注:本文要解决的问题是,简单的用户嵌入无法有效建模用户兴趣,采用的方法是对:用户嵌入(整体兴趣),物品级表示(细粒度,根据分析用户的历史观看记录,来推测未来兴趣), 类别级表示(粗粒度),邻居辅助(协同过滤)四种表征就行融合。最后的实验效果显示:可发现早期融合中最复杂的注意力融合方法并不是最优。
Abstract
众所周知,深度学习在自动生成表征方面非常有效,这消除了人工制作特征的需求。对于个性化推荐任务,通过深度学习来生成多媒体(尤其是图像和视频)的有效表示取得了巨大的成功。以前的工作通常采用简单的、单一的模态表示用户兴趣,例如用户嵌入,这无法完全表征用户兴趣的多样性和波动性。为了解决这个问题,在本文中,我们专注于利用深度网络来学习和融合多种用户兴趣表示。具体来说,我们考虑了用户兴趣的四个方面的有效表示:首先,我们使用潜在表示,即用户嵌入,来分析整体兴趣;其次,我们提出了物品级表示,从用户历史项目的特征中学习并整合;第三,我们研究邻居辅助表示,即使用相邻用户的信息来协同表征用户的兴趣;第四,我们提出了类别级表示,这是从用户历史项目的分类属性中学习的。为了整合这些多用户兴趣表示,我们研究了早期融合和晚期融合;对于早期融合,我们研究不同的融合函数。我们分别在短视频和电影推荐的两个真实视频推荐数据集上验证了所提出的方法。实验结果表明,我们的方法明显优于现有的现有技术。
I. INTRODUCTION
个性化推荐算法通常分为三类:协同过滤(CF),基于内容的过滤(CBF),混合方法。CF分析多个用户的交互数据,而不依赖内容,因此存在冷启动问题。CBF通过利用项目的内容特征来摆脱这个问题,但CBF的性能取决于内容特征的有用性。混合方法提出去结合CBF和CF等非个性化推荐算法的优势,并且这种方法在工业推荐系统中被广泛采用。
近年来,随着深度学习的成功,传统的内容特征(例如颜色,视觉文字)已被各种深层特征(例如基于CNN的特征)所取代,这些特征改善了图像/视频的表示。事实上,在不需要特征工程的情况下,自动生成表示是深度学习本身最重要的优势之一。它对于非结构化多媒体数据(包括音乐、图像和视频)特别有用。从另一个角度来看,用户特征表示在推荐系统中也非常重要。