Go程序Panic在生产环境很容易引起事故。尤其是新人编写的代码,因为对语言不熟悉,常会有些小漏洞。
如何尽早发现呢?除了做好代码review、做好测试外,在panic发生时,能够及时报警,找到责任人,也有很大帮助。
如果不单独监控panic,确实有些辅助办法能够发现问题。如果系统大量报502,一般是服务挂了。或者通过QPS降低、请求错误量提升,触发报警。但这种辅助方法都不及时,而且很难帮助开发者快速定位问题。
监控系统
监控系统组成如下:
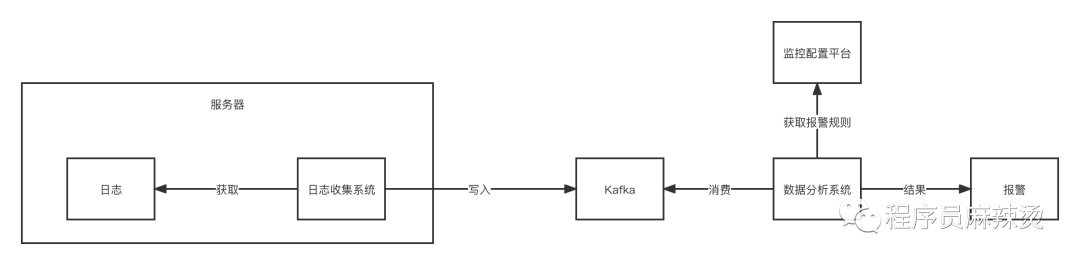
服务器上有日志收集系统,定时获取日志。
日志收集系统将日志信息传送给Kafaka,数据分析系统对日志进行分析,具体分析规则从监控配置平台拉取,如果超出指定阈值进行报警。
这种方案监控httpcode或接口返回的code码。panic错误只有错误栈,不会有指定code,所以无法报panic事件。
监控panic
鉴于上面的问题,公司有个同学做了一个定位小助手,堪称神器,大部分团队已接入该助手。此处讲一下核心设计原理。
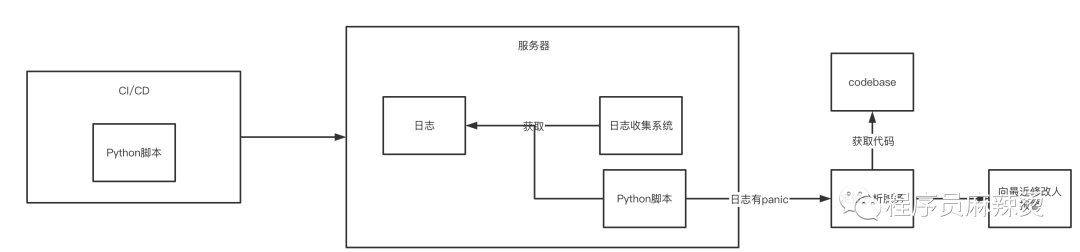
作者通过介入公司的CI、CD过程,将Python脚本在Go服务部署时,同时部署到服务器上。Go服务启动时,Python脚本也会执行后,定时获取指定日志内容:
cmd = "tail -c +{offset} '{path}' | head -c {read_size} | grep '{pattern}' -B 10 -A 50 > '{tb}'".format( offset=offset, path=log_path, read_size=read_size, pattern=self.grep_pattern, tb=tb_file)
如果日志中有panic字样,会将这段日志发送给定位分析服务。
定位分析服务于代码库打通,根据错误栈中的内容,可以找到每行代码的修改时间,最近一个修改即为引入panic的负责人。
通过这个方案,准确快速的发现了大量问题。
总结
虽然监控panic讲述的很简单,但是要做好还是有一定难度的。一是需要对CI/CD的过程比较了解,二是在服务器部署新的日志收集系统,一定不能影响到服务器稳定性,这就需要做好限制。
小助手做的很好的一点是和代码库打通,能够帮开发者迅速定位修改人、修改位置,这个太有用了。
我很赞赏这种通过发现一个问题,然后用产品化思维解决问题的人。
当然,最好的方案还是这个功能能够合并到日志收集系统中。但有时候,一个系统要在大而全和专注之间做选择。
最后
大家如果喜欢我的文章,可以关注我的公众号(程序员麻辣烫)
我的个人博客为:https://shidawuhen.github.io/
往期文章回顾: