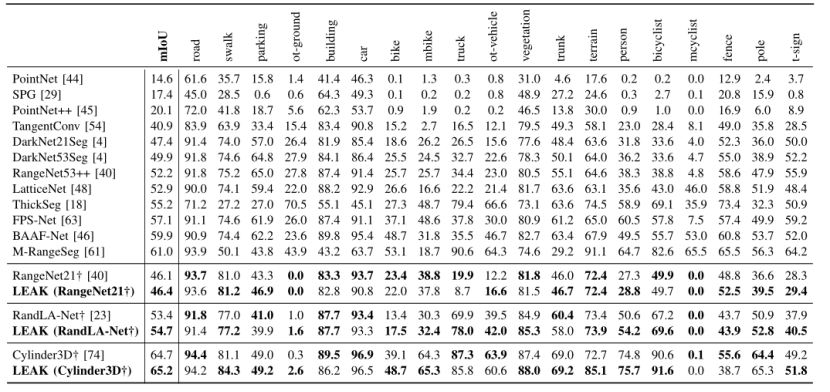
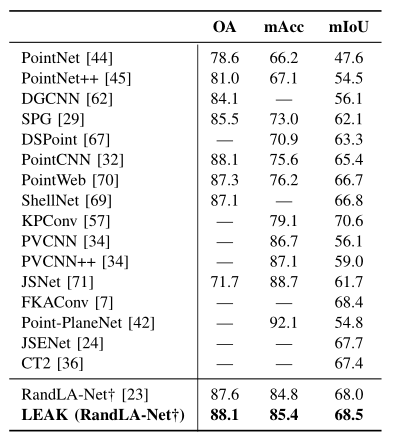
表2. 使用 RandLA-Net在S3DIS数据集(6 折交叉验证)上的定量结果。
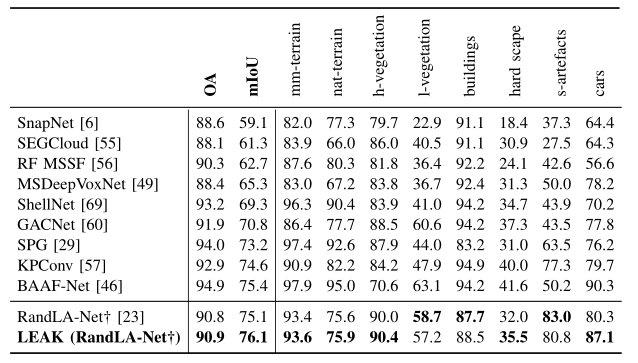
表3. 使用 RandLA-Net在S3DIS数据集(6 折交叉验证)上的定量结果。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:444129970。群内有大佬负责解答大家的日常学习、科研、代码问题。
模型部署交流群:732145323。用于计算机视觉方面的模型部署、高性能计算、优化加速、技术学习等方面的交流。
ECCV2022 | 重新思考单阶段3D目标检测中的IoU优化
Vision Transformer和MLP-Mixer联系和对比
从零搭建Pytorch模型教程(三)搭建Transformer网络
从零搭建Pytorch模型教程(四)编写训练过程--参数解析
从零搭建Pytorch模型教程(五)编写训练过程--一些基本的配置
从零搭建pytorch模型教程(八)实践部分(一)微调、冻结网络
从零搭建pytorch模型教程(八)实践部分(二)目标检测数据集格式转换