虽然项目的属性相对静态,但用户的兴趣通常是动态的,分析起来要复杂得多。然而,以前的工作通常忽略了这个问题,他们采用了简单的、单一的模态表示用户兴趣,例如深度方案中的用户嵌入。用静态的、固定长度的向量表示用户,可能无法完全表征用户兴趣的多样性和波动性。最近,一些研究以深度学习来丰富用户的兴趣表示。例如,Gao等人提出了一个动态递归神经网络(RNN)来模拟用户随时间变化的动态兴趣。Chen等人提出了两个注意力模型,它们在协同过滤框架中表征用户在组件和项目级别的兴趣。在我们之前的工作中,我们提出了一个类别和项目级别的时间层次注意力模型,以捕捉用户对微视频点击预测的动态兴趣。
在本文中,我们利用深度网络对视频推荐的用户兴趣表示进行了全面研究,如图1所示,除了用户嵌入之外,我们还使用网络从用户的历史访问物品中识别用户的动态兴趣,这称为物品级兴趣表示。当我们将这种物品级表示与更广泛使用的用户嵌入进行比较时,我们注意到前者是细粒度描述,后者是整体描述。因此,它们代表了两个极端。在这两个极端之间,我们提出了一个类别级的特征表示(区分物品所属类别)。具体来说,我们预定义一组类别,并将每个物品分配给一个或多个类别。然后对于每个用户,我们有一个根据他/她的历史交互项目计算的类别分布向量,然后将其输入一个神经网络的得到类别级表示。事实上,类别级别的表示是对用户兴趣的粗粒度描述。虽然项目和类别级别的表示侧重于个性化方面,如CBF,但我们另外考虑协作方面。也就是说,我们找到与给定用户相似的用户(称为邻居),并使用网络从邻居的信息中生成兴趣表示。这被称为邻居辅助表示,它受到基于用户的 CF 的启发。 总之,我们研究的四种用户兴趣表示在不同粒度上涵盖了用户兴趣的不同方面。我们融合了CBF和CF以往的智慧进行个性化推荐。
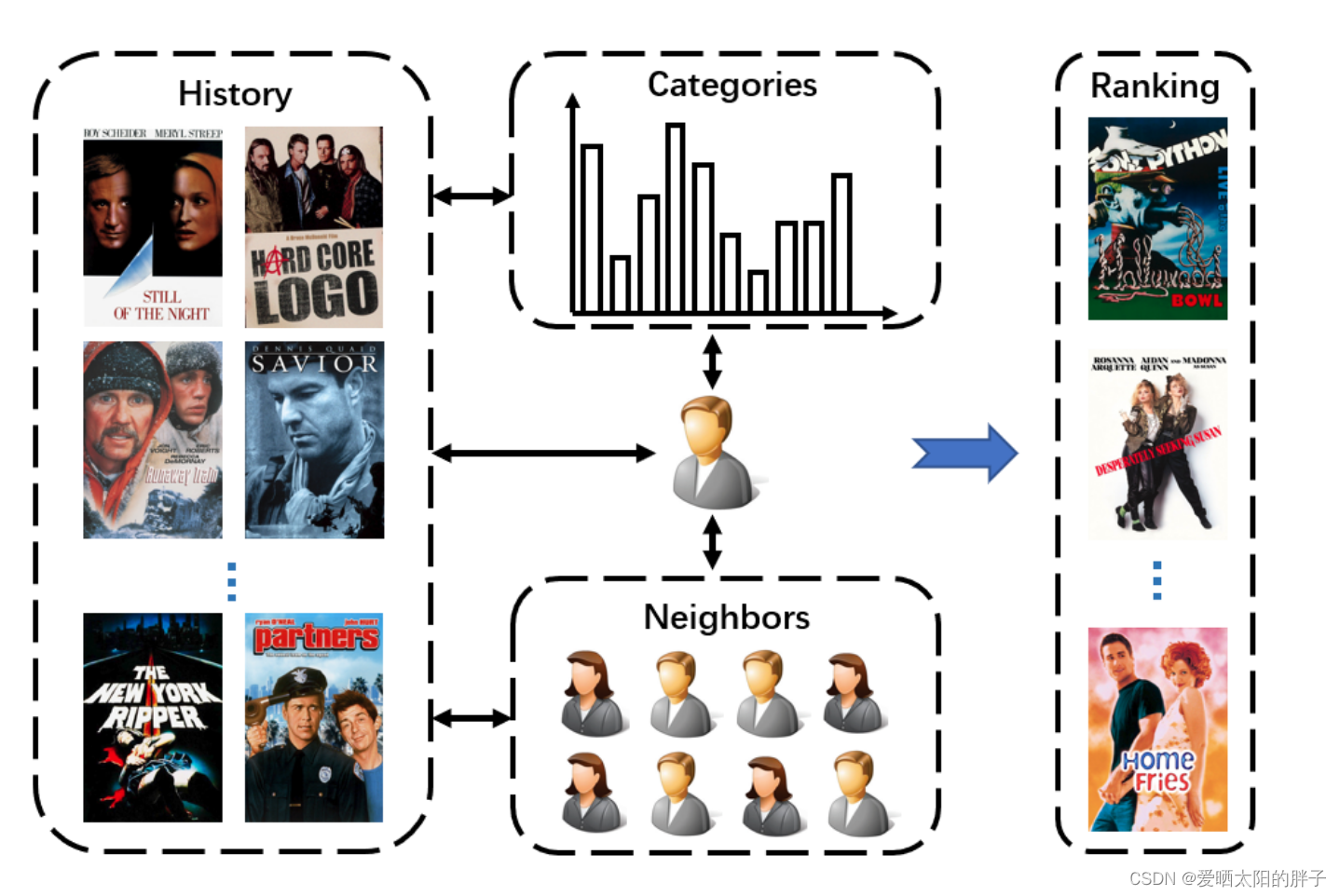
对于多个用户兴趣表示,以下问题是如何在整体框架中利用它们。在本文中,我们研究了两种策略:早期融合(EF)和晚期融合(LF),对于EF,我们还研究了不同的融合函数。因此,我们提出的方法使用基于深度学习的框架来学习和融合多用户兴趣表示(MUIR),以实现个性化的视频推荐。
contributions
