二叉树是非常基础的数据结构,二叉树的遍历是对二叉树的基本操作,今天对常见的二叉树遍历算法进行总结。
一 、二叉树基本概念
二、二叉树广度优先原则遍历
对于一颗二叉树,深度优先搜索(Depth First Search)是沿着树的深度遍历树的节点,尽可能深的搜索树的分支。
又可根据对根节点的访问次序分为前序遍历,中序遍历和后序遍历。
-----------------------------------------递归方法实现对二叉树的广度优先遍历--------------------------------------------------
因为树的定义本身就是递归定义,因此采用递归的方法去实现树的三种遍历不仅容易理解而且代码很简洁。
1. 前序遍历(递归)
首先访问当前节点,然后遍历左子树,最后遍历右子树。
对于下面的二叉树,前序遍历结果如下:

结果:[10,5,15,6,2]。
从遍历算法的描述上明显有递归的思想。先访问当前节点,然后遍历左子树,二遍历左子树又是先访问当前节点,然后.....
最好递归停止的条件为访问的当前节点为空返回空。
代码如下:
def preTrav(pHead): #pHead 为二叉树根节点
if pHead == None:
return
print(pHead.val)
preTrav(pHead.left)
preTrav(pHead.right)
2. 中序遍历(递归)
首先遍历左子树,然后访问当前节点,最后遍历右子树。
对于下面的二叉树,中序遍历结果如下:
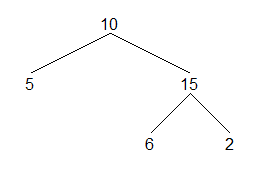
结果:[5,10,6,15,2]
代码如下:
def midTrav(pHead): #pHead 为二叉树根节点
if pHead == None:
return
midTrav(pHead.left)
print(pHead.val)
midTrav(pHead.right)
3. 后序遍历(递归):
首先遍历左子树,然后遍历右子树,最后访问当前节点。
直接贴代码:
def behTrav(pHead):
if pHead == None:
return
preTrav(pHead.left)
preTrav(pHead.right)
print(pHead.val)
---------------------------------------------利用栈的性质来实现非递归遍历二叉树----------------------------------------------------
利用栈实现二叉树的先序,中序,后序遍历的非递归操作,栈是一种先进后出的数据结构,其本质应是记录作用,支撑回溯(即按原路线返回);因此,基于其的二叉树遍历操作深刻的体现了其特性:
1. 若后续的输入和其前面的输出没关系,则可以一直入栈,只能无法再入时才停止入栈,如二叉树遍历;若前面的输出是后面的输出有关系,则不可以这样,如快速排序,其分割位置需要前面的输出支撑,则需要计算和入栈交替进行。
2. 先入、后出,只有不能再进入时才能出栈
3. 对于栈中的某一元素而言,需要判定其是否满足出栈条件:当回溯至栈中某一点时,后续入栈元素是否和其还有关系。如先中遍历,当回溯至某一点时,后续入栈的点已经和其没关系故出栈,然而后序遍历中其却和其后续入栈的点有关系,因此,做“已经二次访问标记”即可,也就是判断是否还需要其的记忆作用,也就是还需要第三次访问它。因此,回溯时,当不需要其记忆时则让其出栈,否则,对其做再次访问标记,这就是需要对从栈中弹出条件进行设定与判断,比如,先序、中序遍历的符合前者,后序符合后者。
4. 前序遍历(非递归):
根据前序遍历访问的顺序,优先访问根结点,然后再分别访问左孩子和右孩子。即对于任一结点,其可看做是根结点,因此可以直接访问,访问完之后,若其左孩子不为空,按相同规则访问它的左子树;当访问其左子树时,再访问它的右子树。因此其处理过程如下:对于任一结点P:
1)访问结点P,并将结点P入栈;
2)判断结点P的左孩子是否为空,若为空,则取栈顶结点并进行出栈操作,并将栈顶结点的右孩子置为当前的结点P,循环至1);若不为空,则将P 的左孩子置为当前的结点P;
3)直到P为NULL并且栈为空,则遍历结束。
代码如下:
def preTravStack(pHead): #pHead 为二叉树根节点
stack = [] #用list内置的apennd(),pop()方法来模拟出栈如栈
p = pHead
while p or stack != []:
while p:
print(p.val)
stack.append(p)
p = p.left
p = stack.pop()
p = p.right
4. 中序遍历(非递归):
根据中序遍历的顺序,对于任一结点,优先访问其左孩子,而左孩子结点又可以看做一根结点,然后继续访问其左孩子结点,直到遇到左孩子结点为空的结点才进行访问,然后按相同的规则访问其右子树。因此其处理过程如下:对于任一结点P,
1)若非空,则将P入栈并将P的左孩子置为当前的P,然后对当前结点P再进行相同的处理;
2)若为空,则取栈顶元素并取出栈顶元素置为P,并访问;
3)若P的右孩子为空,取出栈顶元素置为P;
4)若P的右孩子不为空,将P的右孩子置为当前得P,重新由1)开始循环
3)直到P为NULL并且栈为空则遍历结束。
def midTravStack(pHead):
stack = []
p = pHead
while p or stack != []:
while p:
stack.append(p)
p = p.left
p = stack.pop()
print(p.val)
while p.right == None and stack != []:
p = stack.pop()
p = p.right
4. 后序遍历(非递归):
三、 二叉树的广度优先遍历
广度优先遍历的核心思想如下:从根节点开始遍历,优先遍历其子节点,再从左至右的,依次遍历其孙子节点的,以此类推,直到完成整颗二叉树的遍历。
如对下图二叉树的广度优先遍历结果:
广度优先遍历(BFS):[10, 5, 15, 6, 2]
在代码中,我们使用队列进行广度优先遍历,先把根节点放入队列,利用队列的先进先出原则,访问队列中取出的节点,并分别把左子节点和右子节点放入队列,循环下去,直到队列为空。
对根节点,先把根节点放入队列
1)取出队顶元素置为q, 并访问;
2)若q的左孩子不为空,放入队列;
3)若q的右孩子不为空,放入队列;
4)循环1)-3)直到队列为空。
代码如下:
def PrintFromTopToBottom(root): #root为二叉树根节点
# write code here
ls = [] #存放遍历的节点值
q = queue.Queue()
if root == None:
return []
q.put(root)
while not q.empty():
node = q.get()
ls.append(node.val)
if node.left != None:
q.put(node.left)
if node.right != None:
q.put(node.right)
return ls