- 我们对不同类型的用户兴趣表示进行了系统性研究。据我们所知,我们是第一个将邻居辅助表示用于视频推荐的。
- 我们研究一个完整的框架,用于学习和融合多个用户兴趣表示。特别是,我们研究了不同的融合策略和不同的融合函数。
- 我们分别在短视频和电影推荐的两个真实数据集上进行实验。尽管这两个数据集在分布方面有很大不同,但我们观察到一些一致的结果,证明了我们提出的方法的有效性。
II. RELATED WORK
A. Video Recommendation
现有的视频推荐方法可分为协同过滤、基于内容的过滤以及混合方法。关于CF方法,例如,Baluja等人提出通过各种图形,传播偏好信息以提供个性化的视频推荐。Huang等人提出了一种基于矩阵分解的可扩展在线CF算法,该算法具有可调整的更新策略,以考虑来自不同用户操作的隐式反馈。CF方法存在冷启动问题,即推荐系统无法推荐以前未进行过用户交互的新物品。为了克服这一限制,CBF方法通过基于对视频内容(包括音频和视觉提示、字幕、标签和其他内容特征)的分析,评估项目之间的相似性/相关性,推荐与用户历史上访问的视频相似/相关的新视频。例如,Mei等人提出了一个基于多模态内容相关性和用户反馈的上下文视频推荐系统。Deldjoo等人通过从视频中提取一组具有代表性的风格特征(包括照明,颜色和运动)提出了基于内容的推荐系统。CBF 方法的性能依赖于视频内容功能的有用性。一些混合方法将CF和CBF组合到一个框架中。例如,Zhao等人提出了一种多任务排名聚合方法,该方法将视频推荐定义为排名问题,并通过探索不同的信息来源生成融合多个排名列表。Liu等提出了一种共注意力网络,用于学习多模态信息的个性化微视频推荐。
现有大多数基于内容的视频推荐方法侧重于如何丰富项目表示,并计算视频与用户历史交互视频之间的相似性。在本文中,我们重点介绍了如何丰富用户兴趣的表征,并提出了一个深度模型来学习视频推荐的多个用户兴趣表示。
B. User Interest Representation
用户兴趣表示的传统方法是嵌入,这在潜在因子模型中被广泛使用。最近,注意力机制已被应用于计算机视觉,神经语言处理和推荐系统中的各种问题。Chen等人将多级注意力(即项目和组件级注意力)引入CF框架,用于图像/视频推荐,这是SVD++的扩展。在这个框架中,他们在邻域模型中用可调整的注意力权重替换了静态归一化权重。Zhou等人提出了一个深度兴趣网络(DIN),通过设计一个本地激活单元来自适应地从历史行为中学习用户兴趣的表示,以进行点击预测。我们之前的工作提出了一个类别和项目级别的时间层次注意力模型,该模型将用户的历史行为划分为多个块,以捕获微视频点击预测的长期和短期兴趣。上述方法侧重于如何分析用户的兴趣,但很少有人关注如何有效地融合多种表示。以 SVD++ 为例,它们直接采用求和运算来组合用户嵌入和历史项目的嵌入。我们认为,简单的求和运算可能不足以融合不同类型用户表示的信息。因此,在本文中,我们通过探索何时以及如何融合它们来研究如何有效地融合多个用户兴趣表示。
III. LEARNING MULTIPLE USER INTEREST REPRESENTATIONS
A. Item Representation
与用户兴趣相比,项目属性相对静态,这使得我们可以考虑视频的静态表示。由于本研究的重点是用户兴趣表示,因此我们不太关注项目部分。然而,先进的项目表示方法一定可以集成到我们的框架中。
对于每一个视频,从它的内容中提取出视觉特征
,视觉特征维度可能很大,论文用矩阵
将其投影到了低维空间:
视频视觉特征: where
此外论文还考虑了种类特征,每个视频属于一个或多个种类,用one-hot或multi-hot编码
表示,代表视频类别数量,并用矩阵
将其投影到低维空间。
视频类别特征: where
视频特征: where
B. Latent Representation
用户嵌入广泛用于基于深度网络的推荐系统中,它使用静态向量来表示用户的整体兴趣。用户Embedding()在模型训练期间学习,
,其中
代表用户i的潜在表示,N代表用户的数目,d代表嵌入维度。
C. Item-Level Representation
潜在表示对于给定用户来说是静态的,提供对用户兴趣的整体分析。在对用户兴趣进行细粒度分析时,我们可能希望查看用户的历史观看记录,以推断未来的兴趣。
这一部分的目的是通过学习的方法利用注意力机制从用户的历史交互序列中得到用户物品级表示。
用户的历史交互序列为
,
,
表示用户观看视频的数量。第m个视频
对应的视觉特征向量为
,用矩阵
来降低其为度 :
用户i观看序列中视频m将降维视觉特征向量: ,
,所以我们可以使用
从物品的角度描述用户的兴趣。
用户i的物品级表示为:
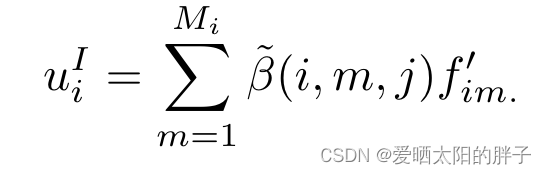
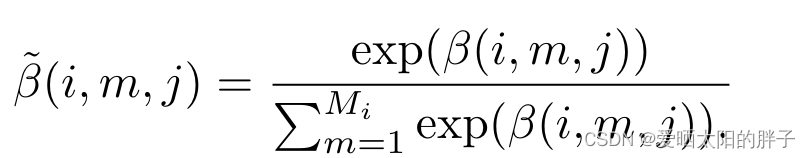
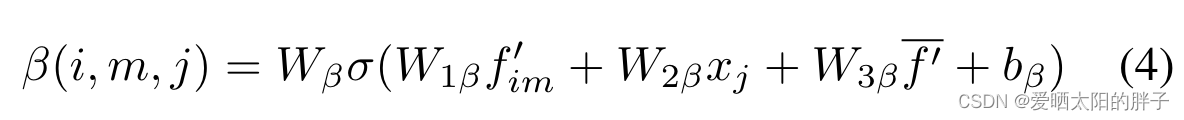
:用户i的观看序列中的第m个视频在候选视频j时的注意力分数。
: 用户i的观看序列中的第m个视频的视觉特征向量。
:候选物品特征(物品特征=视觉特征+类别特征)。
:用户历史序列中的所有视觉特征向量的平均值。
激活函数是sigmoid
D. Category-Level Representation
对于用户的每个历史交互物品都有一个分类向量(one-hot/multi-hot),用户i的所有交互物品构成集合,通过这个集合可以得到分类分布向量
,同样通过嵌入矩阵
将其投影到低维度
, where
。
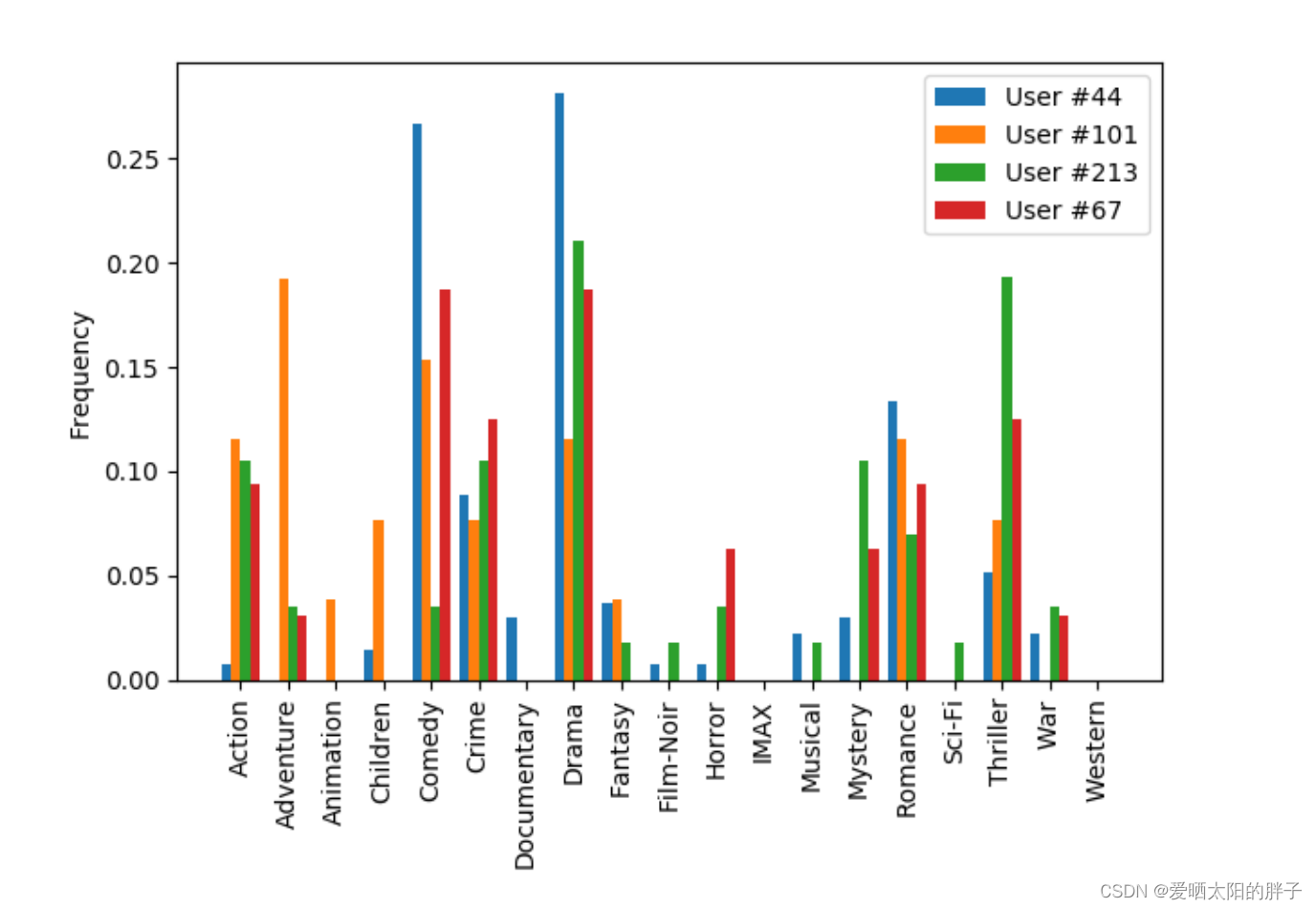
论文没有给出公式,但可以通过给的示例图进行推断
E. Neighbor-Assisted Representation
基于用户的 CF 首先为目标用户查找相似的用户(称为邻居),本文将用户i和k的相似度定义为,根据相似度大小找到前L个最相似的用户,邻居的的嵌入向量集合表示为
用户i的邻居辅助表示计算方式如下:

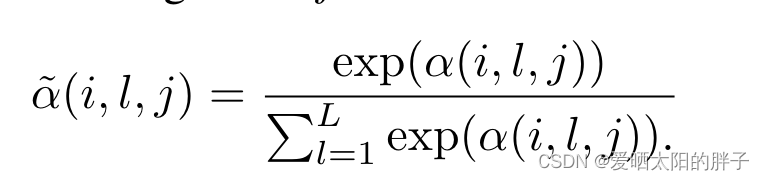
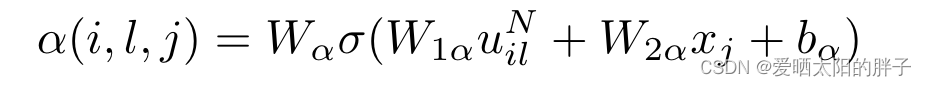
: 与用户i相似度第l大的用户在候选物品为j时的注意力分数
:与用户i相似度第l大的用户的特征向量(初始化为用户的潜在表示)
:候选特征表示
IV. FUSING MULTIPLE USER INTEREST REPRESENTATIONS
下面 此处K=4,分别代表
A. Early Fusion
- Sum fusion

- Max fusion.
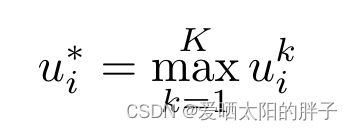
- Feed-forward neural network
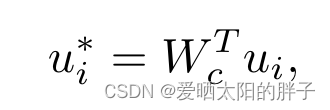
- Attention fusion.
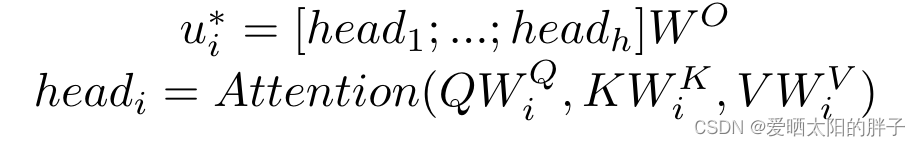

B. Late Fusion
首先将每一种表示向量与候选物品做元素积,
,然后将结果输入MLP 得到
最终结果
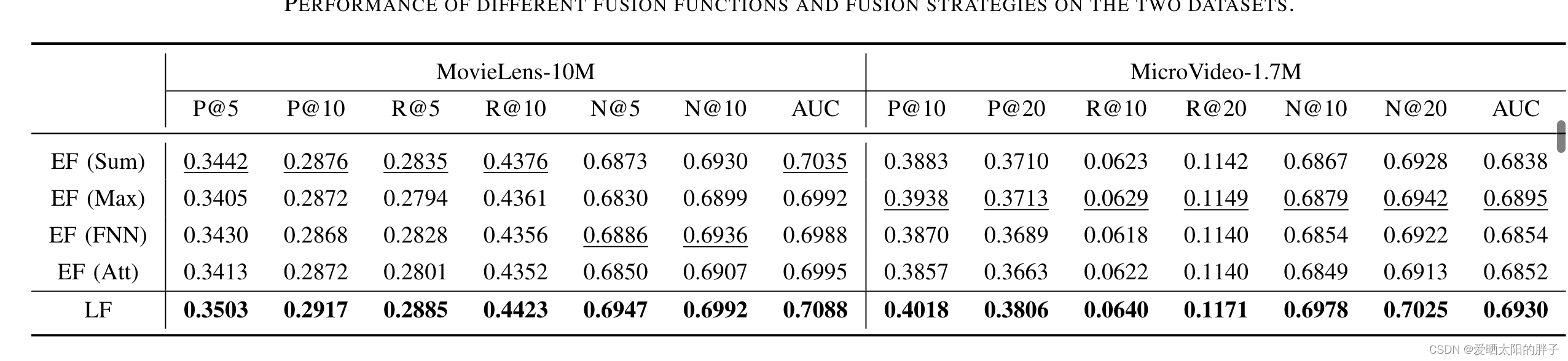
实验效果如下:可发现最复杂的注意力融合方法并不是最有。